Deep Learning Reference Stack Guide
Sysstacks containers have been deprecated and please switch to oneapi based containers, you can find oneapi containers at this link : https://hub.docker.com/u/intel This guide gives basic examples for using the Deep Learning Reference stack to make getting started with DLRS quick. There are also examples of using the stack in real-world usecases, with code and instructions in the GitHub* Usecases Repository.
Overview
We created the Deep Learning Reference Stack to help AI developers deliver the best experience on Intel® Architecture. This stack reduces complexity common with deep learning software components, provides flexibility for customized solutions, and enables you to quickly prototype and deploy Deep Learning workloads. To provide flexibility DLRS is available in multiple versions, including various container OS options.
The latest release of the Deep Learning Reference Stack (DLRS V0.9.1 ) supports the following features:
TensorFlow* 1.15.3 and TensorFlow* 2.4.0, end-to-end open source platforms for machine learning (ML).
TensorFlow Serving 2.4, Deep Learning model serving solution for TensorFlow models.
PyTorch* 1.8, an open source machine learning framework that accelerates the path from research prototyping to production deployment.
PyTorch Lightning* which is a lightweight wrapper for PyTorch designed to help researchers set up all the boilerplate state-of-the-art training.
Transformers* which is a state-of-the-art Natural Language Processing (NLP) library for TensorFlow 2.4 and PyTorch
Flair*, a library for state-of-the-art Natural Language Processing using PyTorch
OpenVINO™ model server, delivering improved neural network performance on Intel processors, helping unlock cost-effective, real-time vision applications.
Horovod a framework for optimized distributed Deep Learning training for TensorFlow and Pytorch.
Intel DL Boost with Vector Neural Network Instruction (VNNI) and Intel AVX-512_BF16 designed to accelerate deep neural network-based algorithms.
Deep Learning Compilers (TVM*), an end-to-end compiler stack.
Mozilla text-to-speech AI engine Deepspeech supported on TensorFlow 2.4.0 based stack.
Important
To take advantage of the Intel® AVX-512 and VNNI functionality (including the oneDNN releases) with the Deep Learning Reference Stack, you must use the following hardware:
Intel® AVX-512 images require an Intel® Xeon® Scalable Platform
VNNI requires a 2nd generation Intel® Xeon® Scalable Platform
Releases
Refer to the System Stacks for Linux* OS repository for information and download links for the different versions and offerings of the stack.
DLRS V0.9.1 release announcement.
DLRS V0.8.0 release announcement.
DLRS V0.7.0 release announcement.
DLRS V0.6.0 release announcement.
DLRS V0.5.0 release announcement.
DLRS V0.4.0 release announcement, including benchmark results.
DLRS Release notes on Github* for the latest release of Deep Learning Reference Stack.
Note
The Deep Learning Reference Stack is a collective work, and each piece of software within the work has its own license. Please see the DLRS Terms of Use for more details about licensing and usage of the Deep Learning Reference Stack.
TensorFlow single and multi-node benchmarks
This section describes running the TensorFlow Benchmarks in single node. For multi-node testing, replicate these steps for each node. These steps provide a template to run other benchmarks, provided that they can invoke TensorFlow.
Note
Performance test results for the Deep Learning Reference Stack and for this guide were obtained using runc as the runtime. Additionally, the examples shown in this guide use the Ubuntu* based version of the DLRS stacks.
Download either the TensorFlow for Ubuntu or the TensorFlow 2 for Ubuntu Docker image from Docker Hub.
Run the image with Docker:
docker run --name <image name> --rm -ti <sysstacks/dlrs-tensorflow-ubuntu> bash
Note
Launching the Docker image with the -i argument starts interactive mode within the container. Enter the following commands in the running container.
Clone the benchmark repository in the container:
git clone http://github.com/tensorflow/benchmarks -b cnn_tf_v1.13_compatible
Execute the benchmark script:
python benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --device=cpu --model=resnet50 --data_format=NHWC
Note
You can replace the model with one of your choice supported by the TensorFlow benchmarks.
If you are using an FP32 based model, it can be converted to an int8 model using Intel® quantization tools.
PyTorch single and multi-node benchmarks
This section describes running the PyTorch benchmarks for Caffe2 in single node.
Download the PyTorch for Ubuntu from Docker Hub.
Run the image with Docker:
docker run --name <image name> --rm -i -t <sysstacks/dlrs-pytorch-ubuntu> bash
Note
Launching the Docker image with the -i argument starts interactive mode within the container. Enter the following commands in the running container.
Clone the benchmark repository:
git clone https://github.com/pytorch/pytorch.git
Execute the benchmark script:
cd pytorch/caffe2/python python convnet_benchmarks.py --batch_size 32 \ --cpu \ --model AlexNet
TensorFlow Training (TFJob) with Kubeflow and DLRS
A TFJob is Kubeflow’s custom resource used to run TensorFlow training jobs on Kubernetes. This example shows how to use a TFJob within the DLRS container.
