Small Scale Benchmarks
We present here the results of an exhaustive evaluation, comparing SVS to other implementations in million scale datasets.
System Setup and Datasets
We run our experiments on a 3rd generation Intel® Xeon® 8360Y CPU @2.40GHz with 36 cores (single socket), equipped with 256GB DDR4 memory per socket @2933MT/s speed, running Ubuntu 22.04. [1] [2]
We use numactl to ran all experiments in a single socket (see NUMA Systems for details).
We consider datasets of diverse dimensionalities and number of vectors (see Datasets for details):
glove-25-1.2M (25 dimensions, 1 million points)
glove-50-1.2M (50 dimensions, 1 million points)
deep-96-10M (96 dimensions, 10 million points)
sift-128-1M (128 dimensions, 1 million points)
gist-960-1.0M (960 dimensions, 1 million points)
Comparison to Other Implementations
We compare SVS to five widely adopted approaches: Vamana [SDSK19], HSNWlib [MaYa18], FAISS-IVFPQfs [JoDJ19], ScaNN [GSLG20], and NGT [IwMi18]. We use the implementations available through ANN-Benchmarks (commit 167f129 , October 4th 2022) and for SVS we use commit ad821d8. See Parameters Setting for details on the evaluated configurations for each method. We run the evaluation in the three different query modes. [3]
