Practice Guide
Overview
Intel® Extension for TensorFlow* is a Python package that extends the official TensorFlow, in order to achieve improved performance. Although both official TensorFlow and the default configuration of Intel® Extension for TensorFlow* perform well, there are additional steps you can take to optimize performance on specific platforms. Most optimized configurations can be set automatically by the launcher script. This article covers common tips recommended by Intel developers.
Table of Contents
CPU Practice Guide
Hardware Configuration
This section briefly introduces the structure of Intel CPUs, as well as the concept of Non-Uniform Memory Access (NUMA), for background knowledge.
Non-Uniform Memory Access (NUMA)
More and more CPU cores are being provided in one socket, which provides the benefit of greater computation resources. However, this also causes memory access competition. Programs may stall due to the memory being busy. To address this problem, Non-Uniform Memory Access (NUMA) was introduced. Compared to Uniform Memory Access (UMA), where all memories are connected to all cores equally, NUMA divides memories into multiple groups. A certain number of memories are directly attached to one socket’s integrated memory controller, to become local memory of this socket, while other memories become remote memory to other sockets. Local memory access is much faster than remote memory access.
You can get CPU information with the lscpu command on Linux to see how many cores and sockets are on the machine, as well as NUMA information such as how CPU cores are distributed.
The following is an example of lscpu execution on a machine with two Intel® Xeon® Platinum 8180M CPUs. Two sockets were detected. Each socket has 28 physical cores onboard. Since Hyper-Threading is enabled, each core can run 2 threads. That means each socket has another 28 logical cores. Thus, a total of 112 CPU cores are available. When indexing CPU cores, physical cores are typically indexed before logical cores. In this case, the first 28 cores (0-27) are physical cores on the first NUMA socket (node), while the second 28 cores (28-55) are physical cores on the second NUMA socket (node). Logical cores are indexed afterward. 56-83 are 28 logical cores on the first NUMA socket (node), and 84-111 are the second 28 logical cores on the second NUMA socket (node). Typically, running Intel® Extension for TensorFlow* on logical cores can negatively impact performance and should therefore be avoided.
$ lscpu
...
CPU(s): 112
On-line CPU(s) list: 0-111
Thread(s) per core: 2
Core(s) per socket: 28
Socket(s): 2
NUMA node(s): 2
...
Model name: Intel(R) Xeon(R) Platinum 8180M CPU @ 2.50GHz
...
NUMA node0 CPU(s): 0-27,56-83
NUMA node1 CPU(s): 28-55,84-111
...
Software Configuration
This section introduces software configurations that help to boost performance.
Memory Layout format
The default memory layout format of Intel® Extension for TensorFlow* is NHWC format, much like the official TensorFlow default format. This format is generally friendly to most models, but some models may find higher performance with the NCHW format by benefitting from the oneDNN block format.
The below environment settings are for the two different memory formats mentioned above.
ITEX_LAYOUT_OPT=0
ITEX_LAYOUT_OPT=1
Numactl
Since NUMA largely influences memory access performance, the Linux tool numactl allows you to control NUMA policy for processes or shared memory. It runs processes with a specific NUMA scheduling or memory placement policy. As described in the previous section, cores share high-speed caches in one socket, thus it is a good idea to avoid cross socket computations. From a memory access perspective, bounding memory access to local memories is much faster than accessing remote memories.
The following is an example of numactl usage to run a workload on the Nth socket, and limit memory access to its local memories on the Nth socket. More detailed description of numactl command can be found on the Numactl Linux Man Page.
numactl --cpunodebind N --membind N python <script>
Assuming cores 0-3 are on socket 0, the following command binds script execution on core 0-3, and binds memory access to socket 0 local memories.
numactl --membind 0 -C 0-3 python <script>
OpenMP
OpenMP is an implementation of multi-threading, a method of parallelizing whereby a master thread (a series of instructions executed consecutively) forks a specified number of sub-threads, and the system divides tasks among them. The threads then run concurrently, with the runtime environment allocating threads to different processors[1]. Figure 1 illustrates fork-join model of OpenMP execution.
