Data Compression
Compression Features
Deflate Compression Algorithm.
LZ77 and Huffman Encoding.
LZ4/LZ4s Compression Algorithm.
Compress and Verify.
Checksums.
Programmable CRC64.
accumulateXXHash.
Compression Limitations
Stateful compression is not supported.
Stateful decompression is not supported on QAT2.0 hardware devices.
Batch and Pack (BnP) compression is not supported.
accumulateXXHash is not supported when combined with autoSelectBestHuffmanTree
accumulateXXHash is not supported in Decompression or Combined sessions
Precompiled Huffman mode is not supported.
Compression Session Setup
The following table lists the properties that should be configured in the CpaDcSessionSetupData structure depending on the compression algorithm requested.
Property |
Details |
|---|---|
|
Properties common to all algorithms |
|
|
|
|
|
|
|
|
|
|
|
|
|
Deflate specific.
|
|
LZ4 specific |
|
|
|
|
|
|
|
LZ4s specific |
Note
Should the application use no-session API cpaDcNsCompressData(), the properties listed above are available in the CpaDcNsSetupData data structure.
Note
In this codebase, capability reporting is aligned with the limitations above:
CpaDcInstanceCapabilities.precompiledHuffman and
CpaDcInstanceCapabilities.batchAndPack are reported as unsupported.
Decompression Session Setup
The following table lists the properties that should be configured in the CpaDcSessionSetupData structure depending on the format of the payload to decompression.
Property |
Deflate |
LZ4 |
|---|---|---|
|
Yes |
Yes |
|
Yes |
Yes |
|
Yes |
Yes |
|
Yes |
Yes |
|
Yes |
Yes |
Deflate Decompression
With deflate based format such as Gzip the application is required to skip the GZip header and present to Intel® QAT the first byte of the deflate block.
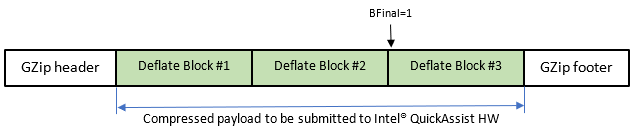
When the Deflate Block #3 is processed, the property endOfLastBlock in the CpaDcRqResults structure will be set to CPA_TRUE. This notifies the application that no more data can be decompressed from the current deflate stream.
The endOfLastBlock capability is not limited to stateful decompression. It can also be used with stateless decompression, including checksum-seeded request chaining (sometimes referred to as stateful-lite), where the checksum from one packet is fed into the next packet.
Support for this behavior is reported through CpaDcInstanceCapabilities.endOfLastBlock when querying capabilities with cpaDcQueryCapabilities().
For applications handling multi-gzip data, both the current Gzip footer and the next Gzip header must be skipped before submitting the next deflate member.
LZ4 Decompression
When decompressing LZ4 frames, the application is required to parse the frame header to extract B.Checksum flag. This flag is used to set the configuration parameter lz4BlockChecksum in CpaDcSessionSetupData. When decompressing LZ4 frames, the application should not include the frame header nor the frame footer in the source buffer to be processed by Intel® QAT hardware.

Note
In decompression direction, the property endOfLastBlock removes the need for the application to know where the last block ends. The QAT hardware will stop after processing the last block. This applies to both GZIP and LZ4 formats.
LZ4 Decompression Limitations
When decompressing LZ4 data compressed without Intel® QAT hardware, it is important to ensure that the compressor limits the history buffer to 32KB. Data compressed using a history buffer larger than 32KB will result with a CPA_DC_INVALID_DIST (-10) error code.
Multi-frame decompression support
Intel® QAT hardware can decompress a payload that includes multiple frames. This applies to both Gzip and LZ4 formats. The figure below shows how the application must behave to decompress LZ4 multi frame payloads.

Performance Considerations
To enable the application benefiting from the QAT2.0 HW maximal performance, it is recommended to populate all the DIMMs around the CPU sockets in use.
Flush Flags
The table below shows the flush flags that should be used depending on the application’s use case. The application programming model should follow this table.