Pre-requisites:
A running Kubernetes cluster
Deploying Kubeflow with kfctl/kustomize
Note
This example proposes a Kubeflow installation using kfctl. Please download the kfctl tarball to complete the following steps
Download, untar and add to your PATH if necessary
KFCTL_URL="https://github.com/kubeflow/kubeflow/releases/download/v0.6.1/kfctl_v0.6.1_linux.tar.gz" wget -P ${KFCTL_URL} ${KFCTL_PATH} tar -C ${KFCTL_PATH} -xvf ${KFCTL_PATH}/kfctl_v${kfctl_ver}_linux.tar.gz export PATH=$PATH:${KFCTL_PATH}
Install Kubeflow resource and TFJob operators
# Env variables needed for your deployment export KFAPP="<your choice of application directory name>" export CONFIG="https://raw.githubusercontent.com/kubeflow/manifests/master/kfdef/kfctl_k8s_istio.yaml" kfctl init ${KFAPP} --config=${CONFIG} -V cd ${KFAPP} # deploy Kubeflow: kfctl generate k8s -V kfctl apply k8s -V
List the resources
Deployment takes around 15 minutes (or more depending on the hardware) to be ready to use. After that you can use kubectl to list all the Kubeflow resources deployed and monitor their status.
kubectl get pods -n kubeflow
Submitting TFJobs
We provide DLRS TFJob examples that use the Deep Learning Reference Stack as the base image for creating the containers to run training workloads in your Kubernetes cluster.
Customizing a TFJob
A TFJob is a resource with a YAML representation like the one below. Edit to use the DLRS image containing the code to be executed and modify the command for your own training code.
If you’d like to modify the number and type of replicas, resources, persistent volumes and environment variables, please refer to the Kubeflow documentation
apiVersion: kubeflow.org/v1beta2
kind: TFJob
metadata:
generateName: tfjob
namespace: kubeflow
spec:
tfReplicaSpecs:
PS:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: dlrs-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
Worker:
replicas: 3
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: dlrs-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
Master:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: dlrs-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
For more information, please refer to: * Distributed TensorFlow * TFJobs
PyTorch Training (PyTorch Job) with Kubeflow and DLRS
A PyTorch Job is Kubeflow’s custom resource used to run PyTorch training jobs on Kubernetes. This example builds on the framework set up in the previous example.
Pre-requisites:
A running Kubernetes cluster
Submitting PyTorch Jobs
We provide DLRS PytorchJob examples that use the Deep Learning Reference Stack as the base image for creating the container(s) that will run training workloads in your Kubernetes cluster.
Working with Horovod* and OpenMPI*
Horovod is a distributed training framework for TensorFlow, Keras, and PyTorch. The OpenMPI Project is an open source Message Passing Interface implementation. Running Horovod on OpenMPI will let us enable distributed training on DLRS.
The following deployment uses Kubeflow OpenMPI instructions, meaning you can replace the following variables to have a working Kubernetes cluster with openmpi workers for distributed training.
To begin, set up a Kubernetes cluster. You will need to build and push the DLRS docker image with Horovod and OpenMPI enabled, modifying the dockerfile to build your image
Building the Image
DLRS is part of the Intel stacks GitHub repository. Clone the stacks repository.
git clone https://github.com/intel/stacks.git
Create the ssh-entrypoint.sh script by copying the following into a file in the stacks/dlrs/clearlinux/tensorflow/mkl directory
#! /usr/bin/env bash set -o errexit mkdir -p /etc/ssh /var/run/sshd # Allow OpenSSH to talk to containers without asking for confirmation cat << EOF > /etc/ssh/ssh_config StrictHostKeyChecking no Port 2022 UserKnownHostsFile=/dev/null PasswordAuthentication no EOF /usr/sbin/ssh-keygen -A
Inside the stacks/dlrs/clearlinux/tensorflow/mkl directory, modify the Dockerfile.builder file to add the openssh-server to the container.
# update os and add required bundles RUN swupd bundle-add git curl wget \ java-basic sysadmin-basic package-utils \ devpkg-zlib go-basic devpkg-tbb openssh-server
To execute the ssh-entrypoint.sh in the container, add these lines to the Dockerfile.builder file
COPY ssh-entrypoint.sh /bin/ssh-entrypoint.sh RUN chmod +x /bin/ssh-entrypoint.sh RUN ssh-entrypoint.sh
Note
The ssh-entrypoint.sh script will generate ssh host keys for the docker image, but they will be the same every time the image is built.
Build the container with
make
Note
More detail on building the container can be found on the Intel stacks GitHub repository
Using the new image with Horovod and OpenMPI
To use the new image we will follow the Kubeflow OpenMPI instructions. You will not need to follow the Installation section, as we have just completed that for the DLRS container.
Generate and deploy Kubeflow’s openmpi component.
