Introduction
Compute Library for Deep Neural Networks (clDNN) is a middle-ware software for accelerating DNN inference on Intel® HD and Iris™ Pro Graphics. This project includes CNN primitives implementations on Intel GPUs with C and C++ interfaces.
clDNN Library implements set of primitives:
- Convolution
- Fully connected (inner product)
- Pooling
- average
- maximum
- Normalization
- across channel
- within channel
- batch
- Activation
- logistic
- tanh
- rectified linear unit (ReLU)
- softplus (softReLU)
- abs
- square
- sqrt
- linear
- Softmax
- Crop
- Deconvolution
- Depth concatenation
- Eltwise
- ROI pooling
- Simpler NMS
- Prior box
- Detection output
With this primitive set, user can build and execute most common image recognition, semantic segmentation and object detection networks topologies like:
- Alexnet
- Googlenet(v1-v3)
- ResNet
- VGG
- faster-rCNN and other.
Programming Model
Intel® clDNN is graph oriented library. To execute CNN you have to build, compile graph/topology and run to get results.
Terminology:
- Primitive - dnn base functionality i.e. convolution, pooling, softmax.
- Data - special primitive type representing primitive parameters (weights and biases), inputs and outputs
- Engine - type of accelerator that is executing network. Currently ocl engine is the only available.
- Topology - container of primitives, data, and relations between them. Topology represents graph.
- Program - optional step between Topology and Network. It is compiled Topology without memory allocation.
- Network - compiled Topology with memory allocation. Ready to be executed. During compilation, buidling parameters trigger special optimizations like fusing, data reordering.
Execution Steps:
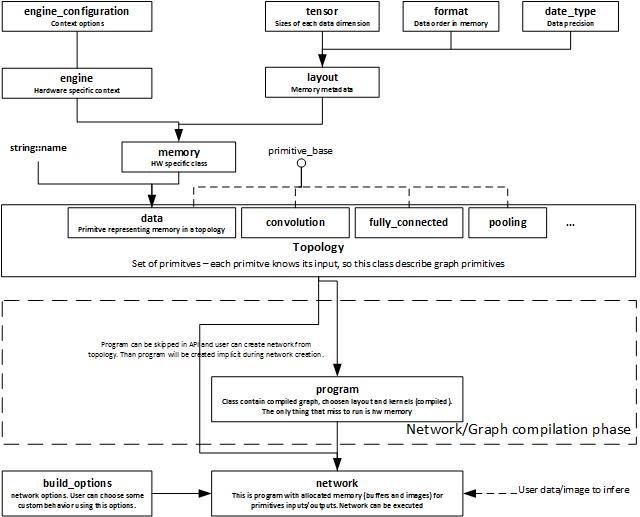
- Create Engine
- Declare or define primitives parameters (weights and biases) if needed.
- Create primitives. It is required to provide name for each primitive. This is a name of primitive which output will be input to current one. Name can be used before primitive definition.
- Create topology
- Add primitives to topology
- Build Network from topology
- Set Inputs data
- Execute Network
Graph compilation
If user choose build option optimize_data when program is being created - explicit or implicit over network creation, clDNN perform some graph optimizations as follows:
- Stage 0: Graph initiation:
- build nodes from primitives
- node replacement:
- replace each split node with series of crop nodes. Name of crop primitive will be concatenation of split + port names.
- replace upsampling node with deconvolution node if upsampling mode is bilinear.
- set outputs - mark nodes that are defined by user as output (blocks fusing etc) or have no users (leafs).
- calculate processing order - using dfs on graph to establish processing order
- Stage 1: Priorboxes:
- priorbox is primitive that is executed during network compilation. Node is removed from a network execution.
- Stage 2: Graph analysis:
- mark constatns
- mark data flow
- mark dominators
- Stage 3: Trimming:
- apply backward bfs on each output to find unnecessary nodes/branches, then remove those.
- Stage 4: Inputs and biases:
- reorder input - format of convolution's input/output is being selected.
- reorder biases for conv,fc and deconv nodes
- Stage 5: Redundant reorders:
- previous stages can provide additional reorders due to format changes per primitive. This stage removes redundant and fuses series of reorders into one.
* Stage 6: Constant propagation: - prepare padding - goes thrugh all primitves and checks if its user requires padding, if so, set output padding.
- prepare depthwise separable opt - if split param is greater than 16 and number of IFM <= 8*split in conv or deconv, this stage changes execution from multi kernels into one.
- constant propagation - replace constant nodes, that are not outputs with data type nodes. Constant primitive is the primitive that doesn't depend on any non-constant primitive and doesn't have to be executed: priorbox, data.
- previous stages can provide additional reorders due to format changes per primitive. This stage removes redundant and fuses series of reorders into one.
- Stage 7: Fusing:
- buffer fusing
- concat - if concatenation is the only user of its dependencies then remove concat node and setting proper output paddings in every dependencies.
- crop - if crop has only one dependecy, and its users doesn't require padding, remove crop and set proper output padding in its dependecy.
- reorder - if primitive before reorder supports different input vs output type reorder can be fused with previous node.
- primitive fusing - right now this stage fuses activation node with previous node only, only if previous node supports activation fusing.
- buffer fusing
- Stage 8: Compile graph:
- at this stage using kernel selector, graph chooses the best kernel implementation for each node.
- Stage 9: reorder weights:
- at this stage weights are converted into format suitable for selected kernel implementation.
- Stage 10 & 11: Redundant reorders and constant propagation:
- check again if whole graph compilation didn't provide any redundant reorders and constants.
- Stage 12: Compile program:
- at this stage engine compiles cl_kernels.