Algorithm |
Use Case |
Intermediate Request |
Last Request |
|---|---|---|---|
Deflate |
Stateless compression |
|
|
Stateless decompression |
|
||
Stateful decompression (QAT1.X devices only) |
|
|
|
LZ4 |
Stateless compression with accumulateXxHash = CPA_FALSE |
|
|
Stateless compression with accumulateXxHash = CPA_TRUE |
|
|
|
Stateless decompression |
|
|
|
LZ4s |
Stateless compression |
|
|
Note
QAT1.X hardware devices still support stateful decompression operations. QAT2.0 hardware device only supports stateless operations.
Checksums
With the addition of LZ4 algorithm support on QAT2.0, the compression hardware accelerators are now capable to generate XXHash32 checksums. QAT2.0 device is now supporting the following checksums:
Checksum Type |
Usage |
|---|---|
CRC32 |
Required for GZip support |
Adler32 |
Required for Zlib support |
CRC32 + Adler32 |
Use when the application requires both checksum values from the same data stream. |
XXHash32 |
Required for LZ4 support |
Note
CPA_DC_CRC32_ADLER32 is accepted by DEFLATE session setup. Dual checksum outputs are explicitly defined for
chaining APIs (CpaDcChainRqResults.crc32 and .adler32). For non-chaining APIs, CpaDcRqResults exposes a single
checksum field; obtaining both CRC32 and Adler32 requires using the integrity CRC data path (CpaCrcData) on
supported configurations.
In the event the XXHash32 checksum should be reset, it must be done calling the API cpaDcResetXXHashState().
LZ4s Compressed Data Block format
LZ4s is a variant of LZ4 block format. LZ4s should be considered as an intermediate compressed block format. The LZ4s format is selected when the application sets the compType to CPA_DC_LZ4S in CpaDcSessionSetupData.
The LZ4s block returned by the Intel® QAT hardware can be used by an external software post-processing to generate other compressed data formats.
The following table lists the differences between LZ4 and LZ4s block format. LZ4s block format uses the same high-level formatting as LZ4 block format with the following encoding changes:
Feature |
LZ4 |
LZ4s |
|---|---|---|
Sequence Header |
4-bit copy length 4-bit literal length |
Same as LZ4 |
Copy Length |
Length 4-19 bytes (encoding values 0-15), 19 bytes adds an extra byte with value 0x00. |
Copy length value of 0 means no copy with this sequence. For Min Match of 3 bytes, Copy length value 1-15 means length 3-17 with 17 bytes adding an extra byte with value 0x00. For Min Match of 4 bytes, Copy length value 1-15 means length 4-18 with 18 bytes adding an extra byte with value 0x00. |
Note
LZ4 requires a copy/token in every sequence, except the last sequence.
The last sequence in block does not contain a copy in both LZ4 and LZ4s.
LZ4s encoding creates a single block of compressed data per request. This is different from LZ4 which creates multiple blocks defined by the LZ4 max block size setting. An LZ4s block is only made of LZ4s sequences.
A sequence in LZ4s can contain:
Only a token.
Only literals.
A token and literals.
Any of the sequence types can exist anywhere in the LZ4s block. The last LZ4s sequence in the LZ4s block shall satisfy the end-of-block restrictions outlined in the LZ4 specification.
LZ4 Compression Support
With the QAT 2.0 API, the application can create LZ4 frames. This is achieved using APIs cpaDcGenerateHeader() and cpaDcGenerateFooter(). These APIs are also able to generate GZip and Zlib formats. More information is available in the API reference manual.
Important
cpaDcGenerateHeader() and cpaDcGenerateFooter() support both stateless and
stateful sessions. They are not limited to stateful compression.
The cpaDcGenerateHeader() creates a 7 byte LZ4 frame header which includes:
Magic number 0x184D2204.
The LZ4 max block size defined in the
CpaDcSessionSetupData.Flag byte as:
Version = 1
Block independence = 0
Block checksum = 0
Content size present = 0
Content checksum present = 1
Dictionary ID present = 0
Content size = 0
Dictionary ID = 0
Header checksum = 1 byte representing the second byte of the XXH32 of the frame descriptor field.
The cpaDcGenerateFooter() API must be used after processing all the requests. This API must be called last to append the frame footer. The cpaDcGenerateFooter() API creates an 8 byte frame footer adding both the end marker (4 bytes set to 0x00) and the XXHash32 checksum computed by Intel® QAT hardware.