Create a namespace for kubeflow deployment. kubectl delete namespace kubeflow NAMESPACE=kubeflow kubectl create namespace ${NAMESPACE} # Generate one-time ssh keys used by Open MPI. SECRET=openmpi-secret mkdir -p .tmp yes | ssh-keygen -N "" -f .tmp/id_rsa -C "" kubectl delete secret ${SECRET} -n ${NAMESPACE} || true kubectl create secret generic ${SECRET} -n ${NAMESPACE} --from-file=id_rsa=.tmp/id_rsa --from-file=id_rsa.pub=.tmp/id_rsa.pub --from-file=authorized_keys=.tmp/id_rsa.pub # Which version of Kubeflow to use. # For a list of releases refer to: # https://github.com/kubeflow/kubeflow/releases VERSION=master # Initialize a ksonnet app. Set the namespace for its default environment. APP_NAME=openmpi ks init ${APP_NAME} cd ${APP_NAME} ks env set default --namespace ${NAMESPACE} # Install Kubeflow components. ks registry add kubeflow github.com/kubeflow/kubeflow/tree/${VERSION}/kubeflow ks pkg install kubeflow/openmpi@${VERSION} # See the list of supported parameters. # Generate openmpi components. COMPONENT=openmpi IMAGE=<image name>
Run openmpi workers in containers
WORKERS=<set number of workers> MEMORY=<memory> GPU=0 # We should create a hostfile with the names of each node in the k8s cluster EXEC="mpiexec --allow-run-as-root -np ${WORKERS} --hostfile /kubeflow/openmpi/assets/hostfile -bind-to none -map-by slot sh -c 'python <path_to_benchmarks_scripts> --device=cpu --data_format=NHWC --model=alexnet --variable_update=horovod --horovod_device=cpu'" ks generate openmpi ${COMPONENT} --image ${IMAGE} --secret ${SECRET} --workers ${WORKERS} --gpu ${GPU} --exec "${EXEC}" --memory "${MEMORY}" # Deploy to your cluster. ks apply default WORKERS=<set number of workers> MEMORY=<memory> GPU=0 # We should create a hostfile with the names of each node in the k8s cluster EXEC="mpiexec --allow-run-as-root -np ${WORKERS} --hostfile /kubeflow/openmpi/assets/hostfile -bind-to none -map-by slot sh -c 'python <path_to_benchmarks_scripts> --device=cpu --data_format=NHWC --model=alexnet --variable_update=horovod --horovod_device=cpu'" ks generate openmpi ${COMPONENT} --image ${IMAGE} --secret ${SECRET} --workers ${WORKERS} --gpu ${GPU} --exec "${EXEC}" --memory "${MEMORY}" # Deploy to your cluster. ks apply default
Using Transformers* for Natural Language Processing
The DLRS v5.0 release includes Transformers, a state-of-the-art Natural Language Processing (NLP) library for TensorFlow 2.0 and PyTorch. The library is configured to work within the container environment.
In this section we use a Jupyter Notebook from inside the container to walk through one of the notebooks shown in the Transformers repository.
To run the notebook, you will need to run the Deep Learning Reference Stack, mount it to disk and connect a Jupyter Notebook port.
Run the DLRS image with Docker:
docker run -it -v ${PWD}:/workspace -p 8888:8888 clearlinux/stacks-pytorch-mkl:latest
From within the container, navigate to the workspace, and clone the transformers repository in the container:
cd workspace git clone https://gist.github.com/16d38f2c9c688963c166c000330a3c11.gitStart a Jupyter Notebook that is linked to the exterior port. Be sure to copy the token from the output of starting Jupyter Notebook.
pip install jupyter --upgrade jupyter notebook --ip 0.0.0.0 --no-browser --allow-rootTo access the Jupyter Notebook, open a browser.
Return to the Terminal where you launched Jupyter Notebook. Copy one of the URLs that appears after “Or copy and paste on of these URLs.”
Paste the URL (with embedded token) into the browser window.
The notebook will also be available at the URL of the system serving the notebook. For example if you are running on 192.168.1.10, you will be able to access the notebook from other systems on that subnet by navigating to http://192.168.1.10:8888
From the browser, you will see the following notebooks.
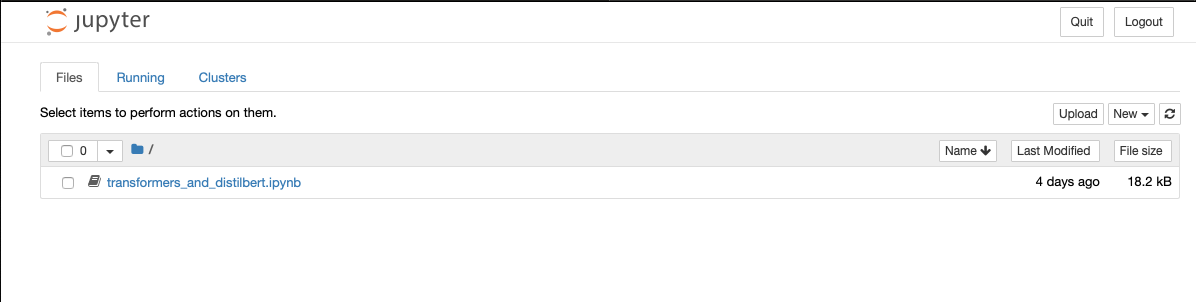
Figure 1: Transformers Jupyter Notebooks
This example along with the other notebooks show how to get up and running with Transformers. More detail on using Transformers* is available through the Transformers github repository.
Using the OpenVINO™ Model Optimizer
. The OpenVINO™ toolkit has two primary tools for deep learning, the inference engine and the model optimizer. The inference engine is integrated into the Deep Learning Reference Stack. It is better to use the model optimizer after training the model, and before inference begins. This example will explain how to use the model optimizer by going through a test case with a pre-trained TensorFlow model.
This example uses resources found in the following OpenVINO™ toolkit documentation.
Converting TensorFlow Object Detection API Models
In this example, you will:
Download a TensorFlow model
Clone the Model Optimizer
Install Prerequisites
Run the Model Optimizer
Download a TensorFlow model
We will be using an OpenVINO™ toolkit supported topology with the Model Optimizer. We will use a TensorFlow Inception V2 frozen model.
