A Tour of GHZ examples¶
This tutorial provides some basic introduction to programming quantum algorithms
and working with the FullStateSimulator through three implementations of the
following circuit
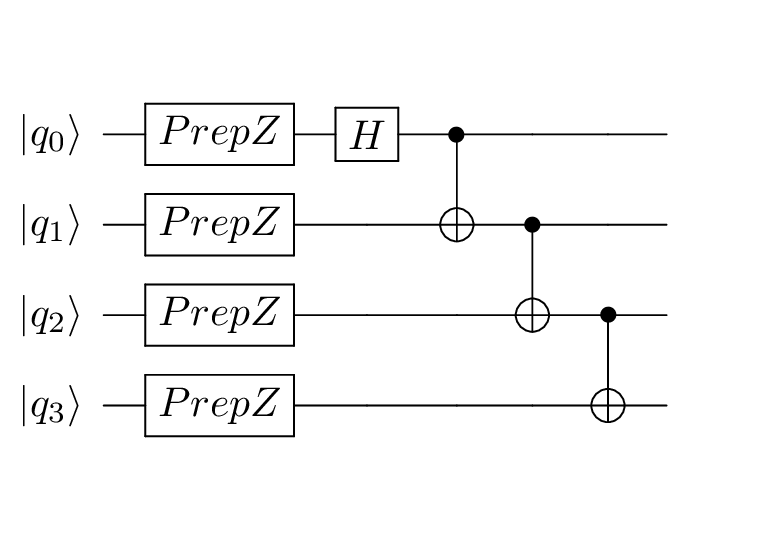
and the accompanying classical logic. The executable will manage running
the above quantum circuit and retrieving the data in the FullStateSimulator
to confirm the instructions are producing what is intended. This circuit
produces a
Greenberger-Horne-Zeilinger (GHZ) state
for 4 qubits. In other words, the qubits will be in a super-position of two
states, one with all qubits in the \(\ket{0}\) state and one with all qubits
in the \(\ket{1}\) state, and each with equal chance of being measured.
The source code for each implementation is available in the
quantum_examples/ directory of the Intel® Quantum SDK.
Ideal GHZ¶
To begin writing the program, get access to the quantum data types and methods
by including the quintrinsics.h and the quantum_full_state_simulator_backend.h headers into the
source as shown in Listing 2.
14#include <clang/Quantum/quintrinsics.h>
15
16/// Quantum Runtime Library APIs
17#include <quantum_full_state_simulator_backend.h>
As described in Writing New Algorithms, next declare an
array of qubits (qbit) in the global namespace as show in Listing 3
19const int total_qubits = 4;
20qbit qubit_register[total_qubits];
Next, implement the quantum algorithm by writing the functions or classes that
contain the quantum logic. The quantum_kernel keyword
should be in front of each function that builds the quantum algorithm. Shown in
Listing 4, all the quantum instructions are placed in a single
quantum_kernel. The first instruction is to initialize the state of each
qubit by utilizing a for loop to call PrepZ() on the elements of the
qbit array. Next, apply a Hadamard gate (H()) on the first qubit to set
it into a superposition. And lastly, apply Controlled Not gates (CNOT()) on
pairs of qubits to create entanglement between them.
22quantum_kernel void ghz_total_qubits() {
23 for (int i = 0; i < total_qubits; i++) {
24 PrepZ(qubit_register[i]);
25 }
26
27 H(qubit_register[0]);
28
29 for (int i = 0; i < total_qubits - 1; i++) {
30 CNOT(qubit_register[i], qubit_register[i + 1]);
31 }
32}
In the main function of the program, instantiate a FullStateSimulator
object and use its ready() method, as shown in
Listing 5. Do that as
described in Configuring the FullStateSimulator, by first
creating an IqsConfig object, changing it to be verbose (not required), and
then using it as an argument to the FullStateSimulator constructor. Then use
the return of the ready() method to trigger an early exit if something is
wrong.
34int main() {
35 iqsdk::IqsConfig settings(total_qubits, "noiseless");
36 settings.verbose = true;
37 iqsdk::FullStateSimulator quantum_8086(settings);
38 if (iqsdk::QRT_ERROR_SUCCESS != quantum_8086.ready())
39 return 1;
Next, prepare the classical data structures for working with simulation data.
Create a set of id values to refer to the qubits of interest as shown in
Listing 6. This is important
because qbit variables do not necessarily specify a constant physical qubit
in hardware; this mapping can be created and changed at various stages during
program execution according to the compiler optimizations.
41 // get references to qbits
42 std::vector<std::reference_wrapper<qbit>> qids;
43 for (int id = 0; id < total_qubits; ++id) {
44 qids.push_back(std::ref(qubit_register[id]));
45 }
Now that the backend simulator is ready, call the quantum_kernel.
47 ghz_total_qubits();
After this line during execution, the FullStateSimulator contains the
state-vector data describing the qubits. Although there are facilities to
conveniently specify every possible state for a set of qubits, this could be an
overwhelming amount of data. Where possible, use the available constructors
described in API Reference to
configure a QssIndex object to refer to only the states of interest and
store them in a vector. In Listing 8, two explicit strings
formatted for 4 qubits are used to specify the two states.
49 // use string constructor of Quantum State Space index to choose which
50 // basis states' data is retrieved
51 iqsdk::QssIndex state_a("|0000>");
52 iqsdk::QssIndex state_b("|1111>");
53 std::vector<iqsdk::QssIndex> bases;
54 bases.push_back(state_a);
55 bases.push_back(state_b);
Now access the probabilities for these two states through
FullStateSimulator’s getProbabilities() method. Remember that ideally
the GHZ state would only be in \(\ket{0000}\) or \(\ket{1111}\). So for
this simulated circuit, when summing the probabilities of measuring in either
\(\ket{0000}\) or \(\ket{1111}\), the sum should be 1.0.
57 iqsdk::QssMap<double> probability_map;
58 probability_map = quantum_8086.getProbabilities(qids, bases);
59
60 double total_probability = 0.0;
61 for (auto const & key_value : probability_map) {
62 total_probability += key_value.second;
63 }
64 std::cout << "Sum of probability to measure fully entangled state: "
65 << total_probability << std::endl;
Alternatively, display a formatted summary of the states to the console output with
displayProbabilities() or displayAmplitudes().
