Base API and API Conventions
This section describes aspects common to all Intel® QuickAssist Technology APIs, starting with the base API and followed by conventions.
Intel® QAT Base API
The base API is a top-level API definition for Intel® QuickAssist Technology. It contains structures, data types, and definitions that are common across the interface.
Data Buffer Models
Data buffers are passed across the API interface in one of the following formats:
Flat Buffers represent a single region of physically contiguous memory and are described in detail in the Flat Buffers section.
Scatter-Gather Lists are essentially an array of flat buffers, for cases where the memory is not all physically contiguous. These are described in detail in the Scatter-Gather Lists section.
Note
The source and destination buffer types must match. For example, if the source buffer type is set to flat buffer, the destination buffer type must also be a flat buffer.
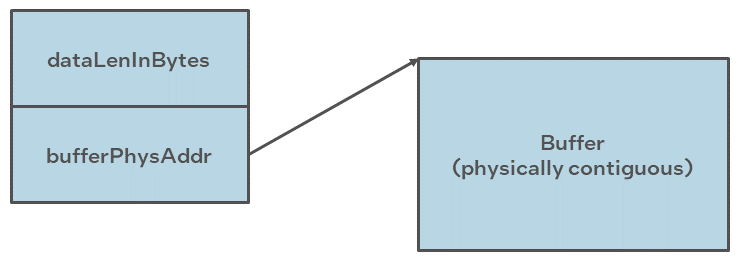
Flat Buffers
Flat buffers are represented by the type CpaFlatBuffer, defined in the file cpa.h.
It consists of two fields:
Data pointer
pData: points to the start address of the data or payload. The data pointer is a virtual address; however, the actual data pointed to is required to be in contiguous and DMAable physical memory. This buffer type is typically used when simple, unchained buffers are needed.Length of this buffer:
dataLenInBytesspecified in bytes.
For data plane APIs (cpa_sym_dp.h and cpa_dc_dp.h), a flat buffer is represented by the type
CpaPhysFlatBuffer, also defined in cpa.h. This is similar to the CpaFlatBuffer structure;
the difference is that, in this case, the data pointer, bufferPhysAddr, is a physical address
rather than a virtual address.
The figure below shows the layout of a flat buffer.
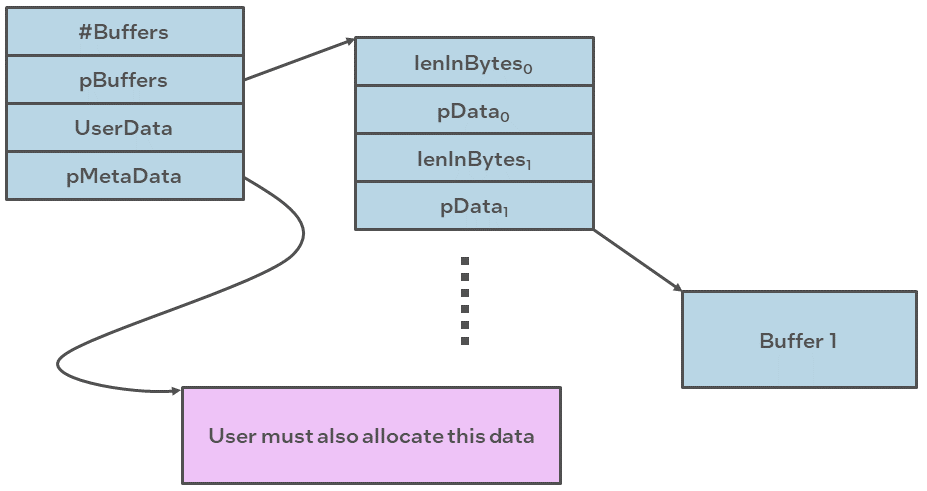
Scatter-Gather Lists
A scatter-gather list is defined by the type CpaBufferList,
also defined in the file cpa.h. This buffer structure is typically used
where more than one flat buffer can be provided to a particular API.
The buffer list contains four fields, as follows:
The number of buffers in the list.
Pointer to an unbounded array of flat buffers.
User Data: an opaque field; it is not read or modified internally by the API. This field could be used to provide a pointer back into an application data structure, providing the context of the call.
