Note
Go to the end to download the full example code.
Understanding Data Projection¶
Projecting data onto P3 definitions.
The P3 Analysis Library expects data to be prepared in a specific format. This format was inspired by the terminology first introduced in “Implications of a Metric for Performance Portability”:
- Problem
A task with a pass/fail metric for which quantitative performance may be measured. Multiplying an
- Application
Software capable of solving a problem with measurable correctness and performance. Math libraries, Python scripts, C functions, and entire software packages are all examples of applications; the Intel® oneAPI Math Kernel Library is an example of an application for solving linear algebra problems.
- Platform
A collection of software and hardware on which an application may run a problem. A specific processor coupled with an operating system, compiler, runtime, drivers, library dependencies, etc is an example of a precise platform definition.
These definitions are flexible, allowing the same performance data to be used for multiple case studies with different interpretations of these terms.
Rather than store raw performance data in columns corresponding to these definitions, the P3 Analysis Library provides functionality to project raw performance data onto specific meanings of “problem”, “application” and “platform”.
Using Projection to Rename Columns¶
The simplest example of projection is a straightforward renaming of columns.
Let’s assume that we’ve collected some performance data from a few different implementations of a function, running a number of problem sizes on multiple machines.
Important
Although we are looking at “function” performance here, the concepts generalize to entire software packages.
Our raw performance data might look like this:
size |
implementation |
machine |
fom |
|---|---|---|---|
128x128x128 |
Library 1 |
Cluster 1 |
0.5 |
256x256x256 |
Library 1 |
Cluster 1 |
2.0 |
128x128x128 |
Library 2 |
Cluster 1 |
0.7 |
256x256x256 |
Library 2 |
Cluster 1 |
2.1 |
128x128x128 |
Library 1 |
Cluster 2 |
0.25 |
256x256x256 |
Library 1 |
Cluster 2 |
1.0 |
128x128x128 |
Library 2 |
Cluster 2 |
0.125 |
256x256x256 |
Library 2 |
Cluster 2 |
0.5 |
The most obvious projection of this data onto P3 definitions is as follows:
Each input size maps to a different problem, because each input represents a different task to be solved, with its own expected answer to validate against.
Each implementation maps to a different application, because each library’s implementation of the function produces a solution for a given input with measurable performance and correctness.
Each machine maps to a different platform, because each cluster name describes the combination of hardware and software used to run the experiments.
Important
In reality, a single value is unlikely to provide enough information to fully and unambiguously describe a function’s behavior, its implementation, or the state of a machine when its performance was recorded. But we’ll come back to that later.
After loading our data into a pandas.DataFrame
(df), we can use the
p3analysis.data.projection() function to perform this
projection, renaming the columns as described above.
problem application platform fom
0 128x128x128 Library 1 Cluster 1 0.500
1 256x256x256 Library 1 Cluster 1 2.000
2 128x128x128 Library 2 Cluster 1 0.700
3 256x256x256 Library 2 Cluster 1 2.100
4 128x128x128 Library 1 Cluster 2 0.250
5 256x256x256 Library 1 Cluster 2 1.000
6 128x128x128 Library 2 Cluster 2 0.125
7 256x256x256 Library 2 Cluster 2 0.500
Following projection, our performance data is now ready to be passed to
functions in the p3analysis.metrics module.
Using Projection to Combine Columns¶
As we alluded to earlier, it’s unlikely that a single column of the raw data fully captures the definition of a “problem”, “application” or “platform”.