Compress-and-Verify
The Compress and Verify (CnV) feature checks and ensures data integrity in the compression operation of the Data Compression API. This feature introduces an independent capability to verify the compression transformation.
Refer to Intel® QuickAssist Technology Data Compression API Reference Manual.
Note
CnV is always enabled via the compression APIs (
cpaDcCompressData(),cpaDcCompressData2(),cpaDcNsCompressData(),cpaDcDpEnqueueOp()).CnV supports compression operations only.
The
compressAndVerifyflag in theCpaDcDpOpDatastructure should be set toCPA_TRUEwhen using thecpaDcDpEnqueueOp()orcpaDcDpEnqueueOpBatch()API.
Compress and Verify Error log in Sysfs
The implementation of the Compress and Verify solution keeps a record of the CnV errors that have occurred since the driver was loaded. The error count is provided on a per Acceleration Engine basis.
/sys/kernel/debug/qat_<qat_device>_<Bus>\:<device>.<function>/cnv_errors.Each Acceleration Engine keeps a count of the CnV errors. The CnV error counter is reset when the driver is loaded. The tool also reports the last error type that caused a CnV error.
Compress and Verify and Recover (CnVnR)
The Compress and Verify and Recover (CnVnR) feature allows a compression error to be recovered in a seamless manner. It is supported in both the Traditional and in the Data Plane APIs.
The CnVnR feature is an enhancement of the Compress and Verify (CnV) solution. When a compress and verify error is detected, the Intel® QAT software will do a correction without returning a CnV error to the application.
When a recovery occurs, CpaDcRqResults.status will return CPA_DC_OK or CPA_DC_OVERFLOW and the destination buffer will hold valid deflate data.
The application can find out if CnVnR is supported by querying the instance capabilities via the cpaDcQueryCapabilities API. On completion, the
compressAndVerifyAndRecover property of the CpaDcInstanceCapabilities structure will be set to CPA_TRUE if the feature is supported.
API |
CnVnR Behavior |
|---|---|
|
Enabled by default, no option to disable. |
|
CnVnR is enabled when |
|
CnVnR is enabled by default. |
|
Not applicable |
|
Not applicable |
|
Not applicable |
|
CnVnR is enabled when |
|
CnVnR is enabled when |
When a CnV recovery takes place, the Intel® QAT software creates a stored block out of the input payload that could not be compressed. The maximal size of a stored block allowed by the deflate standard is 65,535 bytes.

When a stored block is created, the DEFLATE header specifies that the data is uncompressed so that the decompressor does not attempt to decode the cleartext data that follows the header. The size of a stored block can be defined as: Stored block size = Source buffer size + 5 Bytes (used for the deflate header).
The recovery behaves differently on QAT2.0 than on QAT1.X devices. With QAT1.X devices, the recovery creates only one stored block, If the stored block size exceeds 65,535 bytes, the Intel® QAT solution creates one stored block of 65,535 bytes and CpaDcRqResults.status returns CPA_DC_OVERFLOW.
On QAT2.0 device, when the recovery takes place, multiple stored blocks are created. This improvement was added to avoid the application having to handle the overflow.
CnV Recovery with LZ4 compression
When LZ4 compression is used, QAT software will generate an uncompressed LZ4 block in the event of a recovery. The LZ4 uncompressed block will have bit <31> set in the block header followed by the cleartext in the data section of the block.
CnV Recovery with LZ4s compression
LZ4s algorithm is an Intel® specific format. LZ4s payloads do not have a block header like LZ4. When a CnV recovery occurs, the source data will be copied to the destination and dataUncompressed property will be set to CPA_TRUE in CpaDcRqResults structure.
Counting Recovered Compression Errors
The Intel® QAT API has been updated to allow the application to track recovered compression errors. The CpaDcStats data structure has a new property called numCompCnvErrorsRecovered
that is incremented every time a compression recovery happens.
The compression recovery process is agnostic to the application.
CpaDcRqResults.status returns CPA_DC_OK when a compression recovery takes place. The only way to know if a compression recovery took place on the current request is to call the cpaDcGetStats() API and to monitor CpaDcStats.numCompCnvErrorsRecovered.
Dynamic Compression
Dynamic compression involves feeding the data produced by the compression hardware block to the translator hardware block.