Pointer to metadata required by the API:
The metadata is required for internal use by the API. The memory for this buffer needs to be allocated by the client as contiguous data. The size of this metadata buffer is obtained by calling
cpaCyBufferListGetMetaSizefor crypto,cpaBufferLists, andcpaDcBufferListGetMetaSizefor data compression.The memory required to hold the
CpaBufferListstructure and the array of flat buffers is not required to be physically contiguous. However, the flat buffer data pointers and the metadata pointer are required to reference physically contiguous DMAable memory.There is a performance impact when using scatter-gather lists instead of flat buffers. Refer to the Intel® QAT Performance Optimization Guide for additional information.
The figure below shows a graphical representation of a scatter-gather buffer list.
For data plane APIs (cpa_sym_dp.h and cpa_dc_dp.h) a region
of memory that is not physically contiguous is described using the
CpaPhysBufferList structure. This is similar to the CpaBufferList
structure; the difference, in this case, the individual flat buffers
are represented using physical rather than virtual addresses.
Intel® QAT API Conventions
Instance Discovery
The Intel® QAT API supports multiple instances. An instance represents
a “channel” to a specific hardware accelerator. Multiple instances can
access the same hardware accelerator (that is, the relationship between
instances and a hardware accelerator is N:1). The instance is identified
using the CpaInstanceHandle handle type. This handle type represents
a specific instance within the system and is passed as a parameter to all
API functions that operate on instances.
Instance discovery is achieved through service-specific API invocations.
Subsections here provide details on the instance discovery for data compression (dc)
as well as the cryptographic service.
Important
Instance discovery APIs (cpaCyGetNumInstances, cpaCyGetInstances,
cpaDcGetNumInstances, cpaDcGetInstances) return only instances
assigned and visible to the calling context. In mixed PF/VF environments,
applications cannot assume access to instances residing on other physical
or virtual functions. Enumerate and query capabilities for each discovered
instance to determine actual service availability.
Data Compression
In the below example, the number of dc instances available to the application is
queried via the cpaDcGetNumInstances call. The application obtains the
instance handle of the first instance.
void sampleDcGetInstance (CpaInstanceHandle *pDcInstHandle)
{
CpaInstanceHandle dcInstHandles[MAX_INSTANCES];
Cpa16U numInstances = 0;
CpaStatus status = CPA_STATUS_SUCCESS;
*pDcInstHandle = NULL;
status = cpaDcGetNumInstances(&numInstances);
if ((status == CPA_STATUS_SUCCESS) && (numInstances > 0)) {
status = cpaDcGetInstances(MAX_INSTANCES, dcInstHandles);
if (status == CPA_STATUS_SUCCESS) {
*pDcInstHandle = dcInstHandles[0];
}
}
if (0 == numInstances) {
PRINT_ERR("No instances found for 'SSL'\n");
PRINT_ERR("Please check your section names in the config file.\n");
PRINT_ERR("Also make sure to use config file version 2.\n");
}
}
Cryptography
Note
This note is pertinent to customers utilizing legacy QuickAssist Technology (QAT) generations, such as QAT1.7. It is not applicable to customers operating on QAT2.0 or newer generations.
For cryptographic operations on legacy QAT generations, it is imperative to use the APIs cpaCyGetNumInstances and cpaCyGetInstances.
A notable distinction is that legacy QAT generations support both symmetric (sym) and asymmetric (asym) cryptographic instances within a single instance.
In contrast, starting with QAT2.0, each instance is dedicated to either symmetric or asymmetric operations exclusively.
Cryptography instance types are delineated by the enumeration CpaAccelerationServiceType, which can be found in the cpa.h header file.
The currently supported instance types are:
CPA_ACC_SVC_TYPE_CRYPTO_ASYMfor asymmetric cryptographic servicesCPA_ACC_SVC_TYPE_CRYPTO_SYMfor symmetric cryptographic services
Consider the following example, where an additional parameter is provided to specify the desired service type. The application first queries the number of available instances for the requested service type using the cpaGetNumInstances API.