Results summary:
SVS establishes a new SOTA at very diverse scales (dataset dimensionality and number of points) revealing its versatility and suitability for contrasting use cases (see results below).
The table below summarizes the QPS boost with respect to SVS closest competitor for a search accuracy of 0.9 10 recall at 10.
Full query batch size |
Query batch size = 128 |
Single query |
||||
SVS QPS |
QPS w.r.t. 2nd |
SVS QPS |
QPS w.r.t. 2nd |
SVS QPS |
QPS w.r.t. 2nd |
|
deep-96-10M |
648122 |
5.49x |
391739 |
6.28x |
18440 |
1.92x |
glove-25-1.2M |
1224266 |
1.15x |
711890 |
1.51x |
34118 |
1.16x |
glove-50-1.2M |
558606 |
1.78x |
376642 |
2.28x |
17268 |
1.10x |
gist-960-1.0M |
56717 |
1.64x |
62821 |
3.00x |
1857 |
0.42x |
sift-128-1M |
852705 |
1.84x |
512785 |
2.15x |
21969 |
0.95x |
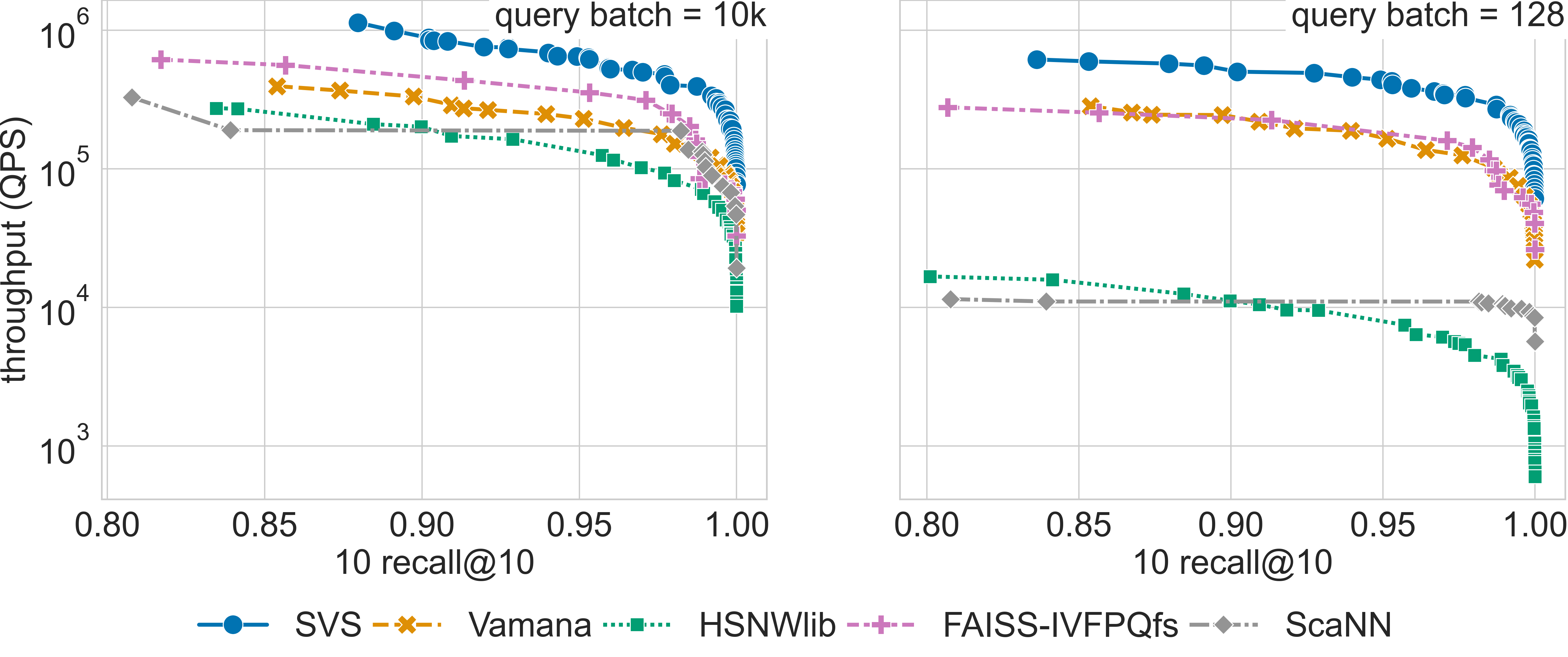
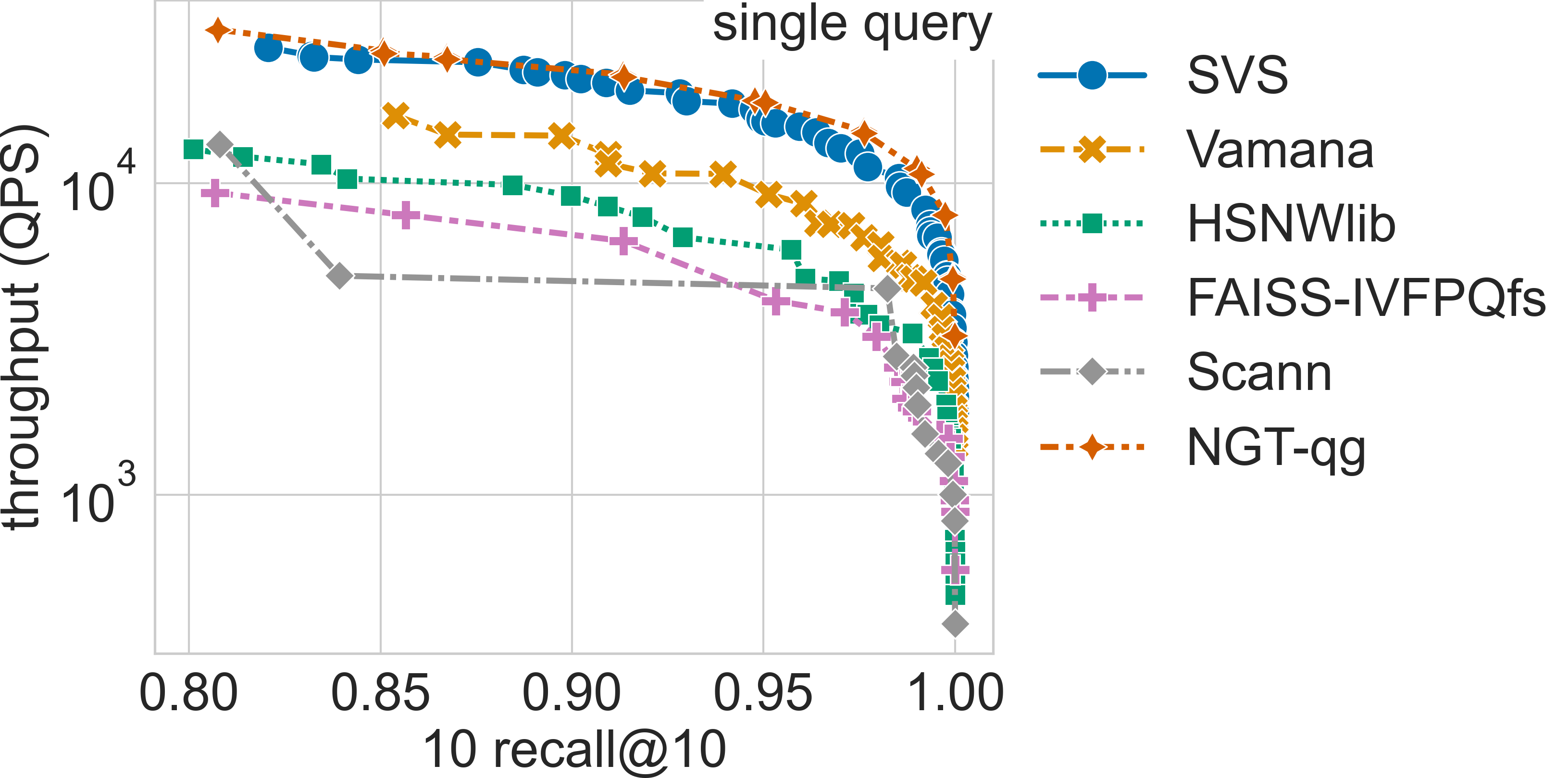
The full query batch is 10k queries for all datasets except for gist-960-1.0M which has a query set of size 1000 (see Datasets for details).
Click on the triangles to see the throughput vs recall curves for each dataset.