When the application selects the Huffman type to CPA_DC_HT_FULL_DYNAMIC in the session and auto-select best feature is set to CPA_DC_ASB_DISABLED, the compression service may not always produce
a deflate stream with dynamic Huffman trees.
When using QAT2.0 device, it is no longer required to allocate intermediate buffers. The API cpaDcGetNumIntermediateBuffers() returns 0. As a good programming practice, the application should still call cpaDcGetNumIntermediateBuffers() and ensure that the number of intermediate buffers returned is 0.
Maximum Expansion with Auto Select Best Feature (ASB)
Compressing some input data may lead to a lower-than-expected compression ratio. This is because the input data may not be very compressible. To achieve a maximum compression ratio, the acceleration unit provides an auto select best (ASB) feature.
With QAT1.X devices, the Intel® QuickAssist Technology hardware will first execute static compression followed by dynamic compression and then select the output that yields the best compression ratio.
With QAT2.0 devices, the is different. ASB features chooses between a static and a stored block. ASB features with choose the block type that offers the best compression ratio.
Regardless of the ASB setting selected, dynamic compression will only be attempted if the session is configured for dynamic compression.
Setting |
Description |
|---|---|
|
ASB mode is disabled. |
|
ASB mode is enabled. |
Note
Setting ASB mode to
CPA_DC_ASB_ENABLED, corresponds to the settingCPA_DC_ASB_UNCOMP_STATIC_DYNAMIC_WITH_STORED_HDRS.These ASB modes have been deprecated:
CPA_DC_ASB_STATIC_DYNAMICCPA_DC_ASB_UNCOMP_STATIC_DYNAMIC_WITH_STORED_HDRSCPA_DC_ASB_UNCOMP_STATIC_DYNAMIC_WITH_NO_HDRS
Based on the ASB settings, the produced data returned in the
CpaDcRqResultsstructure will vary.
Maximum Compression Expansion
To facilitate the programming model of the application, Intel® added a new set of APIs that return the size of the destination according to the algorithm used.
These APIs are:
cpaDcDeflateCompressBound()cpaDcLZ4CompressBound()cpaDcLZ4SCompressBound()
This new set of APIs will return to the application the size of the destination buffer that must be allocated to avoid an overflow exception. Each function initializes the outputSize parameter. The outputSize parameter takes into account the maximal expansion that the compressed data size can reach.
The returned outputSize value must be used both to allocate the size of the pData and to initialize the dataLenInBytes in the CpaBufferList structure.
Note
Each one of the compressBound() APIs accepts as a parameter the instance handle. The instance handle is used internally by the library to determine on which hardware version the instance lives on. The size of the destination buffer to be allocated depends on the hardware generation the instance lives on.
No Session API
The no session API is a simplification of the existing compression and decompression APIs that does not require the application to create/remove a session. Instead the parameters that would normally be set when creating a session are passed into the compress/decompress APIs via a CpaDcNsSetupData structure.
The no session API is especially useful to simplify existing applications as sessions no longer need to be created/tracked/removed. The no session API can be thought of as a “one shot” API and is intended for use cases where all the data to be compressed or decompressed for the current job is being submitted as one request. In addition to the simpler protocol, the API has a smaller memory footprint.
The no session API consists of the following API calls:
cpaDcNsCompressData()cpaDcNsDecompressData()cpaDcNsGenerateHeader()cpaDcNsGenerateFooter()
The cpaDcNsCompressData() and cpaDcNsDecompressData() functions are very similar to the cpaDcCompressData2() and cpaDcDecompressData2() functions. Instead of passing in a CpaDcSessionHandle, a CpaDcNsSetupData structure and a CpaDcCallbackFn are passed in. The CpaDcCallbackFn is the user callback to be called on request completion when running asynchronously. For synchronous operation CpaDcCallbackFn must be set to NULL.
The no session API will work with all versions of QAT hardware but does not support stateful operation as without a session no state can be maintained between requests.
It is still possible to seed checksums for CRC32 and Adler32 by setting the checksum field of the CpaDcRqResults to the seed checksum value before submission. This will allow an overall checksum to be maintained across multiple submissions. For LZ4, checksum seeding is not supported. If checksums need to be maintained between LZ4 requests then the session based API must be used. The no session API supports data integrity checksums but as stateful operation is not supported the integrity checksums will always be for the current request only.