66 quantum_8086.displayProbabilities(probability_map);
This program can be compiled with the default options. Configuring the qubit simulation in the Intel® Quantum Simulator creates a set of qubits with no limitation on their connectivity, in other words two-qubit operations (gates) can be applied between any pair of qubits.
$ <path to Intel Quantum SDK>/intel-quantum-compiler ideal_GHZ.cpp
Running the executable produces a line describing each quantum instruction
because the verbose option was set to true when configuring the
FullStateSimulator. That is followed by the line showing that
total_probability is equal to 1 and the summary produced by
displayProbabilities().
$ ./ideal_GHZ
- Run noiseless simulation (verbose mode)
Instruction #4 : ROTXY(phi = 1.5707, gamma = 1.57075) on phys Q 0
Instruction #5 : ROTXY(phi = 0, gamma = 3.14154) on phys Q 0
Instruction #6 : ROTXY(phi = 4.71229, gamma = 1.57075) on phys Q 1
Instruction #7 : CPHASE(gamma = 3.1415) on phys Q0 and phys Q1
Instruction #8 : ROTXY(phi = 1.5707, gamma = 1.57075) on phys Q 1
Instruction #9 : ROTXY(phi = 4.71229, gamma = 1.57075) on phys Q 2
Instruction #10 : CPHASE(gamma = 3.1415) on phys Q1 and phys Q2
Instruction #11 : ROTXY(phi = 1.5707, gamma = 1.57075) on phys Q 2
Instruction #12 : ROTXY(phi = 4.71229, gamma = 1.57075) on phys Q 3
Instruction #13 : CPHASE(gamma = 3.1415) on phys Q2 and phys Q3
Instruction #14 : ROTXY(phi = 1.5707, gamma = 1.57075) on phys Q 3
Sum of probability to measure fully entangled state: 1
Printing probability map of size 2
|0000> : 0.5 |1111> : 0.5
The complete code is available as ideal_GHZ.cpp in the quantum_examples/
directory of the Intel® Quantum SDK.
Sampled GHZ¶
As discussed in Measurements using Simulated Quantum Backends, the state-vector probabilities that the above program uses are not data that quantum hardware is capable of returning. Consider the hypothetical scenario in which you now need to know how many times the quantum circuit must be run and evaluated in order to find the probability with the desired numerical accuracy. This can be done efficiently by using the simulation data.
Only the non-quantum_kernel sections of the ideal_GHZ.cpp program need
changed to accomplish this. This can be done by using a different FullStateSimulator
method after calling the quantum_kernel, as shown in Listing 11
69 // use sampling technique to simulate the results of many runs
70 std::vector<std::vector<bool>> measurement_samples;
71 unsigned total_samples = 1000;
72 measurement_samples = quantum_8086.getSamples(total_samples, qids);
Each std::vector<bool> represents the observation of a state, each
individual value represents the outcome of that qubit as arranged in the
qids vector. The FullStateSimulator has a helper method to conveniently
calculate the number of times a given state appears in an ensemble of
observations.
74 // build a distribution of states
75 iqsdk::QssMap<unsigned int> distribution =
76 iqsdk::FullStateSimulator::samplesToHistogram(measurement_samples);
From this QssMap, calculate the estimate of the probability of observing
each state.
78 // print out the results
79 std::cout << "Using " << total_samples
80 << " samples, the distribution of states is:" << std::endl;
81 for (const auto & entry : distribution) {
82 double weight = entry.second;
83 weight = weight / total_samples;
84
85 std::cout << entry.first << " : " << weight << std::endl;
86 }
This program can be compiled with the same command as the previous program.
$ <path to Intel Quantum SDK>/intel-quantum-compiler sample_GHZ.cpp
In addition to the same output from ideal_GHZ.cpp, the result
of the samplesToHistogram() method is also printed out:
Using 1000 samples, the distribution of states is:
|0000> : 0.496
|1111> : 0.504
Because the IqsConfig used the default setting of a random seed (by not
specifying one), this simulation will produce a different sequence of samples on
subsequent executions and thus a slightly different estimate of the probability
of observing each state.
The complete code is available as sample_GHZ.cpp in the
quantum_examples/ directory of the Intel® Quantum SDK.
GHZ state on Quantum Dot Simulator¶
It takes the change of only a few lines of code to target another backend, as
you can see by comparing sample_GHZ.cpp and qd_GHZ.cpp
(e.g. using the diff CLI tool). As described in Quantum Dot Simulator Backend,
the Quantum Dot Simulator (QD_Sim) adds to the state vector simulation by
including details from the control signals that interact with quantum dot
qubits. This creates additional computational overhead compared to the
Intel® Quantum Simulator. The first change in
this program is to reduce the size of the circuit to just a pair of qubits so
the execution stays around a few seconds.
QD_Sim treats running sequential quantum_kernels and
measurement gates differently than the Intel® Quantum Simulator (see
Important Points on Quantum Dot Simulator). Although some
programs could require alteration of their logic, the above program’s
quantum_kernel and simulator usage is compatible with either backend. To
change the qubit simulator, instead of the IqsConfig object switch to
a DeviceConfig constructed with the argument "QD_SIM" as shown in
Listing 14 (note the all capitals for the argument string).
34int main() {
35 iqsdk::DeviceConfig qd_config("QD_SIM");
36 iqsdk::FullStateSimulator quantum_8086(qd_config);
With this change of backend qubit simulation, the program must now be compiled
with non-default options. The file intel-quantum-sdk-QDSIM.json
points to a file describing a 6-qubit linear array. Use the -c flag to give
the file’s location to the compiler, and specify placement and scheduling
options with -p and -S.
$ <path to Intel Quantum SDK>/intel-quantum-compiler -c <path to Intel Quantum SDK>/intel-quantum-sdk-QDSIM.json -p trivial -S greedy qd_GHZ.cpp
QD_Sim produces its own output in addition to the output
explicitly designed into the behavior of the program.
$ ./qd_GHZ.cpp
1688766838 time dependent evolution start time
sweep progress: calculation point=0 0%
sweep progress: calculation point=18199 10%
sweep progress: calculation point=36398 20%
sweep progress: calculation point=54597 30%
sweep progress: calculation point=72796 40%
sweep progress: calculation point=90994 50%
sweep progress: calculation point=109193 60%
sweep progress: calculation point=127392 70%
sweep progress: calculation point=145591 80%
sweep progress: calculation point=163790 90%
Time evolution took 2.568378 seconds
Fri Jul 7 14:54:01 2023
1688766841 time dependent evolution end time
Sum of probability to measure fully entangled state: 0.999983
Printing probability map of size 2
|00> : 0.4998 |11> : 0.5002
Using 1000 samples, the distribution of states is:
|00> : 0.519
|11> : 0.481
The output starts with the backend’s simulation progress, followed by the
familiar output in the program’s implementation. The probabilities
reported by the FullStateSimulator are slightly different from the exact
\(0.50\) because the Quantum Dot Simulator includes the simulation of the
electronics controlling the quantum dots.
