InnerSource Portal¶
Example of using DFFML to create a web app to discover information about software. The purpose of this example is to write an application using dataflows. We’ll show how a dataflow based architecture results in a software development workflow that makes is easy for a large group of developers to collaborate quickly and effectively.
All the code for this example project is located under the examples/innersource/swportal directory of the DFFML source code.
History¶
DFFML was initially developed for use in an allowlist tool. The allowlist tool was similar to the InnerSource portal in that it collected and displayed metrics on software projects. It also ran those collected metrics through a machine learning model to assign a classification to the projects.
The “Down the Dependency Rabbit Hole” talk from BSides PDX 2019 provides more detail on this history and architecture. The following link will skip to the metric gathering portion of the presentation which is the part of the talk most relevant to this example. https://www.youtube.com/watch?v=D9puJiKKKS8&t=328s
Frontend¶
We’ll be leveraging the InnerSource portal built by SAP https://github.com/SAP/project-portal-for-innersource as our frontend.
You need to have nodejs installed (and yarn, or can replace it with npm)
before you can run the following commands.

We need to download the code first for the portal first. We’ll be working from a
snapshot so you’ll see a long string of hex which is the git commit. We download
the code and rename the downloaded directory to html-client.
$ curl -sfL 'https://github.com/SAP/project-portal-for-innersource/archive/8a328cf30f5626b3658577b223d990af6285c272.tar.gz' | tar -xvz
$ mv project-portal-for-innersource-8a328cf30f5626b3658577b223d990af6285c272 html-client
Now we go into the html-client directory, install the depenedencies, and start the server.
$ cd html-client
$ yarn install
yarn install v1.22.5
info No lockfile found.
[1/4] Resolving packages...
[2/4] Fetching packages...
[3/4] Linking dependencies...
[4/4] Building fresh packages...
success Saved lockfile.
Done in 2.38s.
$ yarn start
yarn run v1.22.5
Starting up http-server, serving.
Available on:
http://127.0.0.1:8080
Hit CTRL-C to stop the server
Now open a new terminal, make sure you’re in the directory we started in, so
that html-client is a subdirectory. You may need to change directory to the
parent directory.
$ cd ..
$ ls -l
Crawler¶
This tutorial focuses on building the “crawler”, which is the code that grabs metrics on each project in the portal.
The crawler is responsible for generating the metrics seen on each project modal popup.
You can read more about what the expectations for the crawler are here: https://github.com/SAP/project-portal-for-innersource/blob/main/docs/CRAWLING.md

Constraints¶
We have a number of constraints for this example.
The repos we are interested in displaying are all hosted in GitHub. We can find the information we need stored on the file system. (See the orgs directory to see what this looks like).
The structure is such that GitHub orgs are directories. Each directory has a
repos.ymlfile in it. There may be multiple YAML documents per file. Each YAML document gives the repo name and the repo owners.
Different repo owners will want to collect and display different metrics in their project’s detail page.
We want to make is easy for developers to reuse existing code and data when collecting new metrics.
We’ll use DataFlows to collect metrics
We must output in repos.json format that the SAP portal frontend knows how to consume.
Architecture¶
The following diagram shows the high level architecture of a crawler that satisfies our constraints.

Implementation Plan¶
We’ll be leveraging three major DFFML concepts as we implement our crawler. These are Sources, and DataFlows & Operations.
The input
repo.ymlfiles and the outputrepos.jsonfile are ideal candidates for DFFML Sources.A Source in DFFML is anything containing records which can be referenced by a unique identifier.
A GitHub repo can be uniquely identified by it’s organization / user and it’s name.
Collecting a dataset, in this case metrics for a given repo, is a job for a DataFlow.
We can combine many different Operations together to collect metrics.
We’re going to query GitHub for some metrics / data.
We’re going to re-use metric gathers from the allowlist tool.
Input Data¶
Let’s create the orgs/ directory, and two subdirectories. One for the
intel GitHub organization, and one for the tpm2-software organization.
These directories will contain the repos.yml files.