Subsequently, the application acquires the handle for the first instance returned by the cpaGetInstances API call.
void sampleCyGetInstance(CpaInstanceHandle *pCyInstHandle, CpaAccelerationServiceType service_type)
{
CpaInstanceHandle cyInstHandles[MAX_INSTANCES];
Cpa16U numInstances = 0;
CpaStatus status = CPA_STATUS_SUCCESS;
*pCyInstHandle = NULL;
status = cpaGetNumInstances(service_type, &numInstances);
if (numInstances >= MAX_INSTANCES)
{
numInstances = MAX_INSTANCES;
}
if ((status == CPA_STATUS_SUCCESS) && (numInstances > 0))
{
status = cpaGetInstances(service_type, numInstances, cyInstHandles);
if (status == CPA_STATUS_SUCCESS)
{
*pCyInstHandle = cyInstHandles[0];
}
}
if (0 == numInstances)
{
PRINT_ERR("No instances found for 'SSL'\n");
PRINT_ERR("Please check your section names");
PRINT_ERR(" in the config file.\n");
PRINT_ERR("Also make sure to use config file version 2.\n");
}
}
Querying Capabilities
Note
This section describes the querying capabilities for data compression (dc); however, the flow of the calls is similar for the cryptographic service.
The next example shows the application querying the capabilities of the data compression implementation, and verifying the required functionality is present. Each service implementation exposes the capabilities that have been implemented and are available. Capabilities include algorithms, common features, and limits to variables. Each service has a unique capability matrix, and each implementation identifies and describes its particular implementation through its capability’s API.
status = cpaDcQueryCapabilities(dcInstHandle, &cap);
if (status != CPA_STATUS_SUCCESS) {
return status;
}
if (!cap.statelessDeflateCompression || !cap.statefulDeflateDecompression || !cap.checksumCRC32 || !cap.dynamicHuffman) {
PRINT_ERR("Error: Unsupported functionality\n");
return CPA_STATUS_FAIL;
}
/*
* Set the address translation function for the instance
*/
status = cpaDcSetAddressTranslation(dcInstHandle, sampleVirtToPhys);
if (CPA_STATUS_SUCCESS == status) {
/* Start DataCompression component
* In this example we are performing static compression so
* an intermediate buffer is not required */
PRINT_DBG("cpaDcStartInstance\n");
status = cpaDcStartInstance(dcInstHandle, 0, NULL);
}
In the example, the application requires stateless deflate compression with dynamic Huffman encoding and stateful decompression with support for CRC32 checksums. The example also sets the address translation function for the instance. The specified function is used by the API to perform any required translation of a virtual address to a physical address. Finally, the instance is started.
Modes of Operation
The Intel® QAT API supports both synchronous and asynchronous modes of operation. For optimal performance, the application should be capable of submitting multiple outstanding requests to the acceleration engines. Submitting multiple outstanding requests minimizes the processing latency on the acceleration engines. This can be done by submitting requests asynchronously or by submitting requests in synchronous mode using multi-threading in the application.
Developers can select the mode of operation that best aligns with their application and system architecture.
Asynchronous Operation
To invoke the API asynchronously, the user supplies a callback function to the API, as shown in the below figure. Control returns to the client once the request has been sent to the hardware accelerator, and the callback is invoked when the engine completes the operation. The mechanism used to invoke the callback is implementation-dependent. For some implementations, the callback is invoked as part of an interrupt handler bottom half. For other implementations, the callback is invoked in the context of a polling thread. In this case, the user application is responsible for creating and scheduling this polling thread. Refer to Related Documents and References for the implementation of specific documentation for more details.