The no session API does support stateless overflow in the compression direction only like the session based API. In that case consumed, produced and checksum fields within the CpaDcRqResults structure will be valid when a status of CPA_DC_OVERFLOW is returned. It is the application’s responsibility to arrange data buffers for the next submission, ensure the checksum is seeded and maintain an overall count of the bytes consumed if footer generation is required. For performance reasons it is recommended that the compressBound API is used to size the destination buffer correctly to avoid overflow. It is necessary for an application to seed the checksum whether it wishes to continue the series of requests or to start a new one, only in the latter case, the seed is 0 for CRC32 and 1 for Adler32.
The no session API does not support setting the sessDirection field of the CpaDcNsSetupData structure to CPA_DC_DIR_COMBINED. In addition, it does not support setting the sessState field to CPA_DC_STATEFUL, or the flushFlag field of the CpaDcOpData structure to CPA_DC_FLUSH_NONE or CPA_DC_FLUSH_SYNC.
The cpaDcNsGenerateHeader() and cpaDcNsGenerateFooter() functions are also very similar to the session based equivalents but take a CpaDcNsSetupData instead of a CpaDcSessionHandle. For cpaDcNsGenerateFooter() an additional parameter is required called count that contains the overall length of the uncompressed input data. For most cases this will be the consumed value from the single submission contained in the CpaDcRqResults structure but in cases where multiple submissions represent the overall file then it is the application’s responsibility to maintain the overall count of consumed bytes.
Compression Levels
Level |
lvl_enum |
QAT 2.0 (Deflate, iLZ77, LZ4, LZ4s) |
QAT 1.7/1.8 (Deflate) |
|---|---|---|---|
1 |
|
2 ( |
|
2 |
|
|
|
3 |
|
|
|
4 |
|
|
|
5 |
|
||
6 |
|
8 ( |
|
7 |
|
||
8 |
|
||
9 |
|
16 ( |
|
10 |
|
Unsupported. Will be rejected at the API. |
|
11 |
|
||
12 |
|
||
> 12 |
Unsupported. Will be rejected at the API. |
Compression Status Codes
The CpaDcRqResults structure should be checked for compression status
codes in the CpaDcReqStatus data field. The mapping of the error codes
to the enums is included in the quickassist/include/dc/cpa_dc.h file.
Intel® QuickAssist Technology Compression API Errors
The Intel® QuickAssist Technology Compression APIs that send requests to the compression hardware can return the error codes shown in Compression API Errors.
These APIs are:
cpaDcCompressData()cpaDcCompressData2()cpaDcNsCompressData()cpaDcDecompressData()cpaDcDecompressData2()cpaDcNsDecompressData()cpaDcDpEnqueueOp()cpaDcDpEnqueueOpBatch()
Note
Decompression issues in may also apply to the compression
use case due to potential issues encountered during a
Compress-and-Verify operation. In this case, the file(s)
/sys/kernel/debug/qat_*/cnv_errors may show these nested errors. In
some cases, the suggested corrective action may need to be to store
the block uncompressed or to compress the block with software.
Compression API Errors
Error Code |
Error Type |
Description |
Suggested Corrective Action(s) |
|---|---|---|---|
0 |
|
No error detected by compression hardware. |
None. |
-1 |
|
Invalid block type (type = 3); invalid input stream detected for decompression |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-2 |
|
Stored block length did not match one’s complement; invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-3 |
|
Too many length or distance codes; invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-4 |
|
Code length codes incomplete: invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-5 |
|
Repeated lengths with no first length; invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-6 |
|
Repeat more than specified lengths; invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-7 |
|
Invalid literal/length code lengths; invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-8 |
|
Invalid distance code lengths; invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-9 |
|
Invalid literal/length or distance code in fixed or dynamic block; invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-10 |
|
Distance is too far back in fixed or dynamic block; invalid input stream detected |
Decompression
error. Discard
output. For a
stateless session,
resubmit affected
request. For a
stateful session,
abort the session
calling
|
-11 |
|
Overflow detected. This is not an error, but an exception. Overflow is supported and can be handled. |
Resubmit with a larger output buffer when appropriate. With decompression executed on QAT2.0, the application is required to resubmit the compressed data with a larger destination buffer. |
-12 |
|
Other non-fatal detected. |
Discard output. For
a stateless
session, resubmit
affected request.
