The CRC64 Values Used in End-To-End mode
Compress and Verify (CnV) was developed before the end-to-end (e2e) feature with CRC64 checksums was introduced. The e2e feature allows customers to supply the polynomial. While this is useful for some customers, it presents two problems for CnV.
If CnV included CRC64 with a customer-supplied polynomial, the following situations may arise.
The polynomial may be poorly chosen, resulting in higher levels of collisions.
A CnV solution with different polynomials may result in failure to detect an error based solely on the polynomials, resulting in inconsistent behavior.
The Empirical Study
Dataset Generation
The datasets were created with the following parameters:
Characters |
Dataset Length |
|---|---|
Full ASCII in pseudo-random order |
4096, 8192, 32767, 65536, 40960, 81920, 32767, 655360 |
Printable ASCII in pseudo-random order |
4096, 8192, 32767, 65536, 40960, 81920, 32767, 655360 |
Dataset Modification
A second dataset was created with the following changes:
do { copy_start = (rand()%(bff_sz - 1024))+10; copy_len = (rand()%(256))+1; copy_offset = rand()%(copy_start)+10; for ( i = 0; i < copy_len; i++ ) { bff2[i+copy_offset] = bff[i+copy_start]; } } while (memcmp( bff, bff2, bff_sz ) == 0 );
This provides a second buffer with the following properties:
A subset of the dataset has been copied from one location to another pseudorandom location.
The length of the copied data is limited to be within the range of 1 to 256.
The start and offset are set to ensure the length of the second modified buffer matches the original unmodified buffer.
Pictorially, this looks like:
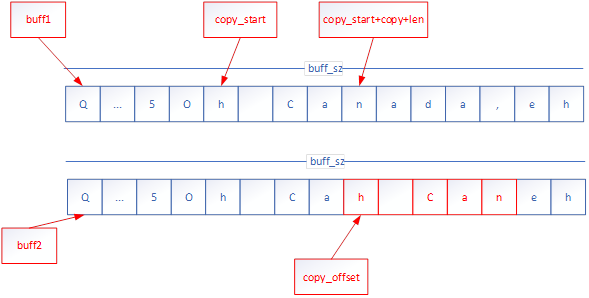
Scope of Experiment
Collisions
Checksum |
Number of Collisions |
Rate of Collisions (per billion) |
P |
|---|---|---|---|
Adler32 |
115458 |
< 176 |
1.7 5051E-07 |
CRC32 |
122 |
< 0.3 |
2.2 2196E-10 |
xxhash |
157 |
< 0.3 |
2.8 7547E-10 |
The number of datasets with collisions had collisions with more than one algorithm.
Details - Total collisions by dataset size
Size (octets) |
Adler32 collision count |
CRC32 collision count |
XXHash32 collision count |
|---|---|---|---|
4096 |
28898 |
25 |
32 |
8192 |
27907 |
34 |
44 |
32768 |
27281 |
32 |
31 |
64536 |
27208 |
22 |
30 |
40960 |
1067 |
3 |
5 |
81920 |
1028 |
2 |
4 |
327680 |
1034 |
3 |
6 |
645360 |
1035 |
1 |
5 |
Details - Total datasets by dataset size
Dataset size (octets) |
Datasets |
|---|---|
4096 |
124,224,000,000 |
8192 |
122,679,000,000 |
32768 |
122,324,000,000 |
64536 |
122,084,000,000 |
40960 |
14,536,000,000 |
81920 |
14,320,000,000 |
327680 |
14,261,000,000 |
645360 |
14,031,000,000 |