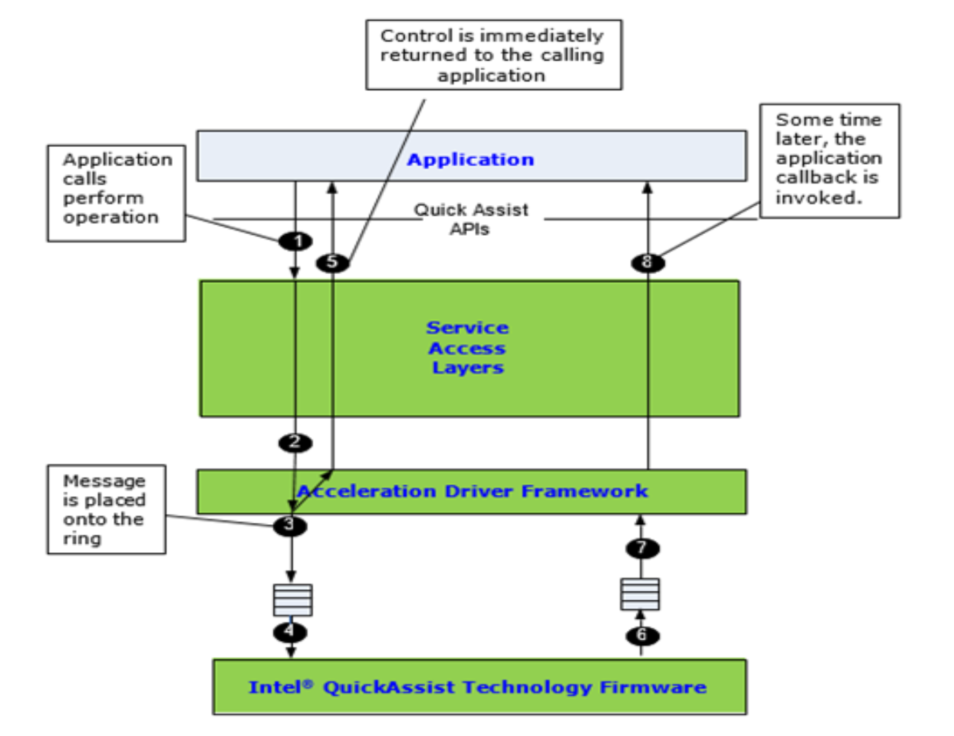
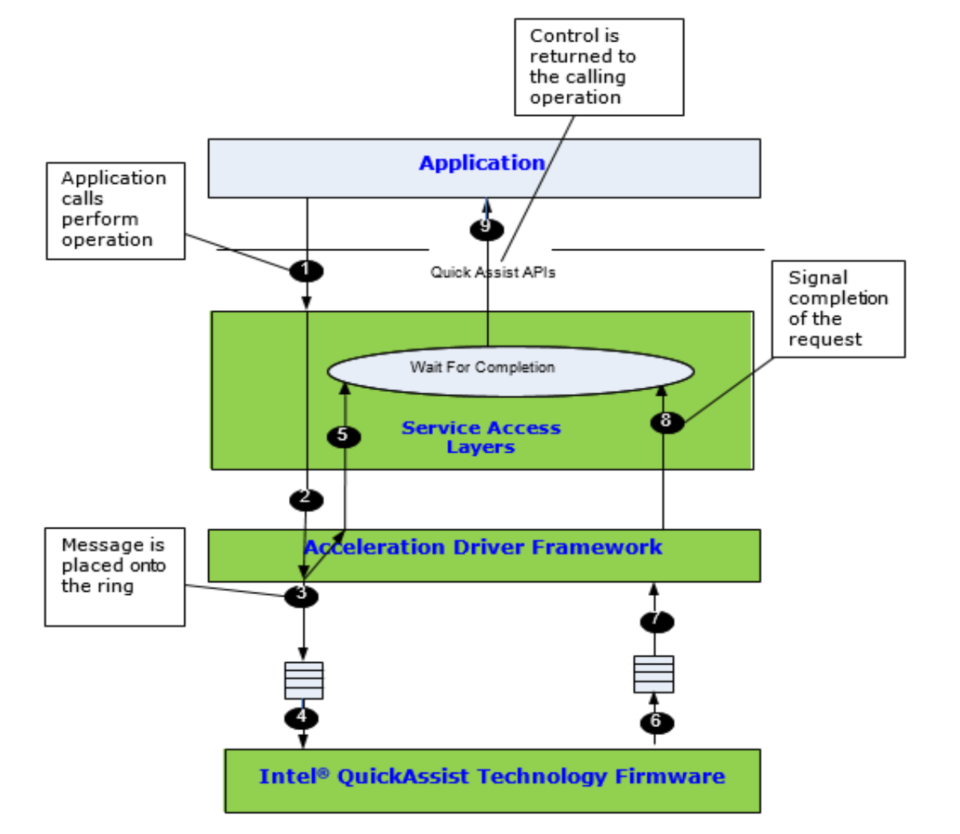
Synchronous Operation
Synchronous operation is specified by supplying a NULL function pointer in the callback parameter of the perform API, as shown in the below figure. In this case, the function does not return until the operation is complete. The calling thread may spend on a semaphore or other synchronization primitive after sending the request to the execution engine.
