Distillation
Introduction
Distillation is one of popular approaches of network compression, which transfers knowledge from a large model to a smaller one without loss of validity. As smaller models are less expensive to evaluate, they can be deployed on less powerful hardware (such as a mobile device). Graph shown below is the workflow of the distillation, the teacher model will take the same input that feed into the student model to produce the output that contains knowledge of the teacher model to instruct the student model.
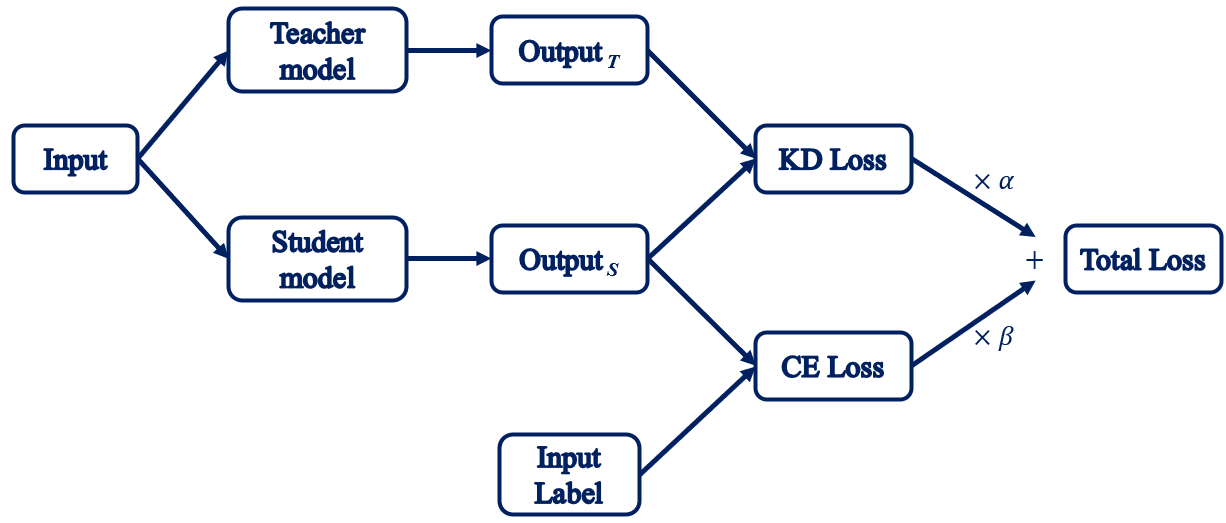
Intel® Neural Compressor supports Knowledge Distillation, Intermediate Layer Knowledge Distillation and Self Distillation algorithms.
Knowledge Distillation
Knowledge distillation is proposed in Distilling the Knowledge in a Neural Network. It leverages the logits (the input of softmax in the classification tasks) of teacher and student model to minimize the the difference between their predicted class distributions, this can be done by minimizing the below loss function.
$$L_{KD} = D(z_t, z_s)$$
Where $D$ is a distance measurement, e.g. Euclidean distance and Kullback–Leibler divergence, $z_t$ and $z_s$ are the logits of teacher and student model, or predicted distributions from softmax of the logits in case the distance is measured in terms of distribution.
Intermediate Layer Knowledge Distillation
There are more information contained in the teacher model beside its logits, for example, the output features of the teacher model’s intermediate layers often been used to guide the student model, as in Patient Knowledge Distillation for BERT Model Compression and MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices. The general loss function for this approach can be summarized as follow.
$$L_{KD} = \sum\limits_i D(T_t^{n_i}(F_t^{n_i}), T_s^{m_i}(F_s^{m_i}))$$
Where $D$ is a distance measurement as before, $F_t^{n_i}$ the output feature of the $n_i$’s layer of the teacher model, $F_s^{m_i}$ the output feature of the $m_i$’s layer of the student model. Since the dimensions of $F_t^{n_i}$ and $F_s^{m_i}$ are usually different, the transformations $T_t^{n_i}$ and $T_s^{m_i}$ are needed to match dimensions of the two features. Specifically, the transformation can take the forms like identity, linear transformation, 1X1 convolution etc.
Self Distillation
Self-distillation ia a one-stage training method where the teacher model and student models can be trained together. It attaches several attention modules and shallow classifiers at different depths of neural networks and distills knowledge from the deepest classifier to the shallower classifiers. Different from the conventional knowledge distillation methods where the knowledge of the teacher model is transferred to another student model, self-distillation can be considered as knowledge transfer in the same model, from the deeper layers to the shallower layers.
The additional classifiers in self-distillation allow the neural network to work in a dynamic manner, which leads to a much higher acceleration.