$ mkdir orgs/
$ mkdir orgs/intel/
$ mkdir orgs/tpm2-software/
Create the following files. For the sake of this example, the YAML file format
we’re working with has multiple YAML documents per file, separated with ---.
Each document represents a GitHub repo. Each document gives the name of the repo
and the repo owners.
orgs/intel/repos.yml
---
name: dffml
owners:
- johnandersenpdx@gmail.com
---
name: cve-bin-tool
owners:
- terri@toybox.ca
orgs/tpm2-software/repos.yml
---
name: tpm2-pkcs11
owners:
- william.c.roberts@intel.com
---
name: tpm2-tools
owners:
- imran.desai@intel.com
Reading Inputs¶
Create a directory where we’ll store all of the sources (Python classes) we’ll use to read and write repo data / metrics.
$ mkdir sources/
Install the PyYAML library, which we’ll use to parse the YAML files.
$ python -m pip install PyYAML
We’ll implement a DFFML Source for the repos.yml files which live under
directories named after their respective GitHub orgs.
We’ll back the repos in memory when we load them in, and don’t need to support writing them back out for this source.
TOOD See https://youtu.be/VogNhBMmsNk for more details on implemention until this section gets further writing.
sources/orgs_repos_yml.py
import yaml
import pathlib
from dffml import (
config,
field,
Record,
MemorySource,
entrypoint,
Record,
MemorySource,
)
@config
class OrgsReposYAMLSourceConfig:
directory: pathlib.Path = field(
"Top level directory containing GitHub orgs as subdirectories"
)
@entrypoint("orgs.repos.yml")
class OrgsReposYAMLSource(MemorySource):
r"""
Reads from a SAP InnerSource Portal repos.json format. Each repo's
data is stored as Record feature data in memory.
Writing not implemented.
"""
CONFIG = OrgsReposYAMLSourceConfig
async def __aenter__(self):
"""
Populate the source when it's context is entered
"""
for yaml_path in self.config.directory.rglob("*.yml"):
for doc in yaml.safe_load_all(yaml_path.read_text()):
key = (
f'https://github.com/{yaml_path.parent.name}/{doc["name"]}'
)
self.mem[key] = Record(key, data={"features": doc})
self.logger.debug("%r loaded %d records", self, len(self.mem))
return self
We list all the records for a source using the DFFML command line and the Python
entry point path to the class we just implemented
(module.submodule:ClassName). Each repo is a record.
$ dffml list records \
-sources orgs=sources.orgs_repos_yml:OrgsReposYAMLSource \
-source-orgs-directory orgs/
[
{
"extra": {},
"features": {
"name": "dffml",
"owners": [
"johnandersenpdx@gmail.com"
]
},
"key": "https://github.com/intel/dffml"
},
{
"extra": {},
"features": {
"name": "cve-bin-tool",
"owners": [
"terri@toybox.ca"
]
},
"key": "https://github.com/intel/cve-bin-tool"
},
{
"extra": {},
"features": {
"name": "tpm2-pkcs11",
"owners": [
"william.c.roberts@intel.com"
]
},
"key": "https://github.com/tpm2-software/tpm2-pkcs11"
},
{
"extra": {},
"features": {
"name": "tpm2-tools",
"owners": [
"imran.desai@intel.com"
]
},
"key": "https://github.com/tpm2-software/tpm2-tools"
}
]
Writing Outputs¶
We also need to implement DFFML Source for the repos.json file which is in
the format that the frontend knows how to display.
The builtin DFFML JSON format source outputs an object, whereas the frontend expects an array. So we need to dump the Record feature data (which is where we put the metrics and repo information), to and from the file.
We’ll implement both reading and writing for this source, so that we can verify
it works easily via reading. Also because it’s easy enough to implement since
we’ll be subclassing from the FileSource and MemorySource which means we
only have to implement loading from the file descriptor (fd) and saving back
to it.