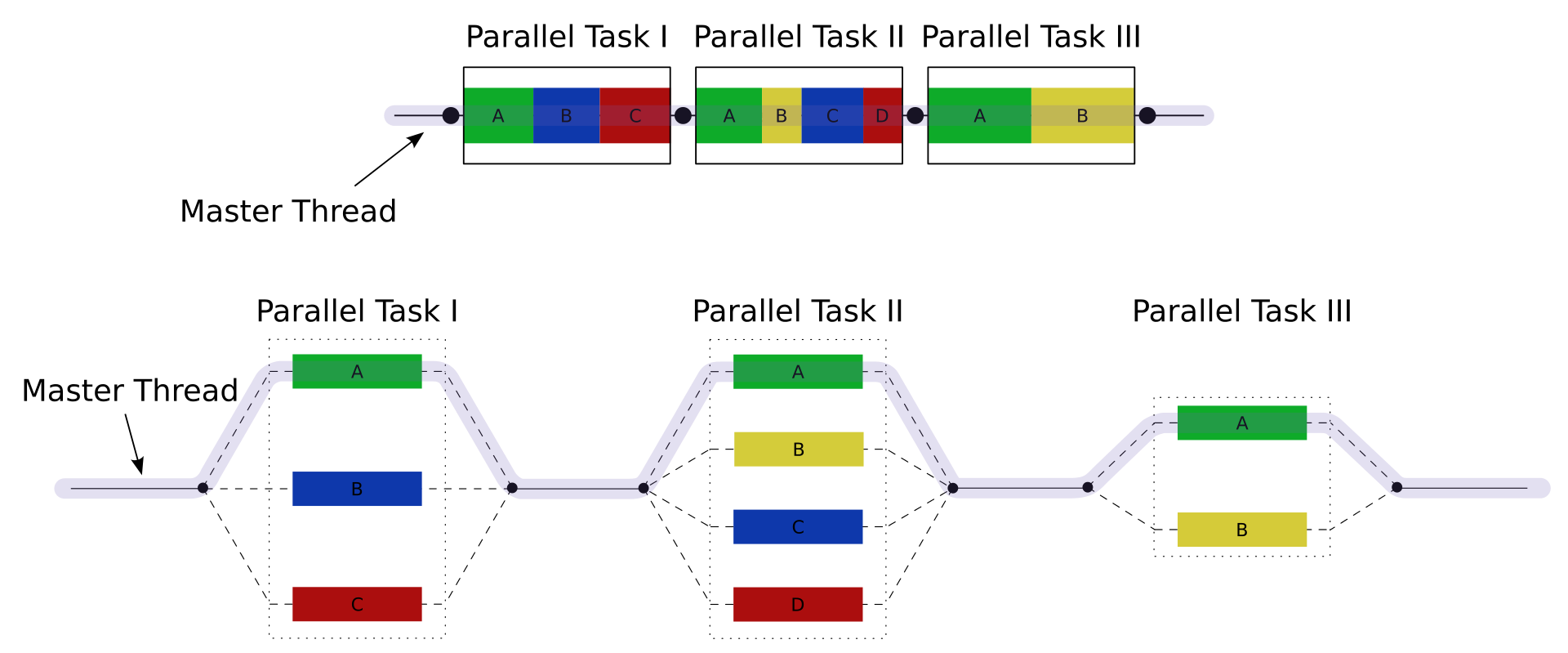
Figure 1 A number of parallel block execution threads are forked from master thread
You can control OpenMP behaviors through some environment variables to fit your workloads. Also, beside the GNU OpenMP library (libgomp), Intel provides another OpenMP implementation libiomp to choose from. Environment variables that control behavior of OpenMP threads may differ from libgomp and libiomp. They will be introduced separately in sections below.
OMP_NUM_THREADS
Environment variable OMP_NUM_THREADS sets the number of threads to use for parallel regions. By default, it is set to be number of available physical cores. It can be used along with numactl settings, as seen in the following example. If cores 0-3 are on socket 0, this example command runs <script> on cores 0-3, with 4 OpenMP threads.
This environment variable works on both libgomp and libiomp.
export OMP_NUM_THREADS=4
numactl -C 0-3 --membind 0 python <script>
GNU OpenMP
Beside OMP_NUM_THREADS, a couple of GNU OpenMP specific environment variables are commonly used to improve performance.
GOMP_CPU_AFFINITY: Binds threads to specific CPUs. The variable should contain a space-separated or comma-separated list of CPUs or hyphen-separated CPU numbers specifying a range of CPUs.
OMP_PROC_BIND: Specifies whether threads may be moved between processors. Setting it to
CLOSEkeeps OpenMP threads close to the primary thread in contiguous place partitions.OMP_SCHEDULE: Determine how OpenMP threads are scheduled.
