Application Tuning
This chapter describes techniques you may employ to optimize your application.
Platform-Level Optimizations
This section describes platform-level optimizations required to achieve the best performance.
BIOS Configuration
In some cases, maximum performance may only be achieved with the following BIOS configuration settings:
CPU Power and Performance:
Intel® SpeedStep® technology is disabled
All C-states are disabled
Max CPU Performance is selected
Core Selection
Using physical cores as opposed to hyper threads may result in higher performance.
Memory Configuration
Ensure that memory is not a bottleneck. For instance, ensure that all CPU nodes have enough local memory and can take advantage of available memory channels.
Important
For optimal performance it is recommended to populate all the DIMMs around the CPU sockets in use.
Payload Alignment
For optimal performance, data pointers should be at least 8-byte aligned. In some cases, this is a requirement. Refer to the API for details.
For optimal performance, all data passed to the Intel QuickAssist Technology engines should be aligned to 64B. The Intel QuickAssist Technology Cryptographic API Reference Manual and the Intel QuickAssist Technology Data Compression API Reference Manual document the memory alignment requirements of each data structure submitted for acceleration.
Note
The driver, firmware, and hardware handle unaligned payload memory without any functional issue but performance will be impacted.
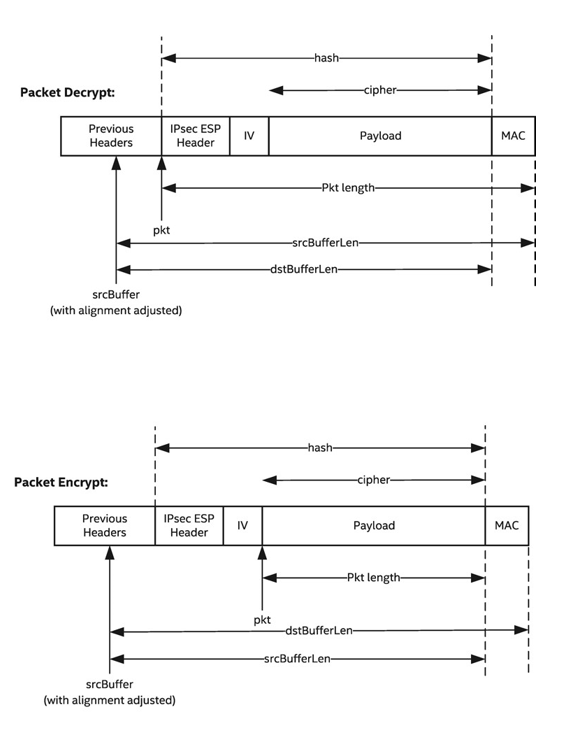
It is common that packet payloads will not be aligned on a 64B boundary in memory, as the alignment usually depends upon which packet headers are present. In general, the mitigation for handling this is to adjust the buffer pointer, length and cipher offsets passed to hardware to make the pointer aligned. This works on the assumption that there is a pointer in the packet, before the payload, that is 64B aligned. See the diagram below for an illustration of adjusted alignment in the context of encrypt/decrypt of an IPsec packet.
NUMA Awareness
For a dual processor system, memory allocated for data submitted to the acceleration device should be allocated on the same node as the attached acceleration device. This is because it’s slower to fetch data from or write data to the remote node’s memory.
The memory allocation APIs provide NUMA-aware memory allocation functions, which help minimize memory access latency and maximize throughput by ensuring memory is allocated close to the QAT device.
The qaeMemAllocNUMA() function allows applications to allocate
DMA-able memory on a specific NUMA node, ensuring data locality with
the QAT device.
Note
When using VFIO mode, the ‘node’ parameter in qaeMemAllocNUMA() is
not used. Memory is allocated based on the calling thread’s NUMA affinity
(first-touch policy).
For best performance:
Bind your application to the same NUMA node as the QAT device.
You can check the QAT device’s NUMA node at:
/sys/bus/pci/devices/<device>/numa_node
For complete documentation of these APIs, refer to the Memory Driver APIs section in the Programmer’s Guide.
Intel QuickAssist Technology Optimization
This section references parameters that can be modified in the configuration file or build system to help maximize throughput and minimize latency or reduce memory footprint. Refer to the Programmer’s Guide for detailed descriptions of the configuration file and its parameters.
Disable Services Not Used
When more than one service is enabled, internal hardware resources are
partitioned between those services. This can reduce the throughput
available to each individual service, regardless of which combination
is enabled. On Intel® QAT 2.0 and later devices, a maximum of two
of the three available services (sym, asym, dc) may be enabled
simultaneously on a single QAT endpoint. Any two-service combination
— sym;dc, asym;dc, or sym;asym — will result in the hardware
acceleration engines being split 4|4 between the two services, reducing
peak throughput for each compared to a single-service configuration. For
best performance, enable only the service(s) your workload requires.
For details on valid ServicesEnabled combinations and their performance
implications, refer to
ServicesEnabled and
Performance Considerations
in the Programmer’s Guide.
Disable Parameter Checking
Parameter checking results in more Intel architecture cycles consumed
by the driver. By default, parameter checking is enabled. This is
controlled by ICP_PARAM_CHECK, which can be set as an environment
variable or it can be controlled with the configure script option, if
available.
Adjusting the Polling Interval
This section describes how to get an indication of whether your application is polling at the right frequency. As described in the Polling Mode section the rate of polling will impact latency, offload cost and throughput. This section also describes two ways of polling:
Polling via a separate thread.
Polling within the same context as the submit thread.
With option 1, there is limited control over the poll interval, unless a real time operating system is employed. With option 2, the user can control the interval to poll based on the number of submissions made.
Whichever method is employed, the user should start with a low frequency of polling, and this will ensure maximum throughput is achieved. Gradually increase the polling interval until the throughput starts to drop. The polling interval just before throughput drops should be the optimal for throughput and offload cost.
This method is only applicable where the submit rate is relatively stable and the average packet size does not vary. To allow for variances, a larger ring size is recommended, but this in turn will add to the maximum latency.
Application enqueue/dequeue tuning in Intel QAT multi-instances under stress condition
Note
This applies only to platforms starting with Intel QAT Gen 4.
It is up to the application level to decide how many frames to enqueue/dequeue in a single burst, but different tuning is expected across Intel QAT generations in multi-instances under stress conditions.
The common scheme for async engines usually enqueue a full burst size of frames to Intel QAT and the crypto dispatch function dequeued from Intel QAT, the dequeue call back function is called periodically in a loop until full burst size of frames are dequeued.
This common scheme design works well for Intel QAT Gen 2 and Gen 3 platforms as the dequeue is more responsive, hence the application always gets responses. For Intel QAT Gen 4 platform, if the dequeue requests been called are too aggressive, the Intel QAT is constantly busy during stress, and it eventually cannot catch up filling the responses for the next dequeue. This behavior can directly lead to dequeue number constantly to be zero, even if some processes are already completed.
It is recommended for the application to always check the inflight number at the beginning before calling enqueue burst and don’t dequeue as many as possible but only a certain number (e.g. 64) of frames that are enough to process. Then the enqueue and dequeue can be followed in turns. This approach will make Intel QAT Gen 4 platforms more comfortable to process the queues across multiple instances concurrently.