The complete code is available as qd_GHZ.cpp in the quantum_examples/
directory of the Intel® Quantum SDK.
Using release_quantum_state()¶
Using release_quantum_state() to indicate the intention to effectively
abandon operating on the qubits can lead to greater reduction of the total
operations when combined with -O1 optimization. Inconsequential operations
can be removed, and in some cases this can include a measurement operation.
Consider the following sample code. The first three quantum_kernel blocks
build up the preparation and measurement of a state with three angles as input
parameters.
#include <clang/Quantum/quintrinsics.h>
#include <quantum_full_state_simulator_backend.h>
qbit q[2];
quantum_kernel void PrepAll() {
PrepZ(q[0]);
PrepZ(q[1]);
}
//nothing special about this ansatz
quantum_kernel void Ansatz_Heisenberg (double angle0, double angle1, double angle2) {
RX(q[0], angle0);
RY(q[1], angle1);
S(q[1]);
CNOT(q[0], q[1]);
RZ(q[1], angle2);
CNOT(q[0], q[1]);
Sdag(q[1]);
}
quantum_kernel double Measure_Heisenberg(){
cbit c[3];
CNOT(q[0], q[1]);
MeasX(q[0], c[0]); // XX term
MeasZ(q[1], c[1]); // ZZ term
CZ(q[0], q[1]);
MeasX(q[0], c[2]); //-YY term
CZ(q[0], q[1]);
CNOT(q[0], q[1]);
release_quantum_state();
return (1. -2. * (double) c[0]) + (1. -2. * (double) c[1]) + (1. + 2. * (double) c[2]);
}
The next quantum_kernel function calls the prior three blocks. This fourth function
contains the release_quantum_state() call from above.
The main() function calls VQE_Heisenberg() after
setting up a FullStateSimulator.
quantum_kernel double VQE_Heisenberg(double angle0, double angle1, double angle2) {
PrepAll();
Ansatz_Heisenberg (angle0, angle1, angle2);
return Measure_Heisenberg(); //note this QK will inherit the release for this function
}
int main(){
iqsdk::IqsConfig settings(2, "noiseless");
iqsdk::FullStateSimulator quantum_8086(settings);
if (iqsdk::QRT_ERROR_SUCCESS != quantum_8086.ready())
return 1;
double debug1 = 1.570796;
double debug2 = debug1 / 2;
double debug3 = debug2 / 2;
VQE_Heisenberg(debug1, debug2, debug3);
}
If this is compiled with -O0 flag and no optimization is performed, we
expect each of the 3 measurement operations (MeasX, MeasZ, MeasX) to
be called. Looking at the resulting .qs file confirms this:
.globl "_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub" // -- Begin function _Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub
.type "_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub",@function
"_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub": // @"_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub"
// %bb.0: // %aqcc.quantum
quprep QUBIT[0] (slice_idx=1)
quprep QUBIT[1] (slice_idx=0)
qurotxy QUBIT[0], @shared_variable_array[4], @shared_variable_array[0] (slice_idx=0)
qurotxy QUBIT[1], @shared_variable_array[5], @shared_variable_array[1] (slice_idx=0)
qurotz QUBIT[1], 1.570796e+00 (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 4.712389e+00 (slice_idx=0)
qucphase QUBIT[0], QUBIT[1], 3.141593e+00 (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 1.570796e+00 (slice_idx=0)
qurotz QUBIT[1], @shared_variable_array[6] (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 4.712389e+00 (slice_idx=0)
qucphase QUBIT[0], QUBIT[1], 3.141593e+00 (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 1.570796e+00 (slice_idx=0)
qurotz QUBIT[1], 4.712389e+00 (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 4.712389e+00 (slice_idx=0)
qucphase QUBIT[0], QUBIT[1], 3.141593e+00 (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 1.570796e+00 (slice_idx=0)
qurotxy QUBIT[0], 1.570796e+00, 4.712389e+00 (slice_idx=0)
qumeasz QUBIT[0] @shared_cbit_array[0] (slice_idx=0)
qurotxy QUBIT[0], 1.570796e+00, 1.570796e+00 (slice_idx=0)
qumeasz QUBIT[1] @shared_cbit_array[1] (slice_idx=0)
qucphase QUBIT[0], QUBIT[1], 3.141593e+00 (slice_idx=0)
qurotxy QUBIT[0], 1.570796e+00, 4.712389e+00 (slice_idx=0)
qumeasz QUBIT[0] @shared_cbit_array[2] (slice_idx=0)
qurotxy QUBIT[0], 1.570796e+00, 1.570796e+00 (slice_idx=0)
qucphase QUBIT[0], QUBIT[1], 3.141593e+00 (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 4.712389e+00 (slice_idx=0)
qucphase QUBIT[0], QUBIT[1], 3.141593e+00 (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 1.570796e+00 (slice_idx=2)
return
.Lfunc_end3:
.size "_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub", .Lfunc_end3-"_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub"
// -- End function
.section ".note.GNU-stack","",@progbits
However, compiling with -O1 will cause the optimizer to remove operations.
Here in addition to combining and removing gates, the optimizer will remove a
measurement operation because its outcome can be deduced from the other two
measurements’ outcomes. The cbit used to store the now-missing measurement
outcome will have its value correctly set by the Quantum Runtime.