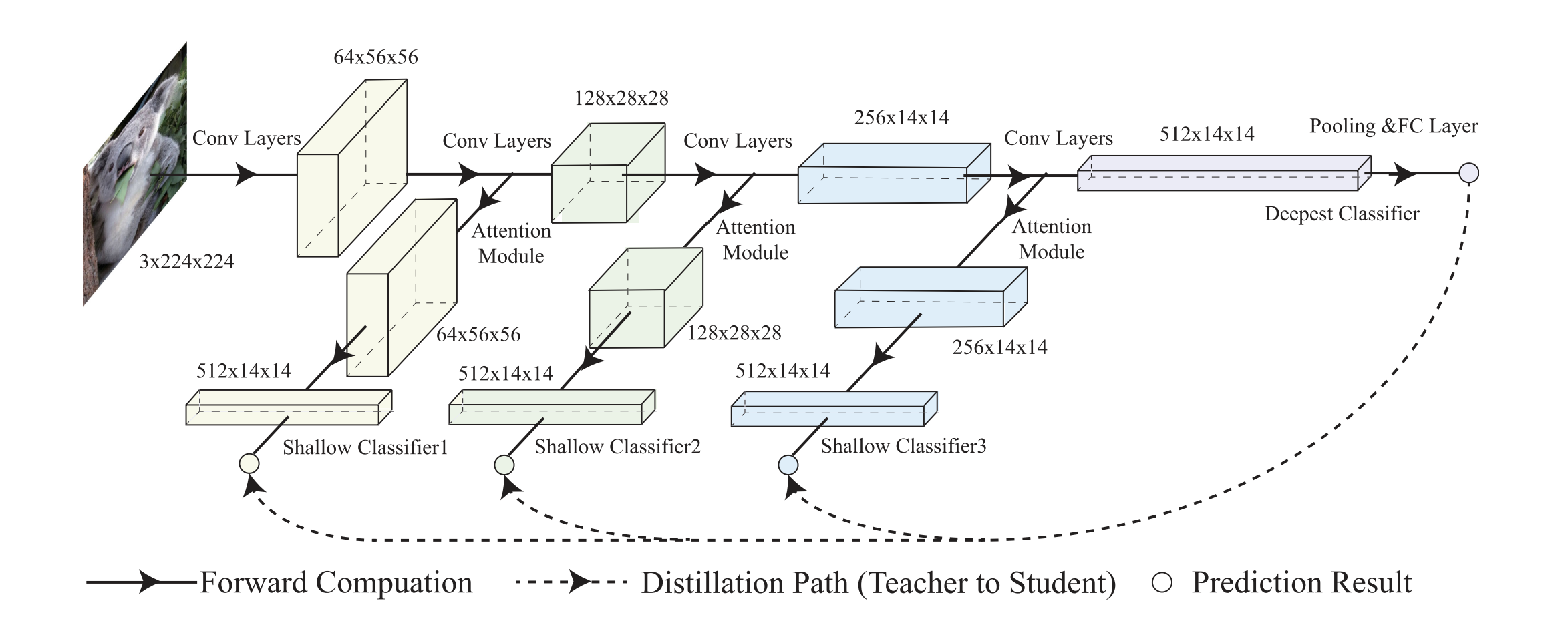
Architecture from paper Self-Distillation: Towards Efficient and Compact Neural Networks
Distillation Support Matrix
| Distillation Algorithm | PyTorch | TensorFlow |
|---|---|---|
| Knowledge Distillation | ✔ | ✔ |
| Intermediate Layer Knowledge Distillation | ✔ | Will be supported |
| Self Distillation | ✔ | ✖ |
Get Started with Distillation API
User can pass the customized training/evaluation functions to Distillation for flexible scenarios. In this case, distillation process can be done by pre-defined hooks in Neural Compressor. User needs to put those hooks inside the training function.
Neural Compressor defines several hooks for user pass
on_train_begin() : Hook executed before training begins
on_after_compute_loss(input, student_output, student_loss) : Hook executed after each batch inference of student model
on_epoch_end() : Hook executed at each epoch end
Following section shows how to use hooks in user pass-in training function:
def training_func_for_nc(model):
compression_manager.on_train_begin()
for epoch in range(epochs):
compression_manager.on_epoch_begin(epoch)
for i, batch in enumerate(dataloader):
compression_manager.on_step_begin(i)
......
output = model(batch)
loss = ......
loss = compression_manager.on_after_compute_loss(batch, output, loss)
loss.backward()
compression_manager.on_before_optimizer_step()
optimizer.step()
compression_manager.on_step_end()
compression_manager.on_epoch_end()
compression_manager.on_train_end()
...
In this case, the launcher code for Knowledge Distillation is like the following:
from neural_compressor.training import prepare_compression
from neural_compressor.config import DistillationConfig, KnowledgeDistillationLossConfig
distil_loss_conf = KnowledgeDistillationLossConfig()
conf = DistillationConfig(teacher_model=teacher_model, criterion=distil_loss_conf)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.0001)
compression_manager = prepare_compression(model, conf)
model = compression_manager.model
model = training_func_for_nc(model)
eval_func(model)
For Intermediate Layer Knowledge Distillation or Self Distillation, the only difference to above launcher code is that distil_loss_conf should be set accordingly as shown below. More detailed settings can be found in this example for Intermediate Layer Knowledge Distillation and this example for Self Distillation.
from neural_compressor.config import (
IntermediateLayersKnowledgeDistillationLossConfig,
SelfKnowledgeDistillationLossConfig,
)
# for Intermediate Layer Knowledge Distillation
distil_loss_conf = IntermediateLayersKnowledgeDistillationLossConfig(layer_mappings=layer_mappings)
# for Self Distillation
distil_loss_conf = SelfKnowledgeDistillationLossConfig(layer_mappings=layer_mappings)
Examples
Distillation PyTorch Examples
Distillation TensorFlow Examples
Distillation Examples Results