TOOD See https://youtu.be/VogNhBMmsNk for more details on implemention until this section gets further writing.
sources/sap_portal_repos_json.py
import json
from dffml import (
export,
Record,
MemorySource,
entrypoint,
Record,
MemorySource,
FileSource,
FileSourceConfig,
)
class SAPPortalReposJSONSourceConfig(FileSourceConfig):
pass # pragma: no cov
@entrypoint("sap.portal.repos.json")
class SAPPortalReposJSONSource(FileSource, MemorySource):
r"""
Reads and write from a SAP InnerSource Portal repos.json format. Each repo's
data is stored as Record feature data in memory.
"""
CONFIG = SAPPortalReposJSONSourceConfig
async def load_fd(self, fd):
# No predictions here, each repo's data is treated as a record with only
# feature data.
self.mem = {
record["html_url"]: Record(
record["html_url"], data={"features": record}
)
for record in json.load(fd)
}
self.logger.debug("%r loaded %d records", self, len(self.mem))
async def dump_fd(self, fd):
# Dump all records to the array format
json.dump(
[export(record.features()) for record in self.mem.values()], fd
)
self.logger.debug("%r saved %d records", self, len(self.mem))
Try listing all the records in the new source to verify it works.
$ dffml list records \
-sources portal=sources.sap_portal_repos_json:SAPPortalReposJSONSource \
-source-portal-filename html-client/repos.json
[
{
"extra": {},
"features": {
"_InnerSourceMetadata": {
"logo": "./images/demo/Earth.png",
"participation": [
15,
3,
7,
2,
7,
6,
11,
4,
9,
11,
4,
0,
4,
6,
3,
2,
6,
4,
3,
5,
9,
1,
2,
2,
7,
6,
7,
25,
9,
7,
9,
10,
7,
3,
8,
10,
13,
6,
5,
4,
9,
6,
8,
8,
10,
3,
3,
6,
2,
8,
12,
8
],
"score": 3900,
"topics": [
"earth",
"JavaScript",
"Sol"
]
},
"created_at": "2017-01-31T09:39:12Z",
"default_branch": "main",
"description": "Earth is the third planet from the Sun and the home-world of humanity.",
"forks_count": 331,
"full_name": "Sol/earth",
"html_url": "https://github.instance/Sol/earth",
"id": 2342,
"language": "JavaScript",
"license": null,
"name": "earth",
"open_issues_count": 98,
"owner": {
"avatar_url": "./images/demo/Sol.png",
"login": "Sol"
},
"pushed_at": "2020-10-08T12:18:22Z",
"stargazers_count": 136,
"updated_at": "2020-10-07T09:42:53Z",
"watchers_count": 136
},
"key": "https://github.instance/Sol/earth"
},
<... output clipped ...>
Querying GitHub¶
Create a directory where we’ll store all of the operations (Python functions) we’ll use to gather project data / metrics.
$ mkdir operations/
Make it a Python module by creating a blank __init__.py file in it.
$ touch operations/__init__.py
Install the PyGithub library, which we’ll use to access the GitHub API.
$ python -m pip install PyGithub
You’ll need a Personal Access Token to be able to make calls to GitHub’s API. You can create one by following their documentation.
When it presents you with a bunch of checkboxes for difference “scopes” you don’t have to check any of them, unless you want to access your own private repos, then check the repos box.
$ export GITHUB_TOKEN=<paste your personal access token here>
You’ve just pasted your token into your terminal so it will likely show up in your shell’s history. You might want to either remove it from your history, or just delete the token on GitHub’s settings page after you’re done with this tutorial.
Write a Python function which returns an object representing a GitHub repo. For simplicity of this tutorial, the function will take the token from the environment variable we just set.