.globl "_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub" // -- Begin function _Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub
.type "_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub",@function
"_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub": // @"_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub"
// %bb.0: // %aqcc.quantum
quprep QUBIT[1] (slice_idx=1)
quprep QUBIT[0] (slice_idx=0)
qurotxy QUBIT[1], @shared_variable_array[4], @shared_variable_array[1] (slice_idx=0)
qurotxy QUBIT[0], @shared_variable_array[5], @shared_variable_array[0] (slice_idx=0)
qurotxy QUBIT[0], 1.570796e+00, 4.712389e+00 (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 0.000000e+00 (slice_idx=0)
qucphase QUBIT[0], QUBIT[1], 3.141593e+00 (slice_idx=0)
qurotxy QUBIT[0], 1.570796e+00, 0.000000e+00 (slice_idx=0)
qumeasz QUBIT[0] @shared_cbit_array[0] (slice_idx=0)
qurotxy QUBIT[1], 1.570796e+00, 4.712389e+00 (slice_idx=0)
qumeasz QUBIT[1] @shared_cbit_array[1] (slice_idx=2)
return
.Lfunc_end3:
.size "_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub", .Lfunc_end3-"_Z45VQE_Heisenberg(double, double, double).QBB.3.v.stub"
// -- End function
.section ".note.GNU-stack","",@progbits
Writing Variational Algorithms¶
Introduction¶
Variational algorithms are considered to be one of the most promising
applications to allow quantum advantage using near-term systems [CAB+21].
The Intel® Quantum SDK has many features that are geared for coding variational
algorithms with a focus on performance. The Hybrid Quantum Classical
Library (HQCL) [IntelLabs23] is a collection of tools that will help a user
increase productivity when programming variational algorithms. This example
combines these tools with dlib (a popular C++ library for solving
optimization problems [DLI23] ), to applying the variational algorithm to
the generation of thermofield double (TFD) states [PM20] [SPK+21].
Previous implementations [KWP+22] included the latter workload with a
hard-coded version of the cost function expression, which was pre-calculated.
Fig. 1 (reproduced from [KWP+22]) shows the full circuit that is
used for the variational algorithm execution.
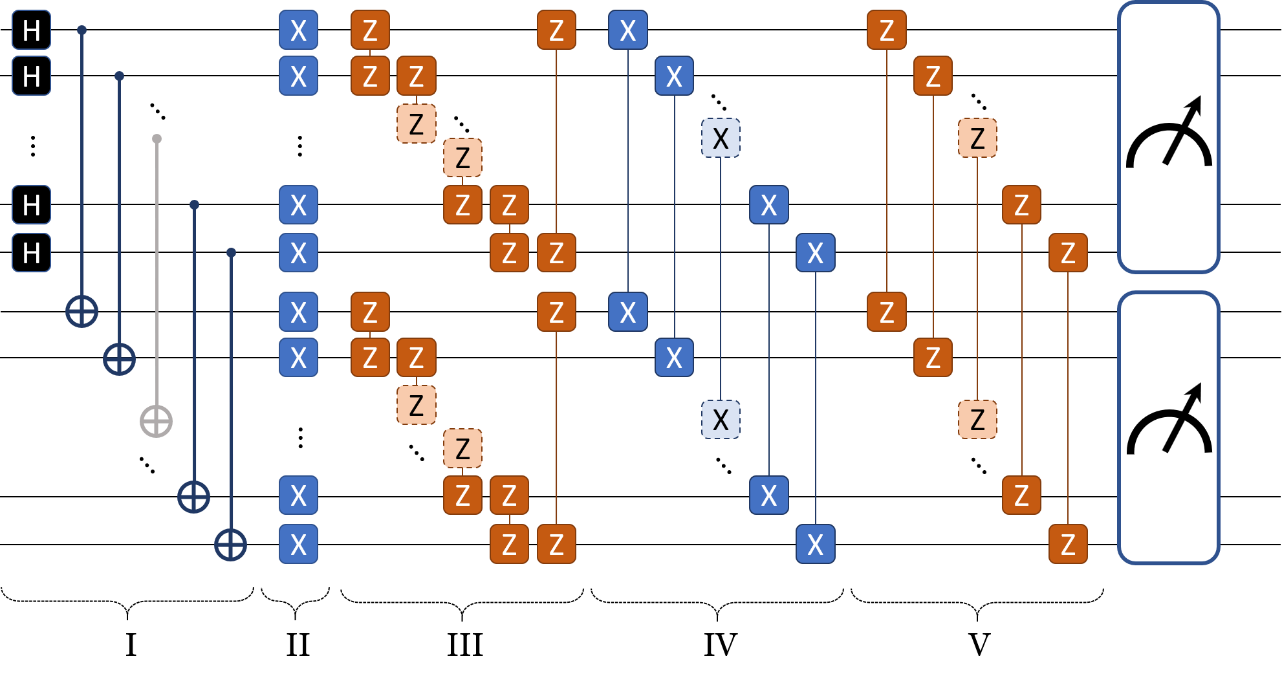
Fig. 1 The quantum circuit for single-step TFD state generation. Stages:(I) preparing infinite temperature TFD state, (II) Intra-system \(R_X\) operation, (III) Intra-system \(ZZ\) operation, (IV) Inter-system \(XX\) operation, (V) Inter-system \(ZZ\) operation. A and B represent the two subsystems, each containing \(N_\textrm{sub}\) qubits. (reproduced from [KWP+22])¶
In this implementation, HQCL will symbolically construct the cost function expression, and use qubit-wise commutation (QWC) [YVI20] to group terms and reduce the number of circuit repetitions required to calculate the cost function. HQCL will also automatically populate the necessary mapping angles at runtime, to facilitate measurements of the system along different axes.
The classical optimization in this workload will be handled using the dlib
C++
library. The dlib library contains powerful functions performing local as
well
as global optimizations. Here, the find_min_bobyqa function for the
minimization of the cost function performs quite well for the chosen workload.
The choice of the optimization technique can heavily influence the number of
iterations required for convergence of certain variational algorithms. The
Intel Quantum Simulator [GHBS20] will be used as the backend in this
example.
Code¶
Preamble¶
In the preamble of the source file shown in Listing 15 below, the
header files for the
IQSDK, dlib, and HQCL are included first.
1// Intel Quantum SDK header files
2#include <clang/Quantum/quintrinsics.h>
3#include <quantum.hpp>
4
5#include <vector>
6#include <cassert>
7
8// Library for optimizations
9#include <dlib/optimization.h>
10#include <dlib/global_optimization.h>
11
12// Libraries for automating hybrid algorithm
13#include <armadillo>
14#include "SymbolicOperator.hpp"
15#include "SymbolicOperatorUtils.hpp"
16
17// Define the number of qubits needed for compilation
18const int N_sub = 2; // Number of qubits in subsystem (thermal state size)
19const int N_ss = 2; // Number of subsystems (Not a general parameter to be changed)
20const int N = N_ss * N_sub; // Total number of qubits (TFD state size)
21
22qbit QReg[N];
23cbit CReg[N];
24
25const int N_var_angles = 4;
26const int N_map_angles = 2 * N;
27
28double QVarParams[N_var_angles]; // Array to hold dynamic parameters for quantum algorithm
29double QMapParams[N_map_angles]; // Array to hold mapping parameters for HQCL
30
31typedef dlib::matrix<double, N_var_angles, 1> column_vector;
32namespace hqcl = hybrid::quantum::core;
A data structure within dlib is defined (using a typedef) in line 31
for convenience in passing the set of parameters into the optimization loop.