Results for the deep-96-10M dataset
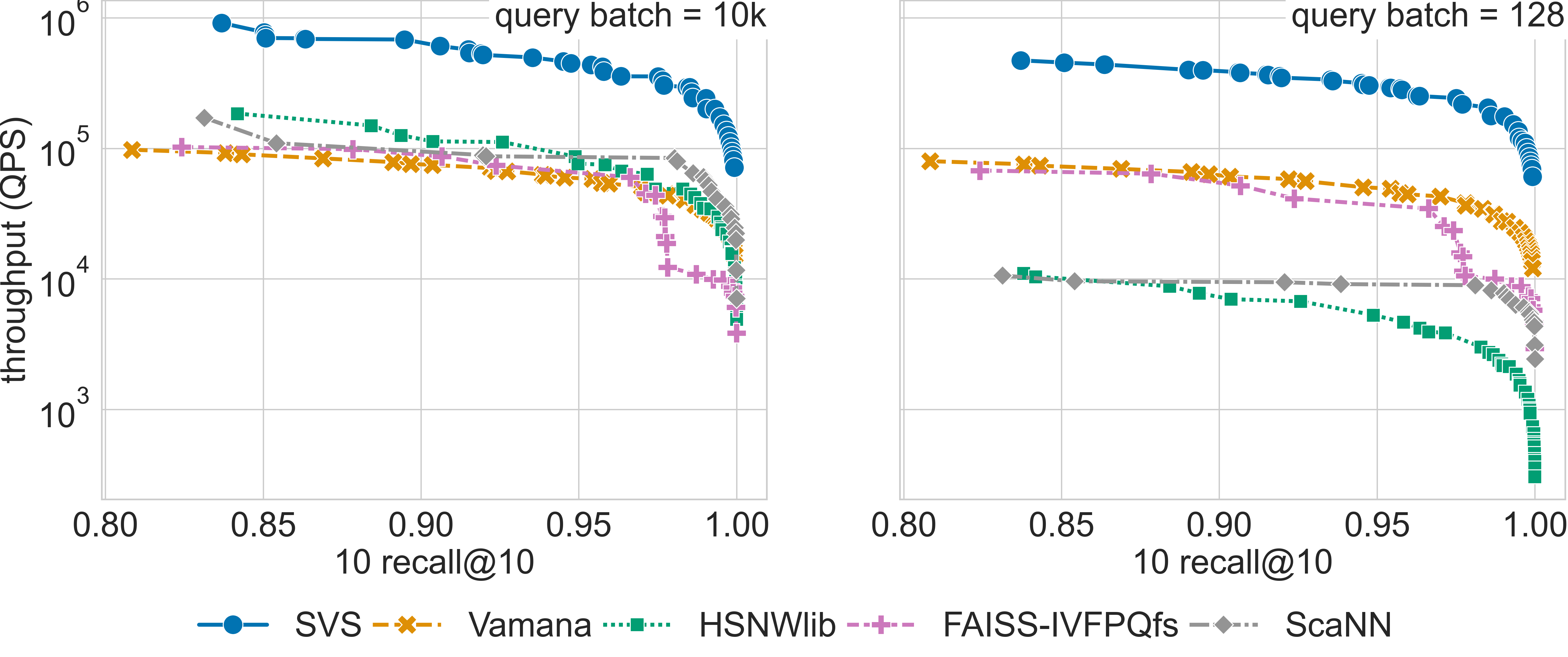
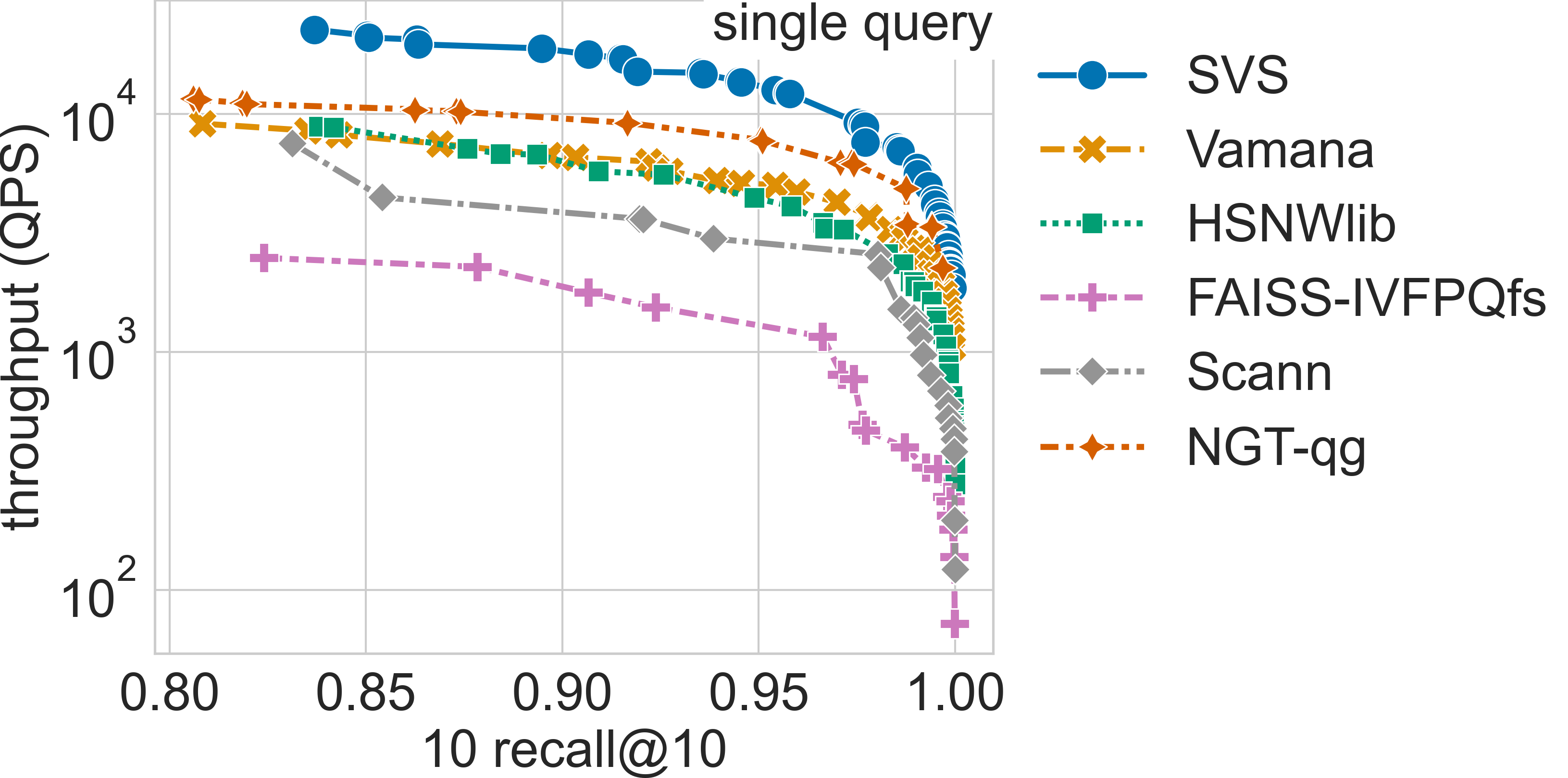
Results for the glove-25-1.2M dataset
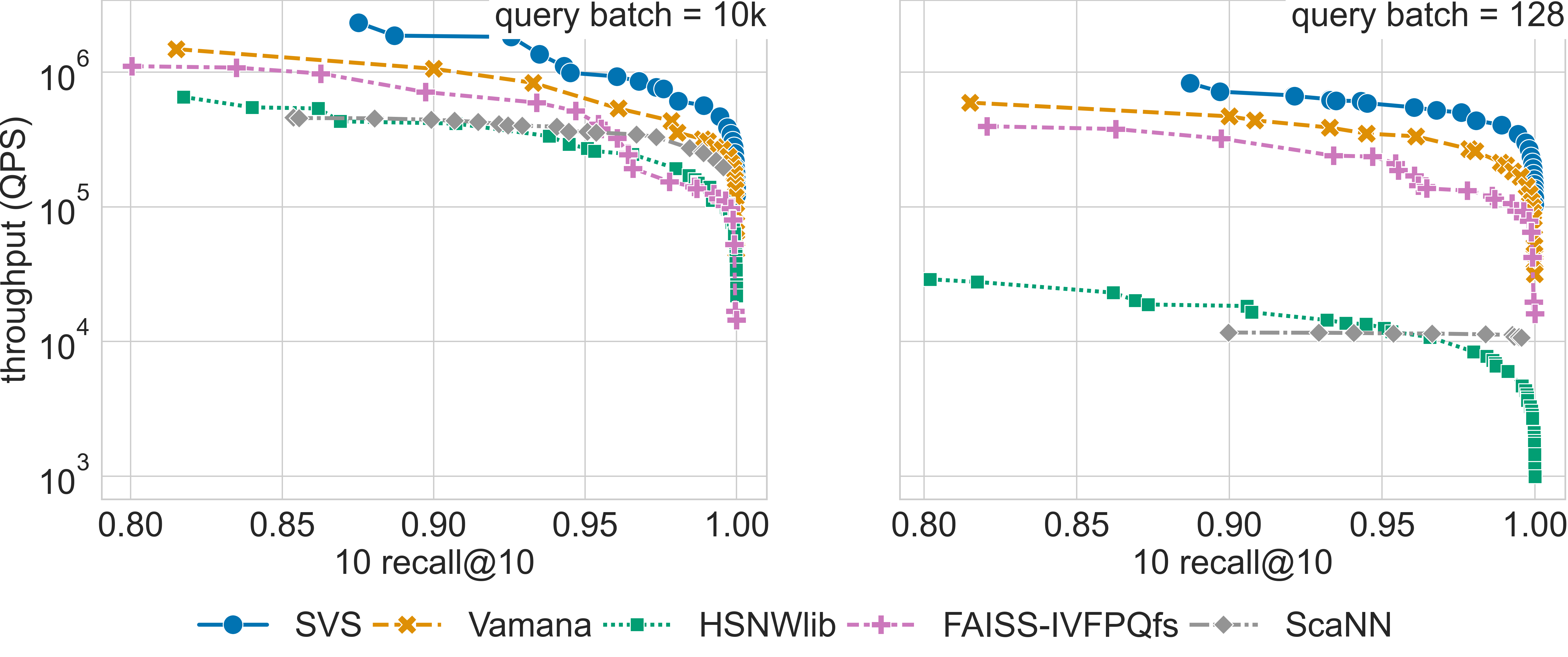