operations/gh.py
import os
import dffml
import github
@dffml.op(
inputs={
"url": dffml.Definition(name="github.repo.url", primitive="string"),
},
outputs={
"owner": dffml.Definition(
name="github.org.owner_name", primitive="string"
),
"project": dffml.Definition(
name="github.repo.project_name", primitive="string"
),
},
)
def github_split_owner_project(url):
"""
Parses the owner and project name out of a GitHub URL
Examples
--------
>>> github_split_owner_project("https://github.com/intel/dffml")
('intel', 'dffml')
"""
return dict(
zip(
("owner", "project"),
tuple("/".join(url.split("/")[-2:]).split("/")),
)
)
@dffml.op(
inputs={
"org": github_split_owner_project.op.outputs["owner"],
"project": github_split_owner_project.op.outputs["project"],
},
outputs={
"repo": dffml.Definition(
name="PyGithub.Repository", primitive="object",
),
},
)
def github_get_repo(org, project):
# Instantiate a GitHub API object
g = github.Github(os.environ["GITHUB_TOKEN"])
# Make the request for the repo
return {"repo": g.get_repo(f"{org}/{project}")}
@dffml.op(
inputs={"repo": github_get_repo.op.outputs["repo"],},
outputs={
"raw_repo": dffml.Definition(
name="PyGithub.Repository.Raw", primitive="object"
),
},
)
def github_repo_raw(repo):
return {"raw_repo": repo._rawData}
# If this script is run via `python gh.py intel dffml`, it will print out the
# repo data using the pprint module.
if __name__ == "__main__":
import sys
import pprint
pprint.pprint(
github_repo_raw(github_get_repo(sys.argv[-2], sys.argv[-1])["repo"])
)
You’ll notice that we wrote a function, and then put an if statement. The
if block let’s us only run the code within the block when the script is run
directly (rather than when included via import).
If we run Python on the script, and pass an org name followed by a repo name,
our if block will run the function and print the raw data of the repsonse
received from GitHub, containing a bunch of information about the repo.
You’ll notice that the data being output here is a superset of the data we’d see
for the repo in the repos.json file. Meaning we have all the required data
and more.
$ python operations/gh.py intel dffml
{'allow_auto_merge': False,
<... output clipped ...>
'full_name': 'intel/dffml',
<... output clipped ...>
'html_url': 'https://github.com/intel/dffml',
<... output clipped ...>
'watchers_count': 135}
DataFlow¶
Let’s create a backup of the repos.json file, since we’ll be overwriting it
with our own.
$ cp html-client/repos.json repos.json.bak
We’re going to create a Python script which will use all the operations we’ve written, and the sources.
dataflow.py
import sys
import json
import asyncio
import pathlib
import dffml
# Import the sources we implemented
from sources.orgs_repos_yml import OrgsReposYAMLSource
from sources.sap_portal_repos_json import SAPPortalReposJSONSource
# Import all the operations we implemented into this file's global namespace
from operations.gh import *
# Read in the repos.json backup to learn it's format. It's in the same directory
# as this file (dataflow.py) so we can reference it by looking in the parent
# directory of this file and then down (via .joinpath()) into repos.json.bak
repos_json_bak_path = pathlib.Path(__file__).parent.joinpath("repos.json.bak")
# Read in the contents
repos_json_bak_text = repos_json_bak_path.read_text()
# Parse the contents
repos_json_bak = json.loads(repos_json_bak_text)
# We'll inspect the first element in the list to find out what keys must be
# present in the object
required_data_top_level = list(repos_json_bak[0].keys())
# It should look like this:
# required_data_top_level = [
# 'id', 'name', 'full_name', 'html_url', 'description', 'created_at',
# 'updated_at', 'pushed_at', 'stargazers_count', 'watchers_count',
# 'language', 'forks_count', 'open_issues_count', 'license',
# 'default_branch', 'owner', '_InnerSourceMetadata'
# ]
# We're first going to create output operations to grab each of the keys
# We know that _InnerSourceMetadata is not a single value, so we'll handle that
# separately and remove it from our list
required_data_top_level.remove("_InnerSourceMetadata")
# Make a list of any imported OpeartionImplementations (functions decorated with
# @op()) from any that are in the global namespace of this file
operation_implementations = dffml.opimp_in(sys.modules[__name__])