This algorithm will use four variational parameters and two
mapping angles per qubit (a total of eight).
Construction of the Ansatz¶
Listing 16 contains the operations corresponding to the stages II,
III, IV, and V from Fig. 1 (stage I will be discussed later in
Listing 17). These are the four core stages that define the operations for the
TFD algorithm. A future version of the IQSDK will support quantum kernel
expressions which can be used to conveniently construct quantum kernels in a
modular way [PSM23] [Sch23].
34quantum_kernel void TFD_terms () {
35 int index_intraX = 0, index_intraZ = 0, index_interX = 0, index_interZ = 0;
36
37 // Single qubit variational terms
38 for (index_intraX = 0; index_intraX < N; index_intraX++)
39 RX(QReg[index_intraX], QVarParams[0]);
40
41 // Two-qubit intra-system variational terms (adjacent)
42 for (int grand_intraZ = 0; grand_intraZ < N_sub - 1; grand_intraZ++) {
43 for (index_intraZ = 0; index_intraZ < N_ss; index_intraZ++)
44 CNOT(QReg[grand_intraZ + N_sub * index_intraZ + 1], QReg[grand_intraZ + N_sub * index_intraZ]);
45 for (index_intraZ = 0; index_intraZ < N_ss; index_intraZ++)
46 RZ(QReg[grand_intraZ + N_sub * index_intraZ], QVarParams[1]);
47 for (index_intraZ = 0; index_intraZ < N_ss; index_intraZ++)
48 CNOT(QReg[grand_intraZ + N_sub * index_intraZ + 1], QReg[grand_intraZ + N_sub * index_intraZ]);
49 }
50
51 if (N_sub > 2) {
52 // Two-qubit intra-system variational terms (boundary term)
53 for (index_intraZ = 0; index_intraZ < N_ss; index_intraZ++)
54 CNOT(QReg[N_sub * index_intraZ], QReg[N_sub * index_intraZ + (N_sub - 1)]);
55 for (index_intraZ = 0; index_intraZ < N_ss; index_intraZ++)
56 RZ(QReg[N_sub * index_intraZ + (N_sub - 1)], QVarParams[1]);
57 for (index_intraZ = 0; index_intraZ < N_ss; index_intraZ++)
58 CNOT(QReg[N_sub * index_intraZ], QReg[N_sub * index_intraZ + (N_sub - 1)]);
59 }
60
61 // two-qubit inter-system XX variational terms
62 for (index_interX = 0; index_interX < N_sub; index_interX++) {
63 RY(QReg[index_interX + N_sub], -M_PI_2);
64 RY(QReg[index_interX], -M_PI_2);
65 }
66 for (index_interX = 0; index_interX < N_sub; index_interX++)
67 CNOT(QReg[index_interX + N_sub], QReg[index_interX]);
68 for (index_interX = 0; index_interX < N_sub; index_interX++)
69 RZ(QReg[index_interX], QVarParams[2]);
70 for (index_interX = 0; index_interX < N_sub; index_interX++)
71 CNOT(QReg[index_interX + N_sub], QReg[index_interX]);
72 for (index_interX = 0; index_interX < N_sub; index_interX++) {
73 RY(QReg[index_interX + N_sub], M_PI_2);
74 RY(QReg[index_interX], M_PI_2);
75 }
76
77 // two-qubit inter-system ZZ variational terms
78 for (index_interZ = 0; index_interZ < N_sub; index_interZ++)
79 CNOT(QReg[index_interZ], QReg[index_interZ + N_sub]);
80 for (index_interZ = 0; index_interZ < N_sub; index_interZ++)
81 RZ(QReg[index_interZ + N_sub], QVarParams[3]);
82 for (index_interZ = 0; index_interZ < N_sub; index_interZ++)
83 CNOT(QReg[index_interZ], QReg[index_interZ + N_sub]);
There are three supporting quantum kernels that are used (see
Listing 17), in
addition to the core set of operations. PrepZAll() is used to prepare all
the qubits in the ground state at the beginning of every iteration.
BellPrep() is used to prepare Bell pairs between corresponding qubits
of the two subsystems, effectively resulting in the infinite temperature
TFD state. The DynamicMapping() quantum kernel is used to hold the mapping
operations that HQCL will implement for basis changes during runtime.
86quantum_kernel void PrepZAll () {
87 // initialize the qubits
88 for (int Index = 0; Index < N; Index++)
89 PrepZ(QReg[Index]);
90}
91
92quantum_kernel void BellPrep () {
93 // prepare the Bell pairs (T -> Infinity)
94 for (int Index = 0; Index < N_sub; Index++)
95 H(QReg[Index]);
96 for (int Index = 0; Index < N_sub; Index++)
97 CNOT(QReg[Index], QReg[Index + N_sub]);
98}
99
100quantum_kernel void DynamicMapping () {
101 // Not part of the ansatz
102 // Rotations to map X to Z or Y to Z
103 for (int qubit_index = 0; qubit_index < N; qubit_index++) {
104 int map_index = 2 * qubit_index;
105 RY(QReg[qubit_index], QMapParams[map_index]);
106 RX(QReg[qubit_index], QMapParams[map_index + 1]);
107 }
108}
The supporting quantum kernels (Listing 17) and the core TFD quantum kernel (Listing 16) are combined to form the full quantum circuit in Listing 18.