Navigate to the OpenVINO TensorFlow Model page. Then scroll down to the second section titled “Supported Frozen Topologies from TensorFlow Object Detection Models Zoo” and download “SSD Inception V2 COCO.”
Unpack the file into your chosen working directory. For example, if the tar file is in your Downloads folder and you have navigated to the directory you want to extract it into, run:
tar -xvf ~/Downloads/ssd_inception_v2_coco_2018_01_28.tar.gz
Clone the Model Optimizer
Next we need the model optimizer directory, named dldt. This example assumes the parent directory is on the same level as the model directory, ie:
+--Working_Directory +-- ssd_inception_v2_coco_2018_01_28 +-- dldt
To clone the Model Optimizer, run this from inside the working directory:
git clone https://github.com/opencv/dldt.git
If you explore the
dldtdirectory, you’ll see both the inference engine and the model optimizer. We are only concerned with the model optimizer at this stage. Navigating into the model optimizer folder you’ll find several python scripts and text files. These are the scripts you call to run the model optimizer.Install Prerequisites for Model Optimizer
Install the Python packages required to run the model optimizer by running the script dldt/model-optimizer/install_prerequisites/install_prerequisites_tf.sh.
cd dldt/model-optimizer/install_prerequisites/ ./install_prerequisites_tf.sh cd ../../..
Run the Model Optimizer
Running the model optimizer is as simple as calling the appropriate script, however there are many configuration options that are explained in the documentation
python dldt/model-optimizer/mo_tf.py \ --input_model=ssd_inception_v2_coco_2018_01_28/frozen_inference_graph.pb \ --tensorflow_use_custom_operations_config dldt/model-optimizer/extensions/front/tf/ssd_v2_support.json \ --tensorflow_object_detection_api_pipeline_config ssd_inception_v2_coco_2018_01_28/pipeline.config \ --reverse_input_channels
You should now see three files in your working directory,
frozen_inference_graph.bin,frozen_inference_graph.mapping, andfrozen_inference_graph.xml. These are your new models in the Intermediate Representation (IR) format and they are ready for use in the OpenVINO™ Inference Engine.
Using the OpenVINO™ toolkit Inference Engine
This example walks through the basic instructions for using the inference engine.
Starting the Model Server
The process is similar to how we start Jupter notebooks on our containers
Run this command to spin up a OpenVINO™ toolkit model fetched from GCP
docker run -p 8000:8000 stacks-dlrs-mkl:latest bash -c ". /workspace/scripts/serve.sh && ie_serving model --model_name resnet --model_path gs://public-artifacts/intelai_public_models/resnet_50_i8 --port 8000"
Once the server is setup, use a grpc client to communicate with served model:
git clone https://github.com/IntelAI/OpenVINO-model-server.git cd OpenVINO-model-server pip install -q -r OpenVINO-model-server/example_client/client_requirements.txt pip install --user -q -r OpenVINO-model-server/example_client/client_requirements.txt cat OpenVINO-model-server/example_client/client_requirements.txt cd OpenVINO-model-server/example_client python jpeg_classification.py --images_list input_images.txt --grpc_address localhost --grpc_port 8000 --input_name data --output_name prob --size 224 --model_name resnet
The results of these commands will look like this:
start processing: Model name: resnet Images list file: input_images.txt images/airliner.jpeg (1, 3, 224, 224) ; data range: 0.0 : 255.0 Processing time: 97.00 ms; speed 2.00 fps 10.35 Detected: 404 Should be: 404 images/arctic-fox.jpeg (1, 3, 224, 224) ; data range: 0.0 : 255.0 Processing time: 16.00 ms; speed 2.00 fps 63.89 Detected: 279 Should be: 279 images/bee.jpeg (1, 3, 224, 224) ; data range: 0.0 : 255.0 Processing time: 14.00 ms; speed 2.00 fps 69.82 Detected: 309 Should be: 309 images/golden_retriever.jpeg (1, 3, 224, 224) ; data range: 0.0 : 255.0 Processing time: 13.00 ms; speed 2.00 fps 75.22 Detected: 207 Should be: 207 images/gorilla.jpeg (1, 3, 224, 224) ; data range: 0.0 : 255.0 Processing time: 11.00 ms; speed 2.00 fps 87.24 Detected: 366 Should be: 366 images/magnetic_compass.jpeg (1, 3, 224, 224) ; data range: 0.0 : 247.0 Processing time: 11.00 ms; speed 2.00 fps 91.07 Detected: 635 Should be: 635 images/peacock.jpeg (1, 3, 224, 224) ; data range: 0.0 : 255.0 Processing time: 9.00 ms; speed 2.00 fps 110.1 Detected: 84 Should be: 84 images/pelican.jpeg (1, 3, 224, 224) ; data range: 0.0 : 255.0 Processing time: 10.00 ms; speed 2.00 fps 103.63 Detected: 144 Should be: 144 images/snail.jpeg (1, 3, 224, 224) ; data range: 0.0 : 248.0 Processing time: 10.00 ms; speed 2.00 fps 104.33 Detected: 113 Should be: 113 images/zebra.jpeg (1, 3, 224, 224) ; data range: 0.0 : 255.0 Processing time: 12.00 ms; speed 2.00 fps 83.04 Detected: 340 Should be: 340 Overall accuracy= 100.0 % Average latency= 19.8 ms
Using Seldon and OpenVINO™ model server with the Deep Learning Reference Stack
Seldon Core is an open source platform for deploying machine learning models on a Kubernetes cluster. In this section we will walk through using a Seldon server with OpenVINO™ model server.