Upon the completion of the operation, the synchronization primitive unblocks, and execution resumes. Synchronous mode is therefore blocking and should not be used when invoking the function from a context in which sleeping is not allowed (for example, an interrupt context on Linux*).
Memory Allocation and Ownership
The convention is that all memory needed by an API implementation is allocated outside of that implementation. In other words, the APIs are defined such that the memory needed to execute operations is supplied by a client or platform control entity rather than having memory allocated internally.
Memory used for parameters is owned by the side (caller or callee) that allocated the memory. An owner is responsible for de-allocating the memory when it is no longer needed.
Generally, memory ownership does not change. For example, if a program allocates memory and then passes a pointer to the memory as a parameter to a function call, the caller retains ownership and is still responsible for the de-allocation of the memory. Default behavior and any function which deviates from this behavior clearly state so in the function definition.
For optimal performance, data pointers should be 8-byte aligned. In some cases, this is a requirement, while in most other cases, it is a recommendation for performance. Refer to Related Documents and References for the service-specific API manual for optimal usage of the particular API.
Data Plane APIs
The Intel® QAT APIs for symmetric cryptography and for data compression supports
both traditional (cpa_cy_sym.h and cpa_dc.h) and data plane APIs
(cpa_cy_sym_dp.h and cpa_dc_dp.h).
Note
There is no data plane support for asymmetric cryptography services.
The data plane APIs are recommended for applications running in a data plane environment where the cost of offload (that is, the cycles consumed by the driver sending requests to the accelerator) needs to be minimized. Several constraints have been placed on these APIs to minimize the cost of offload. If these constraints are too restrictive for a given application, the more general-purpose traditional APIs can be used (at an increased cost of offload).
The data plane APIs can be used if the following constraints are acceptable:
There is no support for partial packets or stateful requests.
Thread safety is not supported. Each software thread should have access to its unique instance (
CpaInstanceHandle).Only asynchronous invocation is supported.
Polling is used, rather than interrupts, to dispatch callback functions. Callbacks are invoked in the context of a polling thread.
The user application is responsible for creating and scheduling this polling thread.
Polling functions are not defined by the Intel® QAT API. Implementations provide their polling functions.
Refer to Related Documents and References for implementation specific documentation containing further information on polling functions.
Buffers and buffer lists are passed using physical addresses to avoid virtual-to-physical-address translation costs.
Alignment restrictions may be placed on the operation data (that is,
CpaCySymDpOpDataandCpaDcDpOpData) and buffer list (that is,CpaPhysBufferList) structures passed to the data plane APIs. For example, the operation data may need to be at least 8-byte aligned, contiguous, resident, DMAaccessible memory. Refer to Related Documents and References for implementation specific documentation for more details.For CCM and GCM modes of the AES, when performing decryption and verification, if the verification fails, then the message buffer is not zeroed. The data plane APIs distinguish between enqueuing a request and submitting that request to the accelerator to be performed. This allows the cost of submitting a request (which can be expensive, in terms of cycles, for some hardware-based implementations) to be amortized over all enqueued requests on that instance (
CpaInstanceHandle).To enqueue one request and to optionally submit all previously enqueued requests, the function
cpaCySymDpEnqueueOp(orcpaDcDpEnqueueOpfor data compression service) can be used.To enqueue multiple requests and to optionally submit all previously enqueued requests, the function
cpaCySymDpEnqueueOpBatch(orcpaDcDpEnqueueOpBatchfor data compression service) can be used.Use the function
cpaCySymDpPerformOpNow(orcpaDcDpPerformOpNowfor data compression service) that can be used to submit all previously enqueued requests.Different implementations of this API may have different performance trade-offs. Refer to Related Documents and References for documentation for implementation details.