The following is a recommended combination of these environment variables:
export GOMP_CPU_AFFINITY="0-3"
export OMP_PROC_BIND=CLOSE
export OMP_SCHEDULE=STATIC
Intel OpenMP
On Intel platforms, Intel OpenMP Runtime Library (libiomp) provides OpenMP API specification support. It can provide better performance, compared to libgomp. Utilizing environment variable LD_PRELOAD can switch OpenMP library to libiomp:
export LD_PRELOAD=<path>/libiomp5.so:$LD_PRELOAD
Similar to GNU OpenMP, besides OMP_NUM_THREADS, there are several Intel OpenMP specific environment variables that control behavior of OpenMP threads.
KMP_AFFINITY
KMP_AFFINITY controls how to bind OpenMP threads to physical processing units. Depending on the system (machine) topology, application, and operating system, thread affinity can have a dramatic effect on the application speed.
A common usage scenario is for consecutive threads to be bound close together, as is done with
KMP_AFFINITY=compact, so that communication overhead, cache line invalidation overhead, and page thrashing are minimized. Now, suppose the application also had a number of parallel regions that did not utilize all of the available OpenMP threads. We should avoid binding multiple threads to the same core and leaving other cores not utilized, since a thread normally executes faster on a core where it is not competing for resources with another active thread on the same core. This can be achieved by the following command. Figure 2.2 illustrates this strategy.export KMP_AFFINITY=granularity=fine,compact,1,0
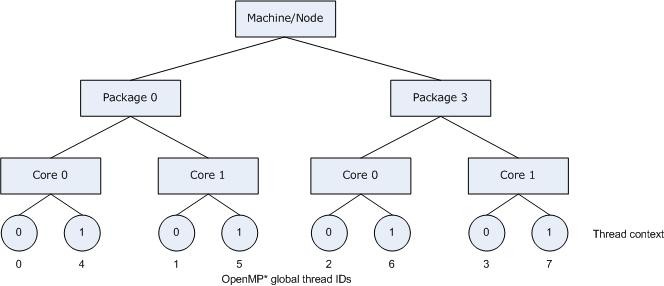
Figure 2.2 *KMP_AFFINITY=granularity=fine,compact,1,0*
The OpenMP thread n+1 is bound to a thread context as close as possible to OpenMP thread n, but on a different core. Once each core has been assigned one OpenMP thread, the subsequent OpenMP threads are assigned to the available cores in the same order, but they are assigned on different thread contexts.
It is also possible to bind OpenMP threads to certain CPU cores with the following command.
export KMP_AFFINITY=granularity=fine,proclist=[N-M],explicit
More detailed information about KMP_AFFINITY can be found Intel® C++ Compiler Classic Developer Guide and Reference.
KMP_BLOCKTIME
KMP_BLOCKTIME sets the time, in milliseconds, that a thread should wait, after completing the execution of a parallel region, before sleeping. The default value is 200ms.
After completing the execution of a parallel region, threads wait for new parallel work to become available. After a certain period of time has elapsed, they stop waiting and sleep. Sleeping allows the threads to be used by non-OpenMP threaded code or by other applications, until more parallel work becomes available. A small
KMP_BLOCKTIMEvalue may offer better overall performance if the application contains non-OpenMP threaded code that executes between parallel regions. A larger KMP_BLOCKTIME value may be more appropriate if threads are to be reserved solely for use for OpenMP execution, but may penalize other concurrently-running OpenMP or threaded applications. Set it to 0 or 1 for convolutional neural network (CNN) based models.export KMP_BLOCKTIME=0 (or 1)
Memory Allocator
Memory allocator plays an important performance role as well. A more efficient memory usage reduces overhead on unnecessary memory allocations or destructions, and thus results in a faster execution. From practical experience, for deep learning workloads, TCMalloc can get better performance by reusing memory as much as possible versus the default malloc function.
To enable TCMalloc, add the path of TCMalloc dynamic library to environment variable LD_PRELOAD to switch the memory allocator.
export LD_PRELOAD=<jemalloc.so/tcmalloc.so>:$LD_PRELOAD
TCMalloc
TCMalloc features optimizations to speed up program executions. One of them is holding memory in caches to speed up access of commonly-used objects. Holding such caches even after deallocation helps avoid costly system calls if such memory is later re-allocated. It is part of gperftools, a collection of a high-performance multi-threaded malloc() implementation, plus some nice performance analysis tools.
Install gperftools using these instructions:
wget https://github.com/gperftools/gperftools/releases/download/gperftools-<version>/gperftools-<version>.tar.gz
tar xzvf gperftools-<version>.tar.gz
cd gperftools-<version>
./configure --disable-cpu-profiler --disable-heap-profiler --disable-heap-checker --disable-debugalloc --enable-minimal
make
make install
GPU Practice Guide
The default configuration is recommended for GPU practice.