Let’s make our raw data slightly more complicated, by introducing the notion that the function of interest is available in both single precision (FP32) and double precision (FP64).
size |
precision |
implementation |
machine |
fom |
|---|---|---|---|---|
128x128x128 |
FP32 |
Library 1 |
Cluster 1 |
0.5 |
256x256x256 |
FP32 |
Library 1 |
Cluster 1 |
2.0 |
128x128x128 |
FP32 |
Library 2 |
Cluster 1 |
0.7 |
256x256x256 |
FP32 |
Library 2 |
Cluster 1 |
2.1 |
128x128x128 |
FP32 |
Library 1 |
Cluster 2 |
0.25 |
256x256x256 |
FP32 |
Library 1 |
Cluster 2 |
1.0 |
128x128x128 |
FP32 |
Library 2 |
Cluster 2 |
0.125 |
256x256x256 |
FP32 |
Library 2 |
Cluster 2 |
0.5 |
128x128x128 |
FP64 |
Library 1 |
Cluster 1 |
1.0 |
256x256x256 |
FP64 |
Library 1 |
Cluster 1 |
4.0 |
128x128x128 |
FP64 |
Library 2 |
Cluster 1 |
1.4 |
256x256x256 |
FP64 |
Library 2 |
Cluster 1 |
4.2 |
128x128x128 |
FP64 |
Library 1 |
Cluster 2 |
0.5 |
256x256x256 |
FP64 |
Library 1 |
Cluster 2 |
2.0 |
128x128x128 |
FP64 |
Library 2 |
Cluster 2 |
0.25 |
256x256x256 |
FP64 |
Library 2 |
Cluster 2 |
1.0 |
How does this impact our projection? The implementation and machine columns are still enough to describe the application and platform (respectively), but what about the problem? The answer is, of course: “It depends”.
Luckily, this dataset is simple enough that we can enumerate our options:
Each unique (size, precision) tuple maps to a different problem, representing that the problem definition requires the task to be solved to a specific precision (and that the precision has a material impact on the verification of results).
Each size maps to a different problem as before, representing that the problem definition does not require the task to be solved to any specific precision, and that implementations are free to select whichever precision delivers the best performance.
Neither of these options is more correct than the other. Rather, they represent different studies.
Both projections can be performed with the p3analysis.data.projection()
function, by passing different arguments.
For the first projection, we now need to specify the names of two columns (“size” and “precision”) to define the problem:
application platform fom problem
0 Library 1 Cluster 1 0.500 128x128x128-FP32
1 Library 1 Cluster 1 2.000 256x256x256-FP32
2 Library 2 Cluster 1 0.700 128x128x128-FP32
3 Library 2 Cluster 1 2.100 256x256x256-FP32
4 Library 1 Cluster 2 0.250 128x128x128-FP32
5 Library 1 Cluster 2 1.000 256x256x256-FP32
6 Library 2 Cluster 2 0.125 128x128x128-FP32
7 Library 2 Cluster 2 0.500 256x256x256-FP32
8 Library 1 Cluster 1 1.000 128x128x128-FP64
9 Library 1 Cluster 1 4.000 256x256x256-FP64
10 Library 2 Cluster 1 1.400 128x128x128-FP64
11 Library 2 Cluster 1 4.200 256x256x256-FP64
12 Library 1 Cluster 2 0.500 128x128x128-FP64
13 Library 1 Cluster 2 2.000 256x256x256-FP64
14 Library 2 Cluster 2 0.250 128x128x128-FP64
15 Library 2 Cluster 2 1.000 256x256x256-FP64
The original “size” and “precision” columns have been removed, and their values have been concatenated to form the new “problem” column.
For the second projection, we just need to specify “size”, exactly as we did before:
problem application platform fom precision
0 128x128x128 Library 1 Cluster 1 0.500 FP32
1 256x256x256 Library 1 Cluster 1 2.000 FP32
2 128x128x128 Library 2 Cluster 1 0.700 FP32
3 256x256x256 Library 2 Cluster 1 2.100 FP32
4 128x128x128 Library 1 Cluster 2 0.250 FP32
5 256x256x256 Library 1 Cluster 2 1.000 FP32
6 128x128x128 Library 2 Cluster 2 0.125 FP32
7 256x256x256 Library 2 Cluster 2 0.500 FP32
8 128x128x128 Library 1 Cluster 1 1.000 FP64
9 256x256x256 Library 1 Cluster 1 4.000 FP64
10 128x128x128 Library 2 Cluster 1 1.400 FP64
11 256x256x256 Library 2 Cluster 1 4.200 FP64
12 128x128x128 Library 1 Cluster 2 0.500 FP64
13 256x256x256 Library 1 Cluster 2 2.000 FP64
14 128x128x128 Library 2 Cluster 2 0.250 FP64
15 256x256x256 Library 2 Cluster 2 1.000 FP64
This time, the original “size” column has been removed, but the “precision” column remains.