110quantum_kernel void TFD_full() {
111 PrepZAll();
112 BellPrep();
113 TFD_terms();
114 DynamicMapping();
115}
Functions for Constructing the Cost Expression and the Cost Calculation¶
117hqcl::SymbolicOperator constructFullSymbOp(double inv_temp) {
118 hqcl::SymbolicOperator symb_op;
119 hqcl::pstring sym_term;
120
121 // Single qubit variational terms
122 for (int index_intraX = 0; index_intraX < N; index_intraX++) {
123 sym_term = {std::make_pair(index_intraX, 'X')};
124 symb_op.addTerm(sym_term, 1.00);
125 }
126
127 // Two-qubit intra-system variational terms (adjacent)
128 for (int grand_intraZ = 0; grand_intraZ < N_sub - 1; grand_intraZ++) {
129 for (int index_intraZ = 0; index_intraZ < N_ss; index_intraZ++) {
130 int qIndex0 = grand_intraZ + N_sub * index_intraZ;
131 int qIndex1 = grand_intraZ + N_sub * index_intraZ + 1;
132 sym_term = {std::make_pair(qIndex0, 'Z'), std::make_pair(qIndex1, 'Z')};
133 symb_op.addTerm(sym_term, 1.00);
134 }
135 }
136
137 // Two-qubit intra-system variational terms (boundary term)
138 if (N_sub > 2) {
139 for (int index_intraZ = 0; index_intraZ < N_ss; index_intraZ++) {
140 int qIndex0 = N_sub * index_intraZ;
141 int qIndex1 = N_sub * index_intraZ + (N_sub - 1);
142 sym_term = {std::make_pair(qIndex0, 'Z'), std::make_pair(qIndex1, 'Z')};
143 symb_op.addTerm(sym_term, 1.00);
144 }
145 }
146
147 // two-qubit inter-system XX variational terms
148 for (int index_interX = 0; index_interX < N_sub; index_interX++) {
149 int qIndex0 = index_interX;
150 int qIndex1 = index_interX + N_sub;
151 sym_term = {std::make_pair(qIndex0, 'X'), std::make_pair(qIndex1, 'X')};
152 symb_op.addTerm(sym_term, -pow(inv_temp, -1.00));
153 }
154
155 // two-qubit inter-system XX variational terms
156 for (int index_interZ = 0; index_interZ < N_sub; index_interZ++) {
157 int qIndex0 = index_interZ;
158 int qIndex1 = index_interZ + N_sub;
159 sym_term = {std::make_pair(qIndex0, 'Z'), std::make_pair(qIndex1, 'Z')};
160 symb_op.addTerm(sym_term, -pow(inv_temp, -1.00));
161 }
162
163 return symb_op;
164}
Programmatic construction of the cost expression is necessary for HQCL to form
the QWC groups, to generate the necessary circuits to run per optimization
iteration, and to correctly evaluate the cost at each iteration. In
Listing 19, we generate symbolic terms (sym_term) for
every expression
present, and add it to the full symbolic operator symb_op. The full cost
expression to be coded is given by
where the subscript represents the qubit index and the superscript represents the subsystem the qubit belongs to (A or B) [KWP+22].
166double runQuantumKernel(iqsdk::FullStateSimulator &sim_device, const column_vector& params,
167 hqcl::SymbolicOperator &symb_op, hqcl::QWCMap &qwc_groups) {
168 double total_cost = 0.0;
169
170 for (auto &qwc_group : qwc_groups) {
171 std::vector<double> variable_params;
172 variable_params.reserve(N * 2);
173
174 hqcl::SymbolicOperatorUtils::applyBasisChange(qwc_group.second, variable_params, N);
175
176 std::vector<std::reference_wrapper<qbit>> qids;
177 for (int qubit = 0; qubit < N; ++qubit)
178 qids.push_back(std::ref(QReg[qubit]));
179
180 // Set all the mapping angles to the default of 0.
181 for (int map_index = 0; map_index < N_map_angles; map_index++)
182 QMapParams[map_index] = 0;
183
184 for (auto indx = 0; indx < variable_params.size(); ++indx)
185 QMapParams[indx] = variable_params[indx];
186
187 // Perform the experiment, Store the data in ProbReg
188 TFD_full();
189 std::vector<double> ProbReg = sim_device.getProbabilities(qids);
190
191 double current_pstr_val = hqcl::SymbolicOperatorUtils::getExpectValSetOfPaulis(
192 symb_op, qwc_group.second, ProbReg, N);
193 total_cost += current_pstr_val;
194 }
195
196 return total_cost;
197}
The function runQuantumKernel encompasses all the functionality that is
required to calculate the cost, when running a single optimization iteration
with dlib. It takes the already formulated set of QWC groups, and run
the ansatz with the same set of variational parameters but with different basis
mapping parameters (each time mapping from the different bases, as demanded by
the cost expression). The full cost is then returned for consideration by the
classical optimization loop within dlib.
199int main() {
200 // Setup quantum device
201 iqsdk::IqsConfig sim_config(N, "noiseless", false);
202 iqsdk::FullStateSimulator sim_device(sim_config);
203 assert(sim_device.ready() == iqsdk::QRT_ERROR_SUCCESS);
204
205 // initial starting point. Defining it here means I will reuse the best result
206 // from previous temperature when starting the next temperature run
207 column_vector starting_point = {0, 0, 0, 0};
208
209 // calculate the actual inverse temperature that is used during calculations
210 double inv_temp = 1.0;
211
212 // Fully formulated Cost Function Expression
213 hqcl::SymbolicOperator cost_expr = constructFullSymbOp(inv_temp);
214
215 // Qubitwise Commutation (QWC) Groups Formation
216 hqcl::QWCMap qwc_groups = hqcl::SymbolicOperatorUtils::getQubitwiseCommutationGroups(cost_expr);
217
218 // Construct a function to be used for a single optimization iteration
219 // This function is directly called by the dlib optimization routine
220 auto ansatz_run_lambda = [&](const column_vector& var_angs) {
221
222 // Set all the variational angles to input values.
223 for (int q_index = 0; q_index < N_map_angles; q_index++)
224 QVarParams[q_index] = var_angs(q_index);
225
226 // run the kernel to compute the total cost
227 double total_cost = runQuantumKernel(sim_device, var_angs, cost_expr, qwc_groups);
228
229 return total_cost;
230 };
231
232 // run the full optimization for a given temperature
233 auto result = dlib::find_min_bobyqa(
234 ansatz_run_lambda, starting_point,
235 2 * N_var_angles + 1, // number of interpolation points
236 dlib::uniform_matrix<double>(N_var_angles, 1, -7.0), // lower bound constraint
237 dlib::uniform_matrix<double>(N_var_angles, 1, 7.0), // upper bound constraint
238 1.5, // initial trust region radius
239 1e-5, // stopping trust region radius
240 10000 // max number of objective function evaluations
241 );
242
243 return 0;
244}
The main function shown in Listing 21 will initialize the IQSDK backend,
construct the cost
expression, and kick off the optimization. The lambda function
ansatz_run_lambda is used since dlib requires the function used during
optimization to take a column vector as an input and to return a double. This
function essentially wraps the previously-defined runQuantumKernel function.
