INT8 Quantization
Overview
Quantization is a very popular deep learning model optimization technique invented for improving the speed of inference. It minimizes the number of bits required by converting a set of real-valued numbers into a lower bit data representation, such as INT8, mainly on inference phase with minimal to no loss in accuracy. Using a lower bit data representation reduces the memory requirement, cache miss rate, and computational cost of using neural networks and also provides higher inference performance.
Intel® Extension for TensorFlow* co-works with Intel® Neural Compressor v2.0 or newer to provide INT8 quantization solutions for both GPU and CPU.
Intel® Extension for Tensorflow* integrates and adopts new oneDNN Graph API in INT8 quantization for better out of box performance as shown in the following example.
Workflow
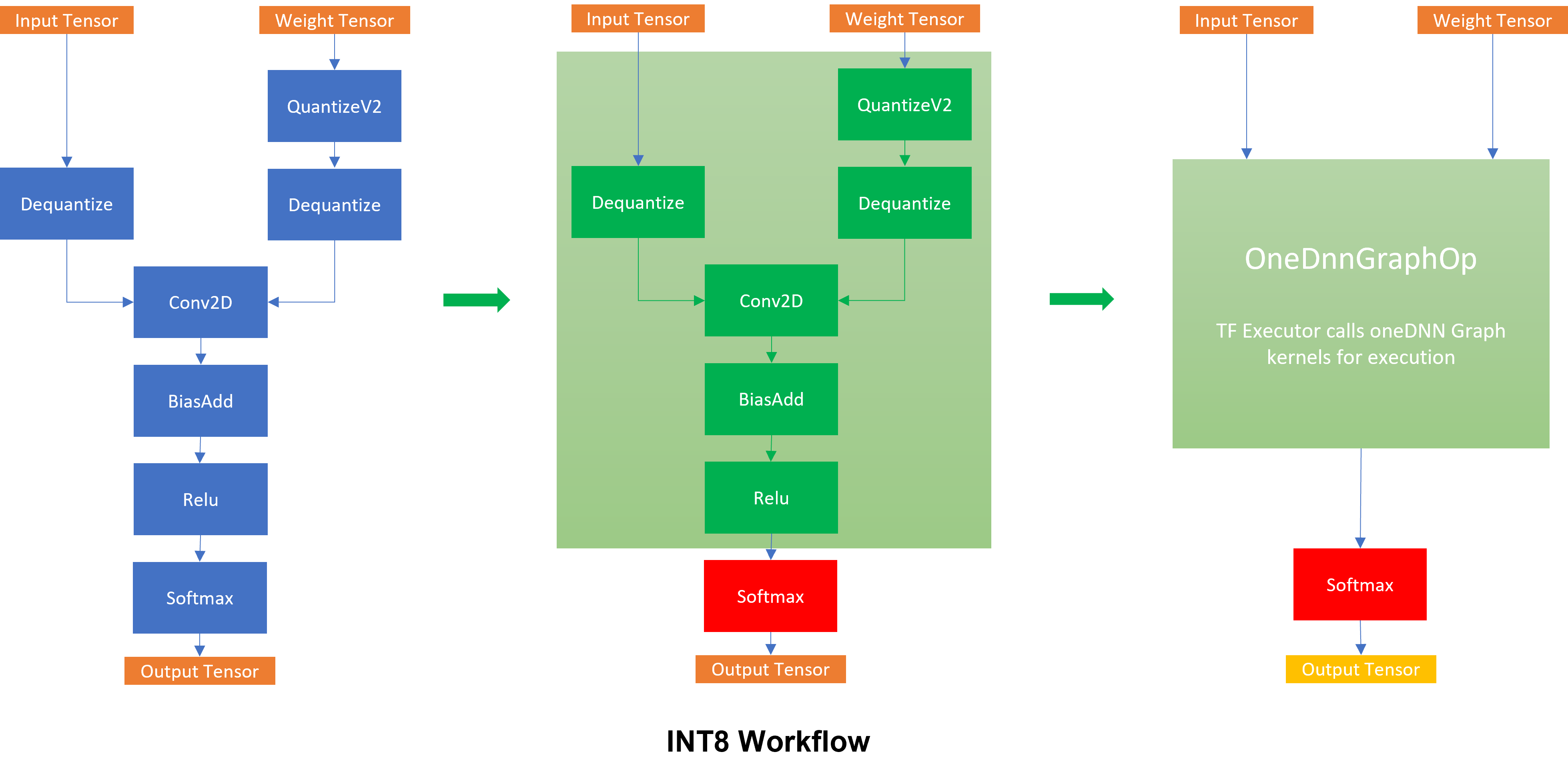 The green subgraph is one of the supported oneDNN Graph INT8 patterns. The operators within the subgraph are converted into a single
The green subgraph is one of the supported oneDNN Graph INT8 patterns. The operators within the subgraph are converted into a single OneDnnGraph operator, which calls oneDNN Graph kernel during execution.
The workflow contains 2 parts: graph optimization and graph executor.
Graph optimization: TensorFlow graph is partitioned into subgraphs based on compatibility of oneDNN Graph.
Kernel Execution: The compatible subgraphs are executed by oneDNN Graph, and the result of operators in the graph are delegated to native kernels.
Usage
oneDNN Graph optimization pass is enabled on INT8 quantization by default on GPU and CPU.
For better performance in INT8 models execution, TF grappler constant folding optimization must be disabled by the following environment variable setting.
export ITEX_TF_CONSTANT_FOLDING=0
Refer to Inception V3 quantization example for details.