Online Weight Prepack
Overview
In modern deep learning framework, Weight Reorder is widely used in inference models which converts weight from plain layout to blocked layout for better performance. It performs operations faster but will use extra memory to store the original memory in plain layout. Here the stored original plain layout weight is called master weight.
To reduce the memory footprint, Weight Prepack graph optimization is introduced. It directly replaces the master weight with the reordered weight in runtime, instead of creating a new blocked layout weight:
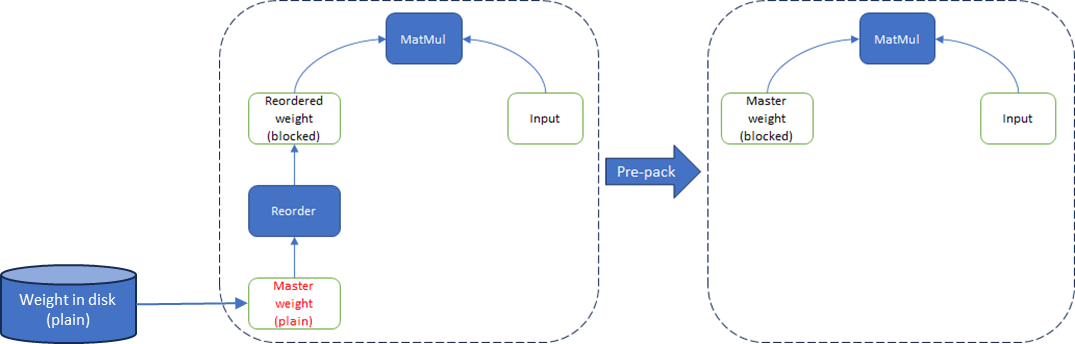 Fig. 1 Weight reorder & weight prepack
Fig. 1 Weight reorder & weight prepack
|
There are 2 ways to prepack weight:
Offline, prepack weight in the original model before execution by a third-party tool. It will change the original model stored in the disk.
Online, prepack weight by framework online optimization pass in runtime. It won’t change the original model stored in the disk, maintaining good portability of the model.
Intel® Extension for TensorFlow* has provided Online Weight Prepack.
Usage & Effect
This feature is always enabled; no additional actions are required.
The optimization effect depends on the ratio of reordered weights in the model. In regular BERT-large inference, it can reduce memory footprint by ~10%.
Workflow
Weight Prepack is a graph optimization, which means it only happens once in the compilation phase. The graph optimizer will traverse the graph and find out the weights that need to be prepacked. A corresponding oneDNN primitive with proxy shape will be created to estimate the possible blocked layout when weight is found. After that, the estimated blocked layout info will be recorded to that weight node in the graph and used to do the real operation in the execution phase.
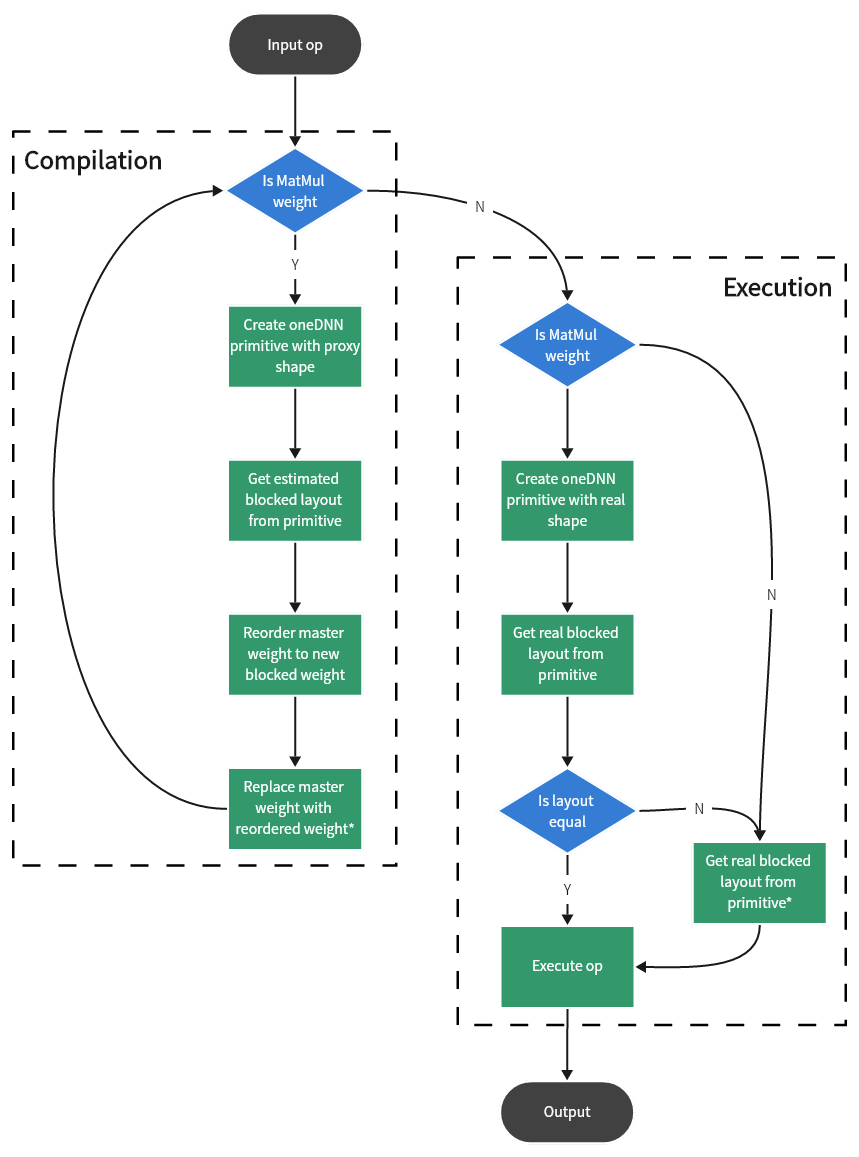 Fig. 2 Weight prepack workflow
Fig. 2 Weight prepack workflow
|
Replacing master weights with the reordered weights is the key step to reduce the memory footprint.
The step for reordering master weights will be eliminated if weight prepack succeeds. It also reduces the number of operators during executing and improves performance.
NOTE: This estimation of blocked layout may not always be accurate (see Limitation for more details). Once the estimation fails, the prepacked weight will be reordered to another blocked layout required by the execution phase after it becomes the new master weight.
Limitation
Proxy shape is used to estimate blocked layout because the real shape is not available in the compilation phase. This will make the optimization not work if the estimated info doesn’t match the real info in the execution phase, and make the application perform the same behavior as unoptimized.
Only available for matrix multiplication (MatMul) and related operators on CPU.
May not work with dynamic shapes since the required blocked layout will be changed in different iterations.