For a stateful
session, abort the
session calling
|
-13 |
|
Fatal error detected. |
Discard output and
abort the session
calling
|
-14 |
|
On an error being detected, the firmware attempted to correct and resubmitted the request, however, the maximum resubmit value was exceeded. Maximal value is internally set in the firmware to 10 attempts. This is a QAT1.6 error only. This error code is considered as a fatal error. |
Discard output and
abort the session
calling
|
-15 |
|
QAT1.X device can report this error with Deflate decompression. However, it is not exposed to the application. The input file is incomplete. This indicates that the request was submitted with a CPA_DC_FLUSH_FINAL. However, a BFINAL bit was not found in the request. QAT2.0 can return this error code to the application during LZ4 decompression. This error is returned when a LZ4 block is incomplete. |
No corrective action is required as it is not exposed to the application. |
-16 |
|
The request was not completed as a watchdog timer hardware event occurred. With QAT2.0 this error can be triggered by an internal parity error. |
Discard output and resubmit the affected request. |
-17 |
|
This is a recoverable error. Request was not completed as an end point hardware error occurred (for example, a parity error). |
Discard output and
abort the session
calling
|
-18 |
|
Compress and Verify (CnV). This is a compression direction error only. During the decompression of the compressed payload, an error was detected and the deflate block produced is invalid. |
Discard output; resubmit affected request. |
-19 |
|
Decompression request contained an empty dynamic stored block (not supported). |
Discard output. |
-20 |
|
A data integrity CRC error was detected. |
Discard output. |
-93 |
|
LZ4 max block size exceeded. |
Discard output. |
-95 |
|
LZ4 block overflow. |
Discard output. |
-98 |
|
LZ4 Decoded token offset or token length is zero. |
Discard output. |
-100 |
|
LZ4 distance out of range for the len/ distance pair. |
Discard output. |
-101 |
|
Integrity input CRC computed by compression accelerator OR CnVnR or Auto- Select Best (ASB) resulted in uncompressed data. |
Discard output. |
Note
Except for the errors
CPA_DC_OK,CPA_DC_OVERFLOW,CPA_DC_FATALERR,CPA_DC_MAX_RESUBMITERR,CPA_DC_WDOG_TIMER_ERR,CPA_DC_VERIFY_ERR, andCPA_DC_EP_HARDWARE_ERR, the rest of the error codes can be considered as invalid input stream errors.When the suggested corrective action is to discard the output, it implies that the application must also ignore the consumed data, the produced data, and the checksum values.
Overflows Errors
This table describes the behavior of the Intel® QAT compression service when an overflow occurs during a compression or decompression operation. It also describes the expected behavior of an application when an overflow occurs.
Operation |
Overflow Supported |
Input Data Consumed |
Valid Data Produced? |
Status Returned in Results |
Note |
|
|---|---|---|---|---|---|---|
Traditional API |
Stateless compression |
YES |
Possible - indicated in results consumed field |
Possible - indicated in results produced field |
-11 |
Overflow is considered as an exception |
Stateless decompression |
NO |
NO |
NO |
-11 |
Overflow is considered as an error |
|
Stateful decompression |
YES on QAT1.x devices NO on QAT2.x devices |
Possible - indicated in results consumed field |
Possible - indicated in results produced field |
-11 |
Overflow is considered as an exception on QAT1.x devices. QAT2.x does not support stateful decompression. |
|
Data Plane API |
Stateless compression |
NO |
NO |
NO |
-11 |
Overflow is considered as an error |
Stateful decompression |
NO |
NO |
NO |
-11 |
Overflow is considered as an error |
Traditional API Overflow Exception
Stateless sessions support overflow as an exception for traditional API in the compression direction only. This means that the application can rely on the cpaDcRqResults.consumed to resubmit from where the overflow occurred. An overflow in the decompression direction must be treated as an error.
In this case, the application must resubmit the request with a larger buffer as described in the procedure for handling overflow errors. For stateful sessions, overflow is supported only in the decompression direction.