Clearly, the values provided to the projection function change the structure
of the resulting pandas.DataFrame. But why does that matter?
Well, let’s take a look at what happens if we compute the maximum “fom” for
each (problem, application, platform) tuple in our projected datasets:
max1 = proj1.groupby(["problem", "application", "platform"])["fom"].max()
print(max1)
problem application platform
128x128x128-FP32 Library 1 Cluster 1 0.500
Cluster 2 0.250
Library 2 Cluster 1 0.700
Cluster 2 0.125
128x128x128-FP64 Library 1 Cluster 1 1.000
Cluster 2 0.500
Library 2 Cluster 1 1.400
Cluster 2 0.250
256x256x256-FP32 Library 1 Cluster 1 2.000
Cluster 2 1.000
Library 2 Cluster 1 2.100
Cluster 2 0.500
256x256x256-FP64 Library 1 Cluster 1 4.000
Cluster 2 2.000
Library 2 Cluster 1 4.200
Cluster 2 1.000
Name: fom, dtype: float64
max2 = proj2.groupby(["problem", "application", "platform"])["fom"].max()
print(max2)
problem application platform
128x128x128 Library 1 Cluster 1 1.00
Cluster 2 0.50
Library 2 Cluster 1 1.40
Cluster 2 0.25
256x256x256 Library 1 Cluster 1 4.00
Cluster 2 2.00
Library 2 Cluster 1 4.20
Cluster 2 1.00
Name: fom, dtype: float64
Similar pandas.DataFrame.groupby() calls form the backbone of many
functions provided by the P3 Analysis Library, since metrics like
“application efficiency” and “performance portability” ultimately depend on
an understanding of which variable combinations deliver the best performance.
Important
The selected projection can have significant impact on the results of subsequent analysis, and it is critical to ensure that the projection is correct before digging too deep into (or presenting!) any results.
Next Steps¶
After raw performance data has been projected onto definitions
of “problem”, “application”, and “platform”, it can be passed to
any of the P3 Analysis Library functions that expect a
pandas.DataFrame.
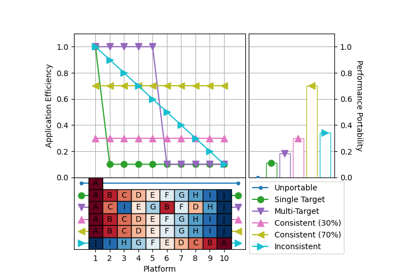
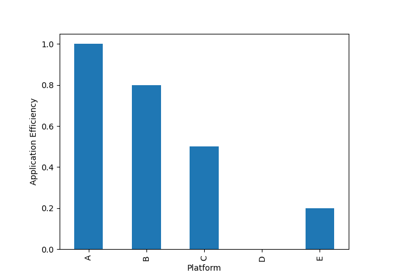
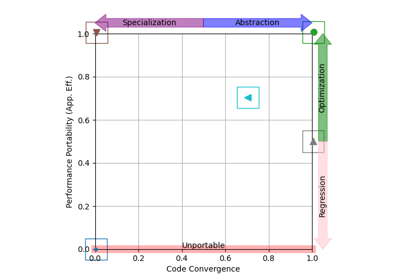
The examples below show how to use projected data to compute and visualize derived metrics like “application efficiency”, “performance portability”, and “code divergence”.
Examples¶
Total running time of the script: (0 minutes 0.021 seconds)