Pre-requisites
A running Kubernetes cluster.
An existing Kubeflow deployment
Helm
A pre-trained model
Please refer to:
Note
This document was validated with Kubernetes v1.14.8, Kubeflow v0.7, and Helm v3.0.1
Prepare the model
There are several methods to add a model to a Seldon server; we will cover two of them. First a model will be stored in a persistent volume by creating a persistent volume claim and a pod, then copying the model into the pod. Second, a model will be built directly into the base image. Adding a model to a volume is perhaps more traditional in Kubernetes, but some cloud providers have access rules that disallow a private cluster, and adding the model to the image avoids the issue in that scenario.
Mount pre-trained models into a persistent volume
We will create a small pod to get the model into a volume.
Apply all PV manifests to the cluster
kubectl apply -f storage/pv-volume.yaml kubectl apply -f storage/model-store-pvc.yaml kubectl apply -f storage/pv-pod.yaml
Use kubectl cp to move the model into the pod, and therefore into the volume
kubectl cp ./<your model file> pv-pod:/home
In the running container, fetch your pre-trained models and save them in the
/opt/mldirectory path.root@hostpath-pvc:/# cd /opt/ml root@hostpath-pvc:/# # Copy your models here root@hostpath-pvc:/# # exit
Add the pre-trained model to the image
A custom DLRS image is provided to serve OpenVINO™ model server through Seldon. Add a curl command to download your publicly hosted model and save it in /opt/ml in the container filesystem. For example, if you have a model on GCP, use this command:
curl -o "[SAVE_TO_LOCATION]" \ "https://storage.googleapis.com/storage/v1/b/[BUCKET_NAME]/o/[OBJECT_NAME]?alt=media"
Prepare the DLRS image
A base image with Seldon and the OpenVINO™ inference engine should be created using the Dockerfile_openvino_base dockerfile.
cd docker docker build -f Dockerfile_openvino_base -t dlrs_openvino_base . cd ..
Deploy the model server
Now you’re ready to deploy the model server using the Helm chart provided.
cd helm helm install dlrs-seldon seldon-model-server \ --namespace kubeflow \ --set openvino.image=dlrs_openvino_base \ --set openvino.model.path=/opt/ml \ --set openvino.model.name=<model_name> \ --set openvino.model.input=data \ --set openvino.model.output=prob
This will create your SeldonDeployment
Extended example with Seldon using Source to Image
Source to Image (s2i) is a tool to create docker images from source code.
Install source to image (s2i)
cd ${SRC-DIR} wget https://github.com/openshift/source-to-image/releases/download/v1.1.14/source-to-image-v1.1.14-874754de-linux-amd64.tar.gz tar xf source-to-image-v1.1.14-874754de-linux-amd64.tar.gz mv s2i ${BIN_DIR}/s2i && ln -s s2i ${BIN_DIR}/sti
Clone the seldon-core repository
git clone https://github.com/SeldonIO/seldon-core.git ${SRC_DIR}/seldon-core
Create the new image
Using the DLRS image created above, you can build another image for deploying the Image Transformer component that consumes imagenet classificatin models.
cd ${SRC_DIR}/seldon-core/examples/models/openvino_imagenet_ensemble/resources/transformer/ s2i -E environment_grpc . dlrs_openvino_base:0.1 imagenet_transformer:0.1
Use this newly created image for deploying the Image Transformer component of the OpenVino Imagenet Pipelines example from Seldon.
Use Jupyter Notebook
This example uses the PyTorch for Ubuntu container image. After it is downloaded, run the Docker image with -p to specify the shared port between the container and the host. This example uses port 8888.
docker run --name pytorchtest --rm -i -t -p 8888:8888 clearlinux/stacks-pytorch-oss bash
After you start the container, launch the Jupyter Notebook. This command is executed inside the container image.
jupyter notebook --ip 0.0.0.0 --no-browser --allow-root
After the notebook has loaded, you will see output similar to the following:
To access the notebook, open this file in a browser: file:///.local/share/jupyter/runtime/nbserver-16-open.html
Or copy and paste one of these URLs:
http://(846e526765e3 or 127.0.0.1):8888/?token=6357dbd072bea7287c5f0b85d31d70df344f5d8843fbfa09
From your host system, or any system that can access the host’s IP address, start a web browser with the following. If you are not running the browser on the host system, replace 127.0.0.1 with the IP address of the host.
http://127.0.0.1:8888/?token=6357dbd072bea7287c5f0b85d31d70df344f5d8843fbfa09
Your browser displays the following:
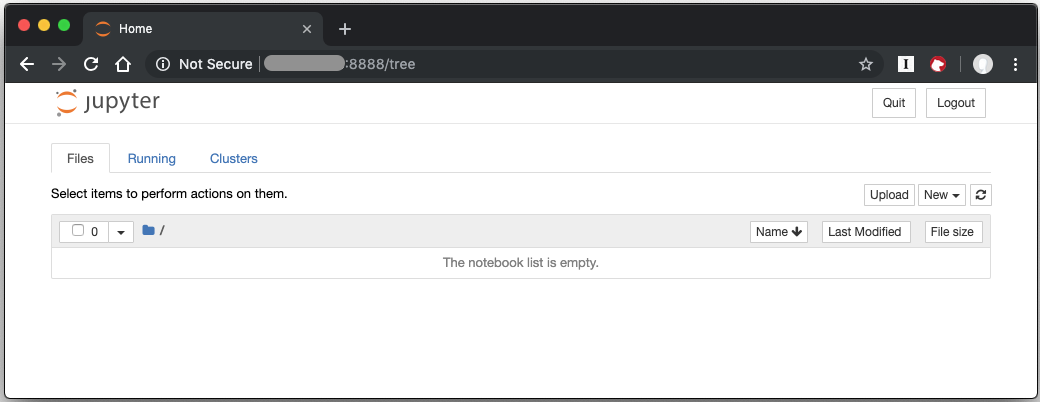
Figure 1: Jupyter Notebook
To create a new notebook, click New and select Python 3.