Data Plane API Overflow Error
The Data Plane API considers overflow status as an error. If an overflow occurs with the data plane API, the driver will output the following error message to the user:
Error: stateless overflow. Try resubmitting with a larger destination buffer
- Older versions of the driver may return the following message:
Error: stateless overflow. You may need to increase the size of your destination buffer
Note
This error is usually recoverable. Applications can resubmit the request with a larger destination buffer. The message is only printed in debug builds. Overflow is not considered a fatal error in any case.
In this case, cpaDcRqResults.consumed, .produced and .checksum should be ignored. If length and checksum are required, they must be tracked in the application, because they are not maintained in the session.
Handling Overflow Errors
Resubmit the request with the following data:
Use the same source buffer.
Allocate a bigger destination buffer. It is recommended to use the
compressBound()APIs in compression direction.If the overall checksum needs to be maintained, insert the checksum from the previous successful request into the
cpaDcRqResultsstruct.
Compression Overflows in a Virtual Environment
In a virtual environment, the guest does not download the firmware. Only the host downloads the firmware. As a consequence, if the guest runs a newer Intel® QAT driver than the host, the guest application might experience false CNV errors. The correct course of action would be to update the host with the latest Intel® QAT driver.
Avoiding Compression Overflow Exceptions
Overflow exceptions happen for 2 reasons:
The application allocated a destination buffer that was too small to receive the compressed data.
A recovery occurred after a compress and verify error with an input payload greater than 65,535 bytes if the instance lives on a QAT1.X device.
To minimize the impact of resubmitting data after and overflow exception, the API cpaDcDeflateCompressBound() has been added to the Intel® QAT driver.
A detailed explanation of compressBound APIs is provided in the Maximum Compression Expansion section.
Integrity Checksums
Integrity checksums are an additional method for payload verification throughout the compression/decompression lifecycle. They may be used to verify corruption has not happened when sending data to and from the Intel® QuickAssist HW, or for example the integrity checksums may be stored by an application along with the compressed data and used to detect corruption in the future without needing to decompress the data.
They should not be confused with the Gzip/Zlib/LZ4 footer checksums of CRC32, Adler32 and XXHash32 that are calculated over the uncompressed input data only.
Integrity checksums use an additional structure that is the application’s responsibility to allocate, maintain, and free.
The structure must be allocated by the user, and the QAT Library will populate it based on values returned by the hardware.
The structure is cpaCrcData and contains the following fields:
cpaCrcData Fields |
Description |
|---|---|
|
This is the existing CRC32 for the footer calculated across the uncompressed data in either the source or dest buffer depending whether it is a compress or decompress operation. This is the same as the value returned in the cpaDcRqResults checksum field. |
|
This is the existing Adler32/XXHash32 for the footer calculated across the uncompressed data in either the source or dest buffer depending whether it is a compress or decompress operation. This is the same as the value returned in the cpaDcRqResults checksum field. |
|
This field contains the QAT 1.8 integrity checksums that consist of two 32bit CRC32’s. These are calculated on the input data to the request within the HW and on the output data from the request within the HW. |
|
This field contains the QAT 2.0 integrity checksums that consist of two 64 bit checksums. CPM 2.0 uses CRC64 by default for these checksums. The checksums are calculated on the input data to the request within the HW and on the output data from the request within the HW. |
QAT will generate both CRC32 and CRC64. The CRC32 generated is the standard CRC32 as defined in the GZIP RFC (RFC 1952). All compression algorithms support CRC generation in 4th Gen Intel® Xeon® Scalable processor and later CPUs.
The CRC attributes of
integrityCrc64bcan be modified by thecpaDcSetCrcControlData()API call if sessions are used, meaning it’s mapped to QAT’s programmable CRC feature. If thecpaDcSetCrcControlDataAPI is not used, the QAT driver uses default CpaCrcControlData. The CRC32/Adler32 for deflate’s CRC attributes are fixed.Once allocated, a pointer to the
cpaCrcDatastructure must be assigned to thepCrcDatafield of the requestsCpaDcOpDatastructure.The
cpaCrcDatastructure assigned to thepCrcDatapointer should be treated in the same way as the destination buffer, not freed until the request has completed, and not shared across requests if running asynchronously.The integrity checksum feature itself is enabled on a per request basis by setting the
integrityCrcCheckfield contained in theCpaDcOpDatastructure toCPA_TRUE.For decompression jobs, the application can verify the CRC32/Adler32 returned by QAT against the CRC32/Adler32 in the GZIP/ZLIB frame as an integrity verification.