Results¶
The execution of the above program can be tracked with a log of the angles and the cost function at each iteration. The summarized results are shown in Fig. 2 and Fig. 3. These plots demonstrate that 95 steps are required for convergence to the requested tolerance level.
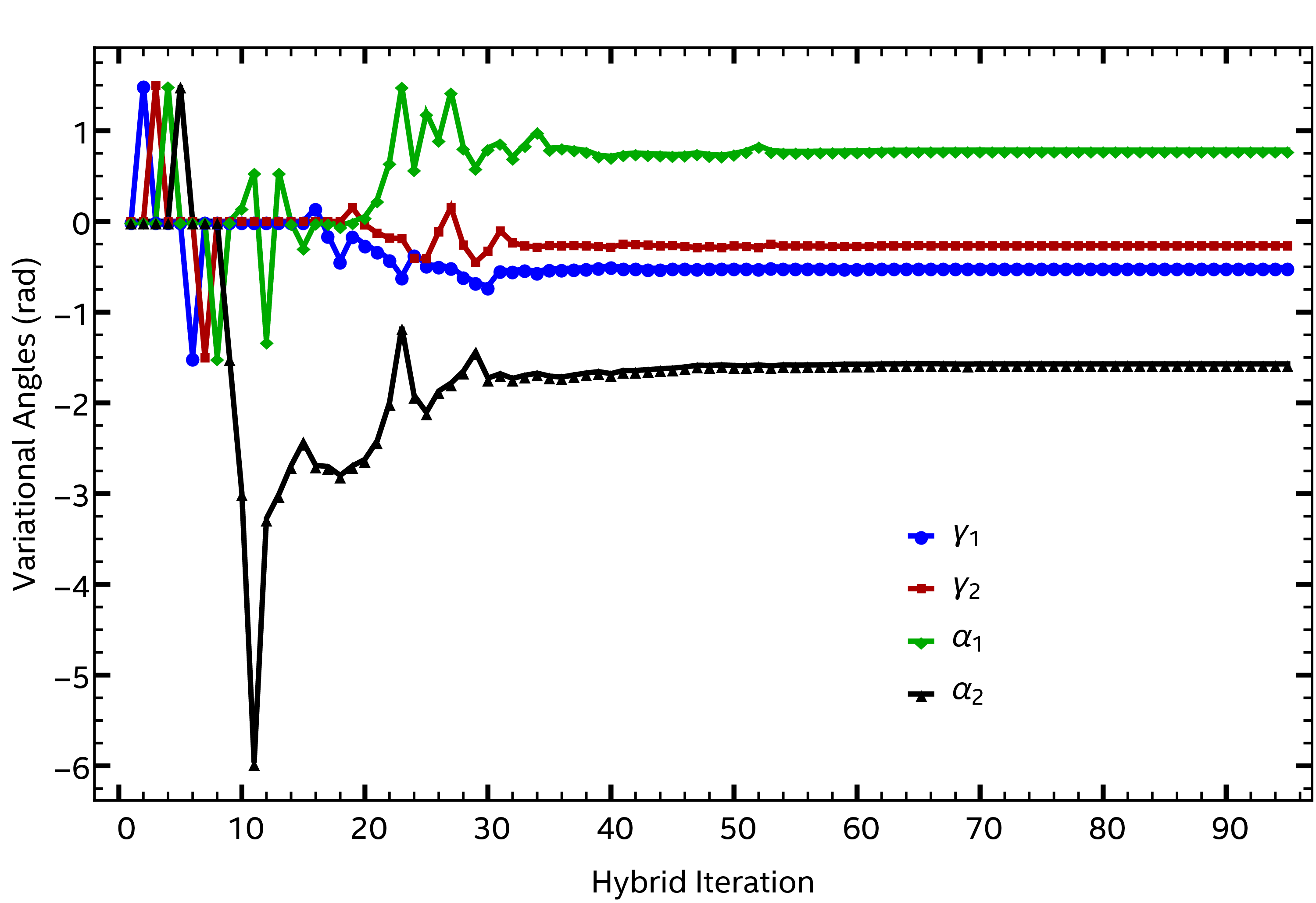
Fig. 2 Convergence behavior for the four variational angles (see [PM20] [SPK+21] for details on the notation).¶
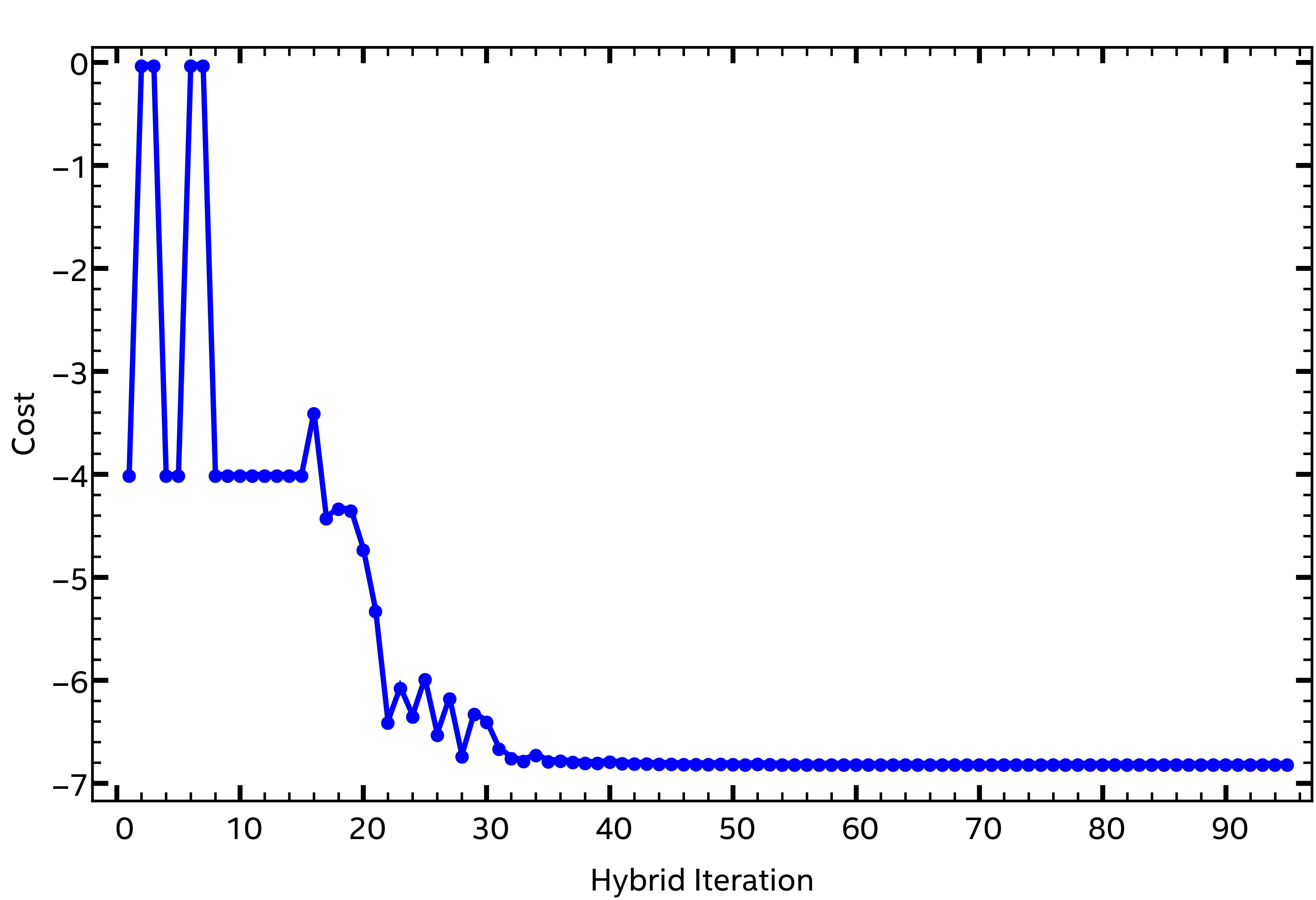
Fig. 3 Convergence of the evaluated cost during the variational algorithm execution.¶
Using qbit variables¶
qbit is the data type for representing qubits. Variables of qbit type can be declared in the global
namespace or locally within a quantum_kernel function. Similar to locally declared classical C++ variables,
locally declared qbit variables’ scope is limited to the quantum_kernel function they are declared in.
When a locally declared qbit variable goes out of scope, the quantum state is not automatically released.
This means in subsequent computation, the physical qubit associated to this variable might be reassgined to a different qbit while
still holding the now out-of-scope variable’s quantum state. Without proper handling, this could lead to unreliable
results. One option is to use release_quantum_state() at the end of the quantum_kernel in which local qbit
variables are declared. See Local qbit Variables. Examples can be found below:
qbit global_qbit;
void quantum_kernel exampleReleaseOnMeasurement(){
qbit local_3[3]; // declare a quantum array with 3 qbits
// Prep the local qbit variables
PrepZ(local_3[0]);
PrepZ(local_3[1]);
PrepZ(local_3[2]);
RY(local_3[0], 0.5);
RY(local_3[1], 0.5);
RY(local_3[2], 0.5);
// Measuring the qbit variables
MeasX(local_3[0]);
MeasX(local_3[1]);
MeasX(local_3[2]);
// After the measurements, the physical qubits assigned to local_3 are released
}
void quantum_kernel exampleExplicitRelease() {
qbit q0;
qbit q1;
PrepZ(q0);
PrepZ(q1);
RZ(q0);
RZ(q1);
RZ(global_qbit);
release_quantum_state();
// After the call to release_quantum_state(), all qubits, including the global qbit,
// are released from this point onwards and the physical qubits can be
// reused in a new ``quantum_kernel``
}
void quantum_kernel badExampleNoRelease() {
// In this example, the local qubits are not properly released at the end of the kernel
qbit q0;
qbit q1;
PrepZ(q0);
PrepZ(q1);
RZ(q0);
RZ(q1);
}
void quantum_kernel badExample() {
// This program will not cause a compilation error