# Create a DataFlow using every operation in all the modules we imported. Also
# use the remap operation
dataflow = dffml.DataFlow(
dffml.remap,
*operation_implementations,
# The remap operation allows us to specify which keys should appear in the
# outputs of each dataflow run. We do that by configuring it to use a
# subflow, which is a dataflow run within a dataflow.
# TODO(pdxjohnny) Remove .export() after unifying config code.
configs={
dffml.remap.op.name: {
# Our subflow will run the get_single operation, which grabs one
# Input object matching the given definition name. The one Input we
# grab at first is the raw ouput of the PyGithub Repository object.
"dataflow": dffml.DataFlow(
dffml.GetSingle,
seed=[
dffml.Input(
value=[github_repo_raw.op.outputs["raw_repo"].name],
definition=dffml.GetSingle.op.inputs["spec"],
)
],
).export()
}
},
seed=[
dffml.Input(
# The output of the top level dataflow will be a dict where the keys
# are what we give here, and the values are the output of a call to
# traverse_get(), where the keys to traverse are the values we give
# here, and the dict being traversed the results from the subflow.
# {key: traverse_get(subflow_results, *value)}
value={
key: [github_repo_raw.op.outputs["raw_repo"].name, key]
for key in required_data_top_level
},
definition=dffml.remap.op.inputs["spec"],
)
],
)
# Path to the output repos.json file
repos_json_path = pathlib.Path(__file__).parent.joinpath(
"html-client", "repos.json"
)
async def main():
# Clear the file so we overwrite with new data
repos_json_path.write_text("[]")
# Create and enter our sources (__aenter__()) following the Double Context
# Entry pattern (see tutorial page for more details)
async with OrgsReposYAMLSource(
directory=pathlib.Path(__file__).parent.joinpath("orgs")
) as input_source, SAPPortalReposJSONSource(
filename=repos_json_path, readwrite=True,
) as output_source:
# Second context entry
async with input_source() as input_source_ctx, output_source() as output_source_ctx:
# Run the dataflow
async for ctx, results in dffml.run(
dataflow,
{
# We will run the dataflow on all input repos at the same
# time. The dataflow will run on each repo / record
# concurrently. We do this by creating a dictionary where
# each key is an InputSetContext, a RecordInputSetContext to
# be excat, since the context for each run is tied to the
# record / repo.
dffml.RecordInputSetContext(record): [