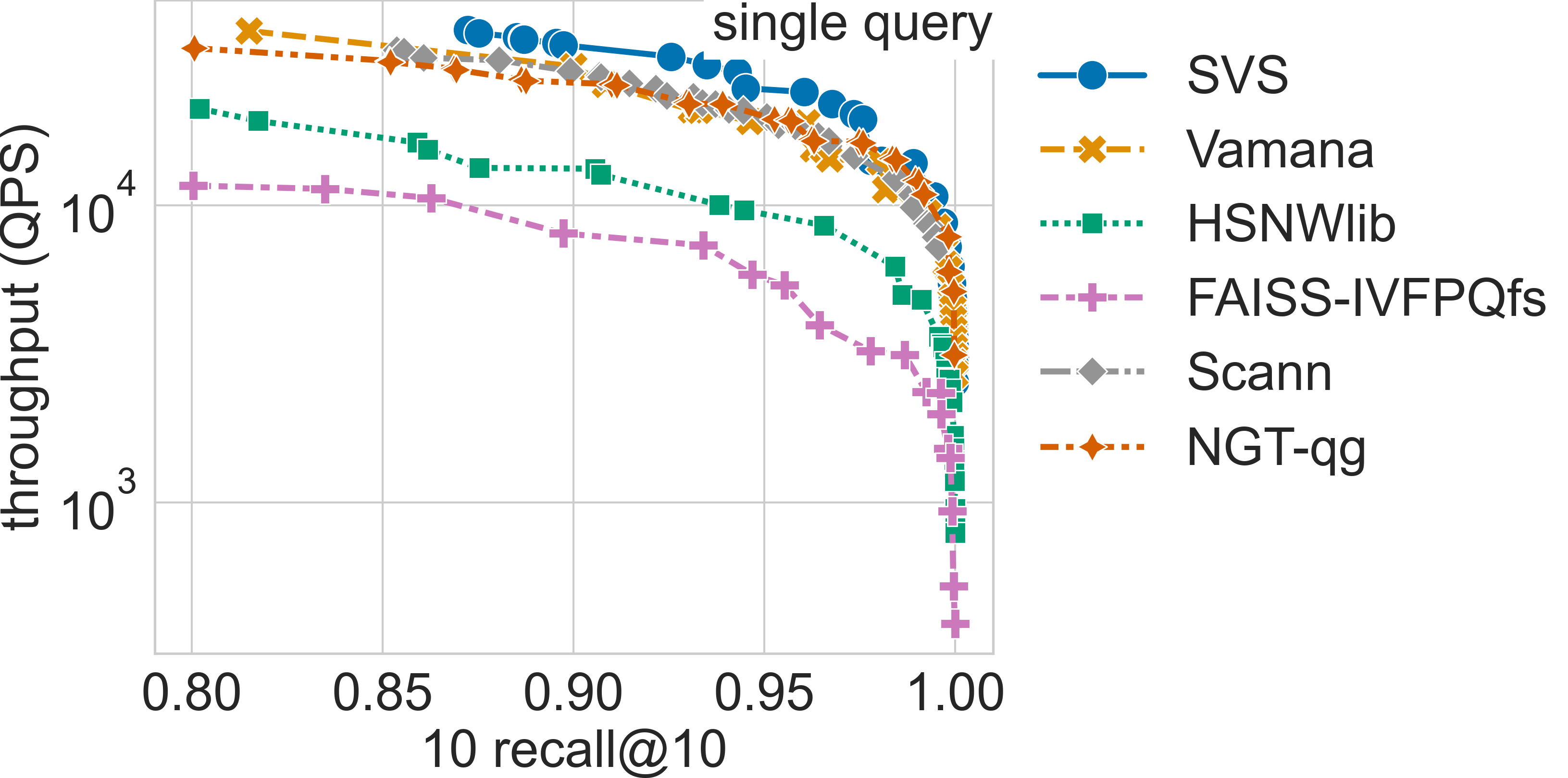
Results for the glove-50-1.2M dataset
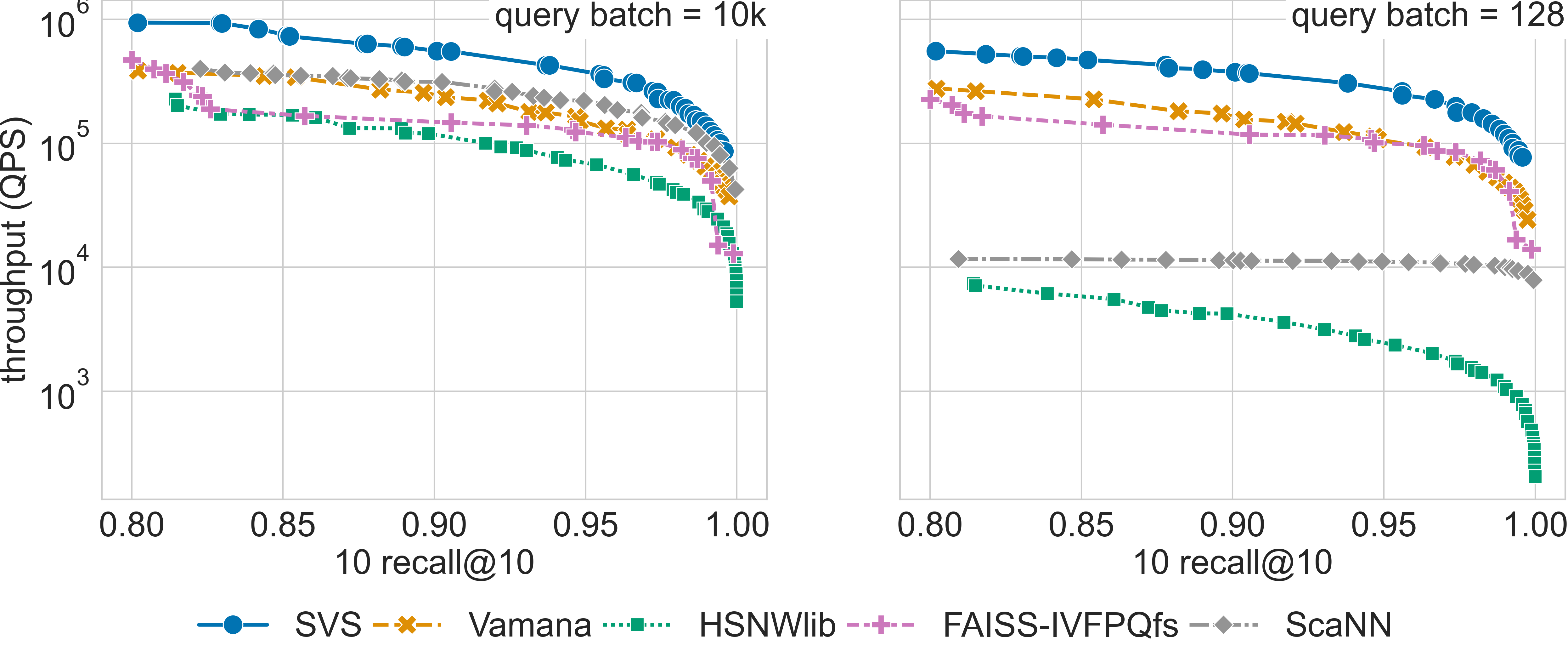
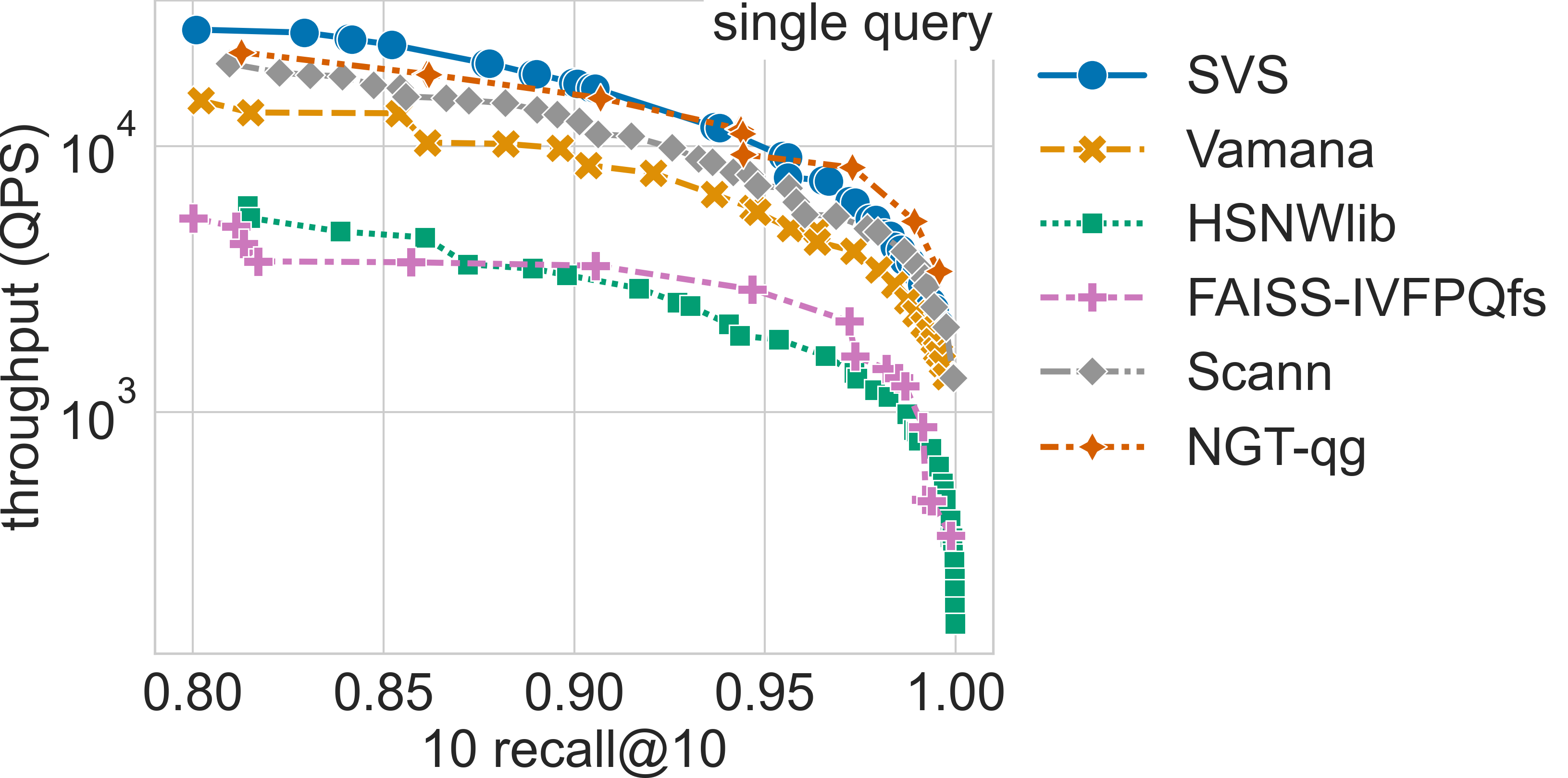