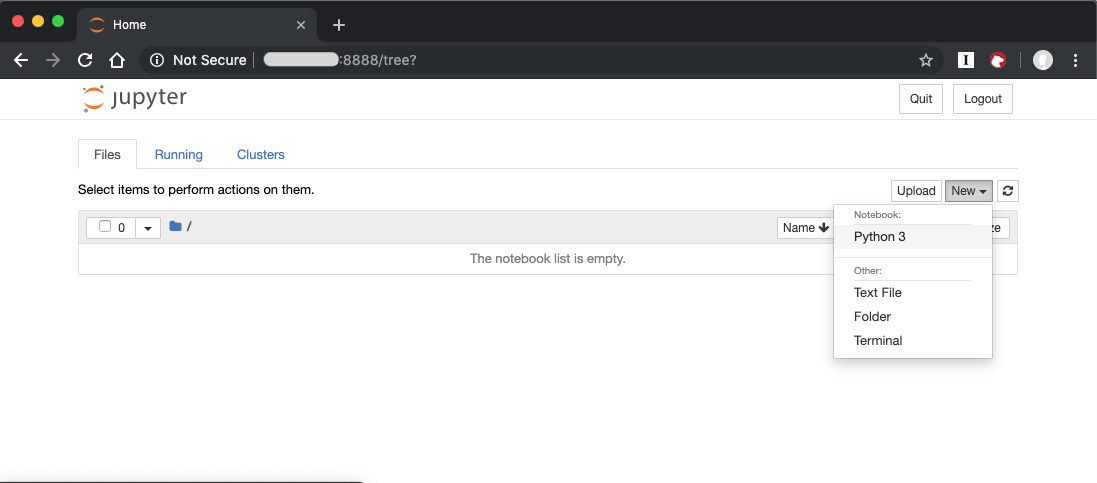
Figure 2: Create a new notebook
A new, blank notebook is displayed, with a cell ready for input.
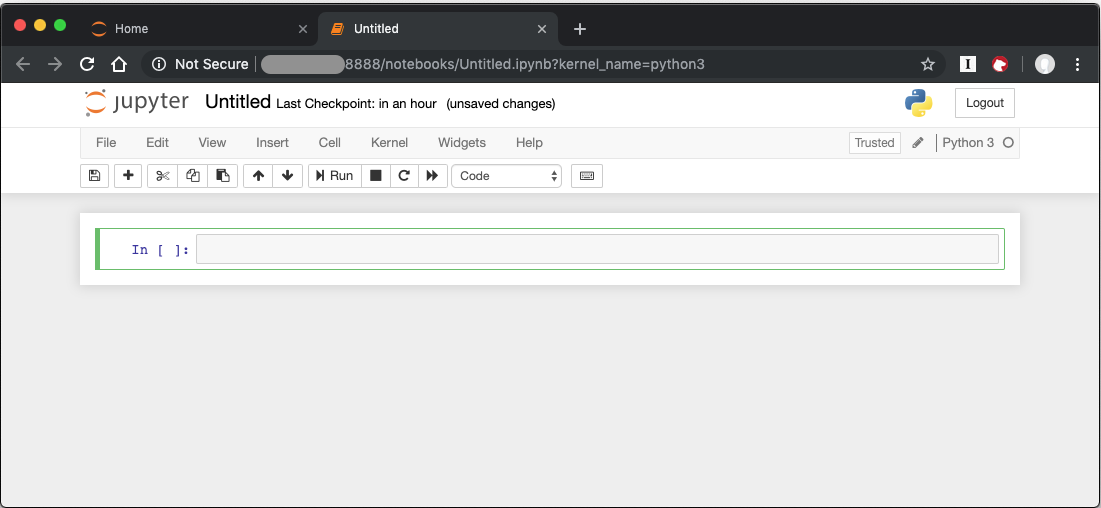
Figure 3: New blank notebook
To verify that PyTorch is working, copy the following snippet into the blank cell, and run the cell.