# Create a list of Inputs for each record's context. The
# only input we add at this time is the url of the repo.
dffml.Input(
value=record.key,
definition=dataflow.definitions["github.repo.url"],
)
]
async for record in input_source_ctx.records()
},
strict=False,
):
# Update the feature data of the record. The feature data is
# what we are writing out to repos.json in the source we
# implemented.
ctx.record.evaluated(results)
# Print results for debugging purposes
print(ctx.record.export())
# Save to output repos.json
await output_source_ctx.update(ctx.record)
if __name__ == "__main__":
asyncio.run(main())
We can run the file the run the dataflow on all the input repos and save the
results to repos.json.
$ python dataflow.py
If you go to http://127.0.0.1:8080
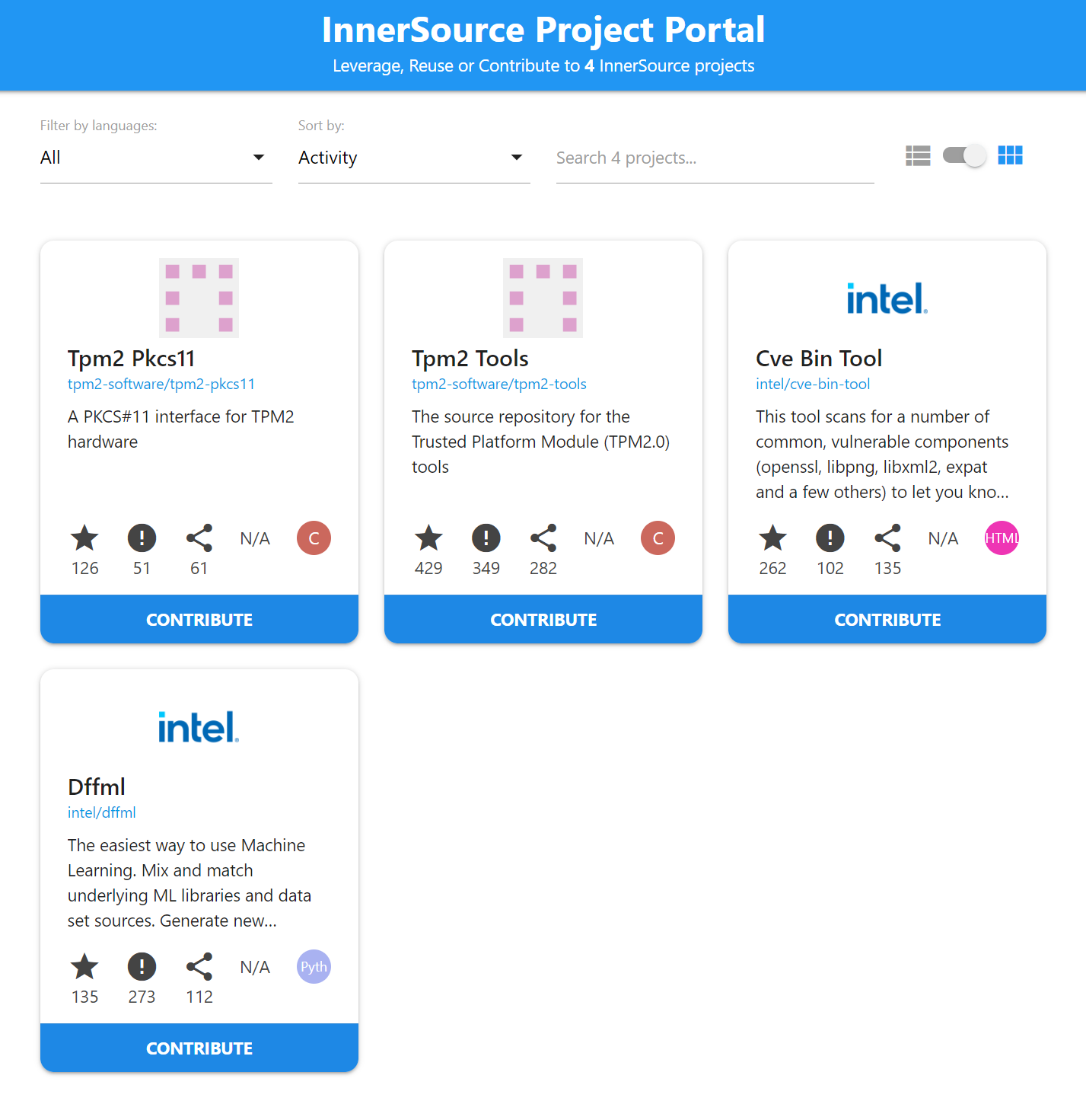
We can also export the dataflow for use with the CLI, HTTP service, etc.
TODO Add link to webui when complete. It will be used for editing dataflows. ETA Oct 2021.
$ dffml service dev export dataflow:dataflow | tee dataflow.json
We can run the dataflow using the DFFML command line interface rather than running the Python file.
The following command replicates loading from the orgs/ source and updating
the repos.json source. Just as we did in Python, we add the record key to
each dataflow run as an input with the definition being github.repo.url.
You can add -log debug to see verbose output.
$ dffml dataflow run records all \
-dataflow dataflow.json \
-record-def "github.repo.url" \
-sources \
orgs=sources.orgs_repos_yml:OrgsReposYAMLSource \
portal=sources.sap_portal_repos_json:SAPPortalReposJSONSource \
-source-orgs-directory orgs/ \
-source-portal-filename html-client/repos.json \
-source-portal-readwrite \
-update
If you want to run the dataflow on a single repo and add the data to the repos.json file, you can do it as follows.
$ dffml dataflow run records set \
-dataflow dataflow.json \
-record-def "github.repo.url" \
-sources \
portal=sources.sap_portal_repos_json:SAPPortalReposJSONSource \
-source-portal-filename html-client/repos.json \
-source-portal-readwrite \
-update \
-keys \
https://github.com/intel/dffml
If you want to run the dataflow on a single repo, without updating the source, you can do it as follows, by omiting the source related arguments.
$ dffml dataflow run records set \
-dataflow dataflow.json \
-record-def "github.repo.url" \
-keys \
https://github.com/intel/dffml