Results for the gist-960-1.0M dataset
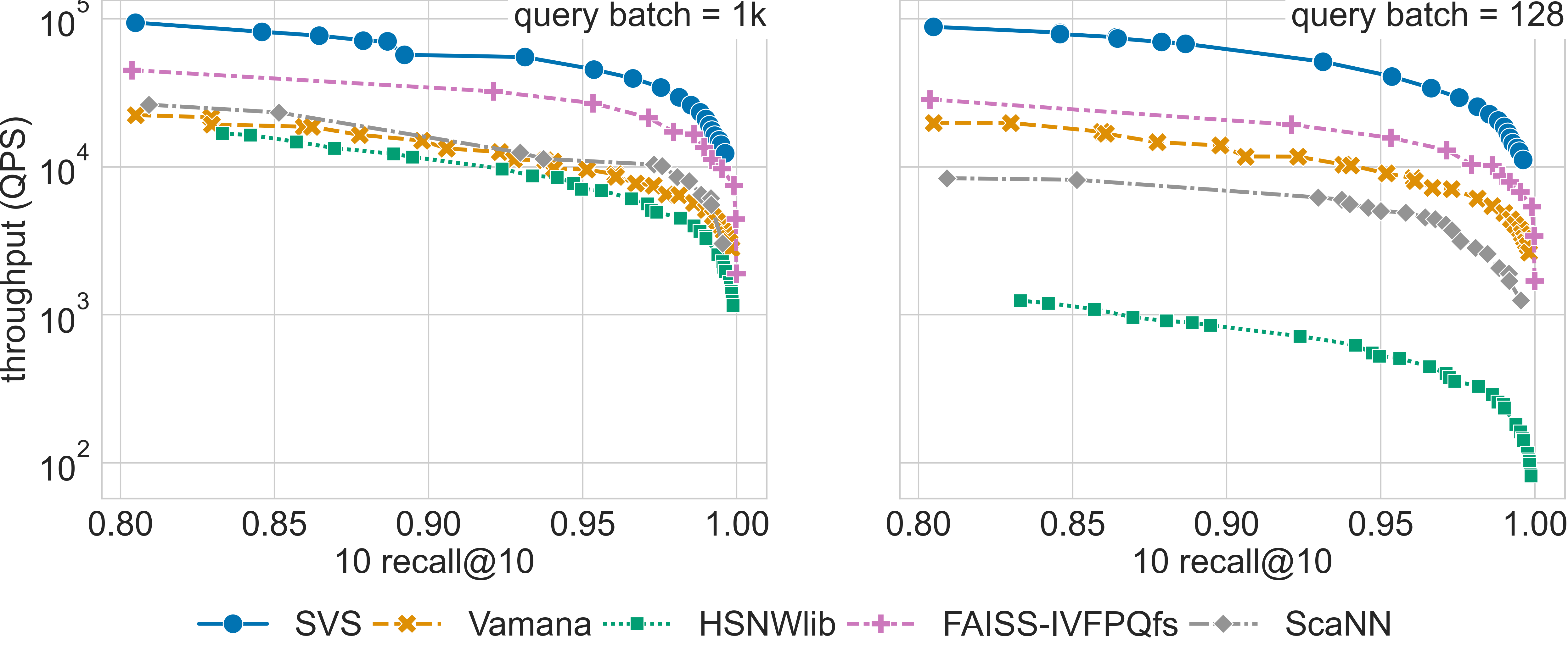
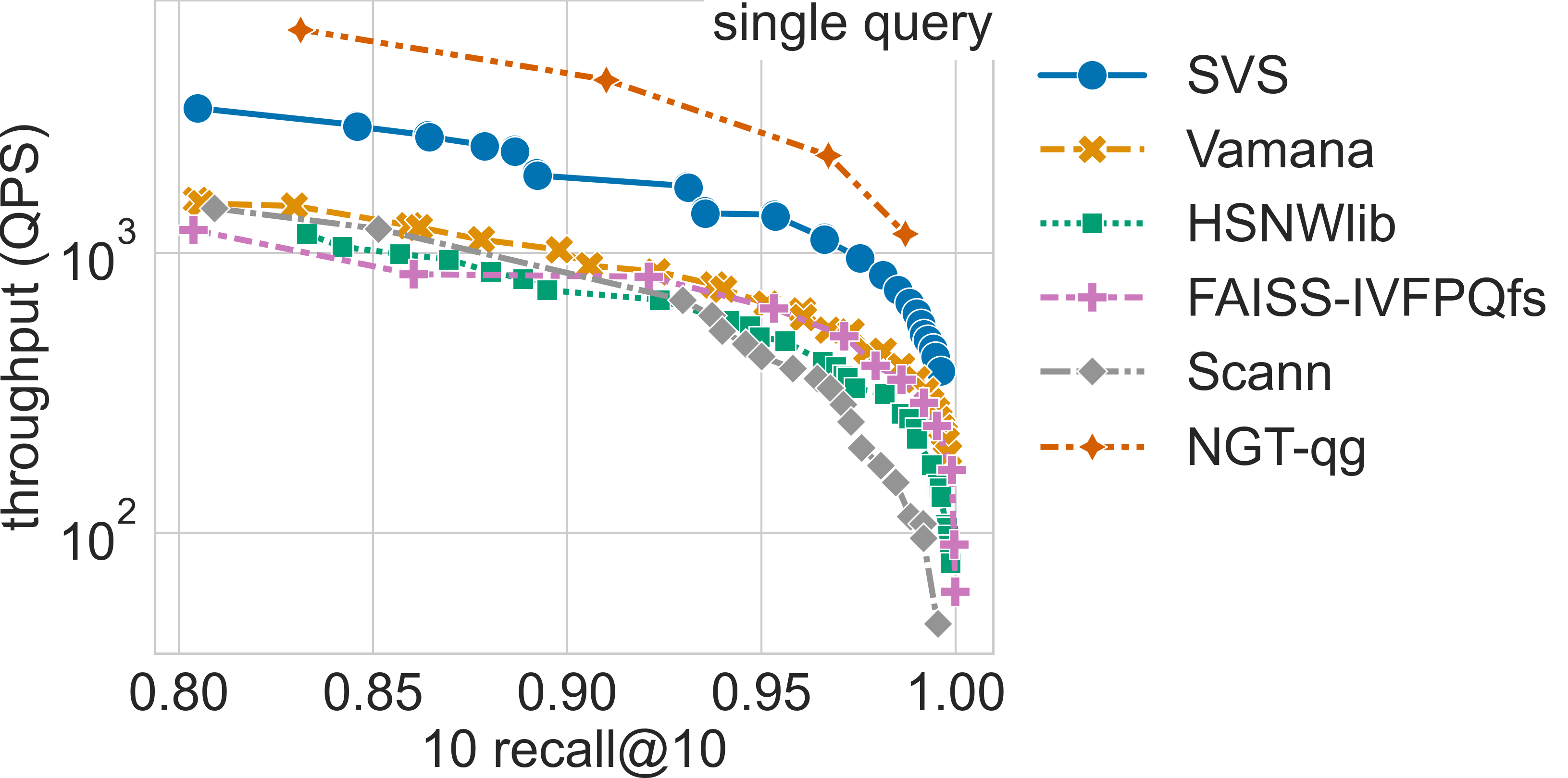
Results for the sift-128-1M dataset
Parameters Setting
We adopt the standard ANN-benchmarks [AuBF20] protocol and generate Pareto curves of QPS vs. recall for the considered
methods and datasets. For the graph-based methods (HSNWlib, Vamana, SVS) we use the same graph_max_degree values (32, 64 and 128).
For IVFPQfs, ScaNN and NGT-qg we consider the provided yaml configuration files.
For SVS, we include various LVQ settings (LVQ-8, LVQ-4x4, LVQ-4x8, and LVQ8x8) as well as float16 and float32 encodings.
LVQ-compressed vectors are padded to half cache lines (padding = 32).
Footnotes