from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
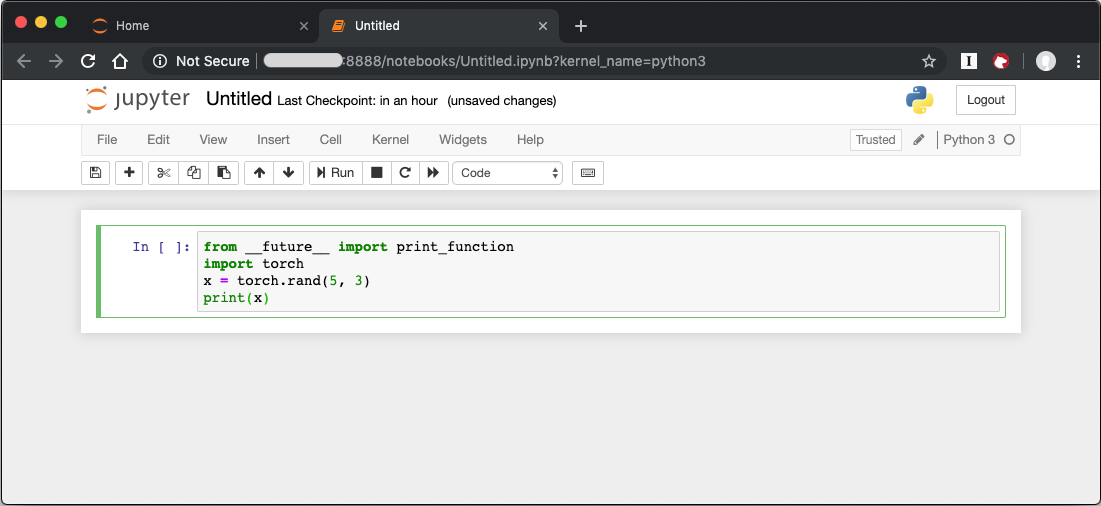
Figure 4: Sample code snippet
When you run the cell, your output will look something like this:
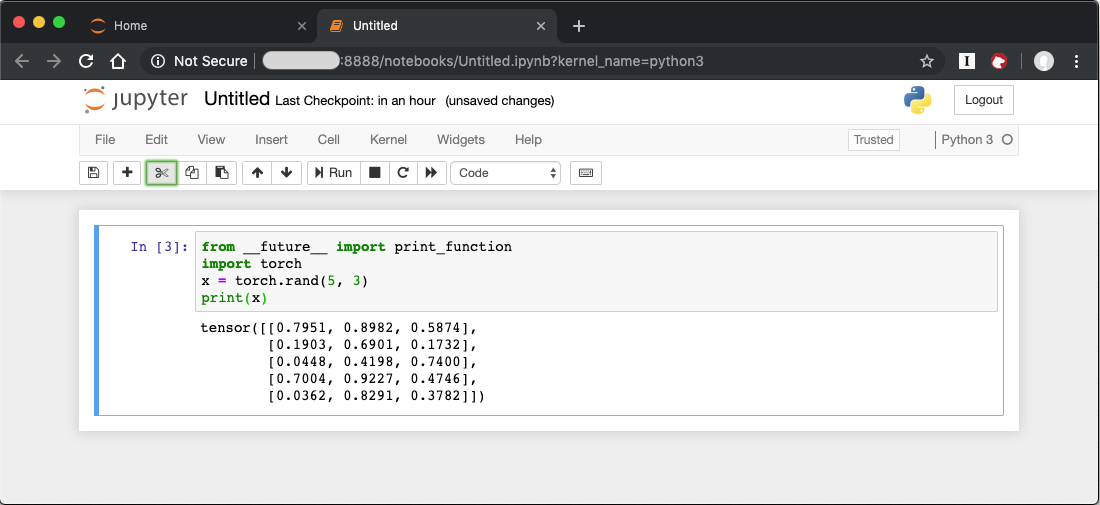
Figure 5: Code output
You can continue working in this notebook, or you can download existing notebooks to take advantage of the Deep Learning Reference Stack’s optimized deep learning frameworks. Refer to Jupyter Notebook for details.
Uninstallation
To uninstall the Deep Learning Reference Stack, you can choose to stop the container so that it is not using system resources, or you can stop the container and delete it to free storage space.
To stop the container, execute the following from your host system:
Find the container’s ID
docker container ls
This will result in output similar to the following:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e131dc71d339 sysstacks/dlrs-tensorflow-clearlinux "/bin/sh -c 'bash'" 23 seconds ago Up 21 seconds oss
You can then use the ID or container name to stop the container. This example uses the name “oss”:
docker container stop oss
Verify that the container is not running
docker container ls
To delete the container from your system you need to know the Image ID:
docker images
This command results in output similar to the following:
REPOSITORY TAG IMAGE ID CREATED SIZE sysstacks/dlrs-tensorflow-clearlinux latest 82757ec1648a 4 weeks ago 3.43GB sysstacks/dlrs-tensorflow-clearlinux latest 61c178102228 4 weeks ago 2.76GB
To remove an image use the image ID:
docker rmi 82757ec1648a
# docker rmi 827 Untagged: sysstacks/dlrs-tensorflow-clearlinux:latest Untagged: sysstacks/dlrs-tensorflow-clearlinux@sha256:381f4b604537b2cb7fb5b583a8a847a50c4ed776f8e677e2354932eb82f18898 Deleted: sha256:82757ec1648a906c504e50e43df74ad5fc333deee043dbfe6559c86908fac15e Deleted: sha256:e47ecc039d48409b1c62e5ba874921d7f640243a4c3115bb41b3e1009ecb48e4 Deleted: sha256:50c212235d3c33a3c035e586ff14359d03895c7bc701bb5dfd62dbe0e91fb486
Note that you can execute the docker rmi command using only the first few characters of the image ID, provided they are unique on the system.