// However the computed results might be incorrect
// as the second call to badExampleNoRelease() might be using the same
// physical qubits which are in unknown states
badExampleNoRelease();
badExampleNoRelease();
}
qbit variables can be passed as arguments of quantum_kernel functions with the exception of top level
quantum_kernel functions, which do not take quantum-type parameters.
qbit variables must be passed by reference.
If passed by value, a local copy of the input qbit variables will be made,
just as for classical variables.
Since quantum states cannot be copied, passing a qbit by value has no physical
meaning and will cause an error when compiling, .
Examples of how to pass qbit variables as inputs to
quantum_kernel functions are shown below.
qbit global_qbit;
// Pass by pointer - accepted behaviour
void quantum_kernel passQubitArrayByPtr(qbit qubit_array[], int num_ele){
for (int i=0; i < num_ele; i++)
H(qubit_array[i]);
}
// Pass by pointer - accepted behaviour
void quantum_kernel passQubitArrayByPtr2(qbit *qubit_array, int num_ele){
for (int i=0; i < num_ele; i++)
H(qubit_array[i]);
}
// Pass by reference - accepted behaviour
void quantum_kernel passQubitByRef(qbit &q){
Z(q);
}
// Pass by value - will result in a compilation error
void quantum_kernel passQubitByValue(qbit q){
Z(q);
}
// Note that the top level quantum_kernel does not take quantum arguments
void quantum_kernel top_level_kernel() {
qbit qubit_array[3];
passQubitArrayByPtr(qubit_array, 3);
passQubitArrayByPtr2(qubit_array, 3);
passQubitByRef(global_qbit);
passQubitByValue(global_qbit); // Pass by value - will result in a compilation error
}
The minimum number of physical qubits required in a program is the sum of all global qbit variables plus the
maximum width of local qbit variables. In the following example, the minimum number of physical qubits needed
is 8, comprising the 3 global qbit and the 5 qbit inside circuitWidth5.
qbit global_qbit[3];
void quantum_kernel circuitWidth2(){
qbit array[2];
}
void quantum_kernel circuitWidth5(){
qbit array[5];
}
void quantum_kernel circuits(){
circuitWidth2();
circuitWidth5();
}
When compiling with a configuration file, the qbit variables will be mapped to physical qubits using
the placement method set by the -p flag. All qbit variables, both global and locally declared, will
be mapped using the same method, with the exception that only global qbit variables can be mapped by
user defined mapping. See Qubit Placement and Scheduling.