Integrity checksums are available on the Traditional API including No Session requests, but are not available on the Data Plane API.
Integrity checksums are calculated across only the current request in QAT 2.0. With QAT 1.8 it is possible to seed the integrity checksums on stateful decompression requests by reusing the same
cpaCrcDatastructure on the subsequent request without resetting the contents. For QAT 1.8 stateful decompression requests it is the application’s responsibility to allocate thecpaCrcDatastructure and keep it allocated for the lifetime of the session. Integrity checksums are not available on devices prior to QAT 1.8.
Verify HW Integrity CRC’s
There is an additional feature to integrity checksums that can be enabled to automatically check that no corruption to data buffers has occurred during transport to and from the Intel® QAT HW. This works by calculating integrity checksums across the source and destination buffers within the Intel® QAT API, and comparing the checksums with those generated within the Intel® QAT HW. Any discrepancies will result in a status of CPA_DC_INTEG_ERR being returned within the cpaDcRqResults structure. These additional checksums are calculated in SW using the CPU and have a cost in terms of performance.
In order to enable the Verify HW Integrity CRC feature on a per request basis the verifyHwIntegrityCrcs field contained in the cpaDcOpdata structure needs to be set to CPA_TRUE. Additionally the integrityCrcCheck field must be enabled and a cpaCrcData structure allocated and a pointer to it must be assigned to the pCrcData field.
Data Compression Applications
Data compression can be used as part of application delivery networks, data de-duplication, as well as in a number of crypto applications, for example, VPNs, IDS/IPS and so on.
Compression for Storage
In a time when the amount of online information is increasing dramatically, but budgets for storing that information remain static, compression technology is a powerful tool for improved information management, protection and access.
Compression appliances can transparently compress data such that clients can keep between two- and five-times more data online and reap the benefit of other efficiencies throughout the data lifecycle. By shrinking the primary data, all subsequent copies of that data, such as backups, archives, snapshots, and replicas are also compressed. Compression is the newest advancement in storage efficiency.
Storage compression appliances can shrink primary online data in real time, without performance degradation. This can significantly lower storage capital and operating expenses by reducing the amount of data that is stored, and the required hardware that must be powered and cooled.
Compression can help slow the growth of storage, reducing storage costs while simplifying both operations and management. It also enables organizations to keep more data available for use, as opposed to storing data offsite or on harder-to-access media (such as tape). Compression algorithms are very compute-intensive, which is one of the reasons why the adoption of compression techniques in mainstream applications has been slow.
As an example, the DEFLATE Algorithm, which is one of the most used and popular compression techniques today, involves several compute-intensive steps: string search and match, sort logic, binary tree generation, Huffman Code generation. Intel® QAT devices in the platforms described in this manual provide acceleration capabilities in hardware that allow the CPU to offload the compute-intensive DEFLATE algorithm operations, thereby freeing up CPU cycles for other networking, encryption, or other value-add operations.
Data Deduplication and WAN Acceleration
Data Deduplication and WAN Acceleration are coarse-grain data compression techniques centered around the concept of single-instance storage. Identical blocks of data (either to be stored on disk or to be transferred across a WAN link) are only stored/moved once, and any further occurrences are replaced by a reference to the first instance.
While the benefits of deduplication and WAN acceleration obviously depend on the type of data, multi-user collaborative environments are the most suitable due to the amount of naturally occurring replication caused by forwarded emails and multiple (similar) versions of documents in various stages of development.
Deduplication strategies can vary in terms of inline vs post-processing, block size granularity (file-level only, fixed block size or variable block-size chunking), duplicate identification (cryptographic hash only, simple CRC followed by byte-level comparison or hybrids) and duplicate look-up (for example, Bloom filter based index).
Cryptographic hashes are the most suitable techniques for reliably identifying matching blocks with an improbably low risk for false positives, but they also represent the most compute-intensive workload in the application. As such, the cryptographic acceleration services offered by the hardware through the Intel® QAT Cryptographic API can be used to considerably improve the throughput of deduplication/WAN acceleration applications. Additionally, the compression/decompression acceleration services can be used to further compress blocks for storage on disk, while optionally encrypting the compressed contents.