Once you have removed the image, you can verify it has been deleted with:
docker images
Compiling AIXPRT with OpenMP on DLRS
To compile AIXPRT for DLRS, you will have to get the community edition of AIXPRT and update the compile_AIXPRT_source.sh file.AIXPRT utilizes build configuration files, so to build AIXPRT on the image, copy, the build files from the base image, this can be done by adding these commands to the end of the stacks-dlrs-mkl dockerfile:
COPY --from=base /dldt/inference-engine/bin/intel64/Release/ /usr/local/lib/openvino/tools/ COPY --from=base /dldt/ /dldt/ COPY ./airxprt/ /workspace/aixprt/ RUN ./aixprt/install_deps.sh RUN ./aixprt/install_aixprt.sh
AIXPRT requires OpenCV. On Clear Linux* OS, for example, the OpenCV bundle also installs the DLDT components. To use AIXPRT in the DLRS environment you need to either remove the shared libraries for DLDT from /usr/lib64 before you run the tests, or ensure that the DLDT components in the /usr/local/lib are being used for AIXPRT. This can be achieved using adding LD_LIBRARY_PATH environment variable before testing.
export LD_LIBRARY_PATH=/usr/local/lib
The updates to the AIXPRT community edition have been captured in the diff file compile_AIXPRT_source.sh.patch. The core of these changes relate to the version of model files(2019_R1) we download from the OpenCV open model zoo and location of the build files, which in our case is /dldt. Please refer to the patch files and make changes as necessary to the compile_AIXPRT_source.sh file as required for your environment.
Using the Intel® VTune™ Profiler with DLRS Containers
Intel® VTune™ Profiler allows you to profile applications running in Docker containers, including profiling multiple containers simultaneously. More information about VTune Profiler is available at software.intel.com
Prerequisites
This section of the tutorial assumes the following prerequisites are met
Intel VTune Profiler 2020
Linux* container runtime: docker.io
Operating System on host: Ubuntu* or CentOS with Linux kernel version 4.10 or newer
Intel® microarchitecture code named Skylake with 8 logical CPUs
Pull the image onto the VTune enabled system:
docker pull sysstacks/dlrs-pytorch-ubuntu
Run the container and keep it running with the -t and -d options
docker run --name <image name> -td <dlrs-pytorch-ubuntu>
Find the container ID with the docker ps command
host> docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 98fec14f0c08 dlrs_test "/bin/bash" 10 seconds ago Up 9 seconds
Use the container ID to ensure bash is running in the background
docker exec -it 98fec14f0c08 /bin/bash
Use VTune to collect and analyze data
Launch the VTune Profiler on the host, for example:
host> cd /opt/intel/vtune_profiler host> source ./vtune-vars.sh host> vtune-gui
Create a project for your analysis in VTune, for example: python-benchmark
Run an application within the DLRS container
For example, run the python benchmarks as shown above
On the Configure Analysis tab in VTune, configure the following options:
On the WHAT pane, select the Profile System target type
Select the Hardware Event-Based Sampling mode
On the HOW pane, enable stack collection
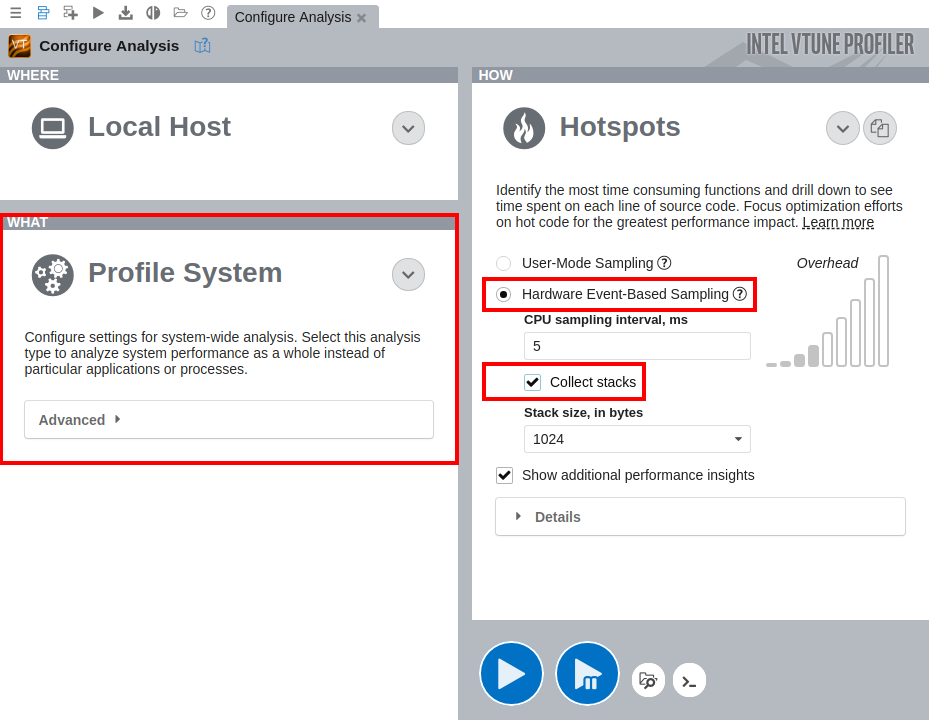
Figure 1: Intel VTune Profiler screenshot
Click Start to run the analysis.
You can also profile Docker containers using the Attach to Process target type, but you will only be able to profile a single container at a time.
For more information on Intel VTune Profiler capabilites, refer to the Intel® VTune™ Profiler Performance Analysis Cookbook