Introduction#
The Intel® Query Processing Library (Intel® QPL) can be used to improve performance of database, enterprise data, communications, and scientific/technical applications. Intel QPL provides interfaces for a number of commonly used algorithms. Using this library enables you to automatically tune your application to many generations of processors without changing your application. Intel QPL provides high performance implementations of data processing functions for existing hardware accelerator, and/or software path if the hardware accelerator is not available. Code written with the library automatically takes advantage of available modern CPU capabilities. This can provide tremendous development and maintenance savings. The goal of Intel QPL is to provide application programming interface (API) with:
C and C++ compatible interfaces and data structures to enhance usability and portability
Faster time to market
Scalability with Intel® In-Memory Analytics Accelerator (Intel® IAA) hardware
Intel® In-Memory Analytics Accelerator (Intel® IAA) Overview#
The Intel QPL library uses Intel IAA hardware that provides compression and decompression of very high throughput combined with analytic primitive functions. The primitive functions are commonly used for data filtering during analytic query processing.
The device supports formats such as Huffman encoding and Deflate. For the Deflate format, it supports indexing the compressed stream for efficient random access.
Intel IAA is specifically designed for the following use cases:
Big data applications and in-memory analytic databases.
Application-transparent usages, such as memory page compression.
Data integrity operations, such as CRC-64.
For more detailed information about these use cases, refer to the Intel IAA page.
For the details on accelerator architecture, refer to the Intel IAA Architecture Specification.
Functionality Overview#
Intel® Query Processing Library (Intel® QPL) consists of two main functional blocks: analytics and compression.
The analytics part contains two sub-blocks: Decompress and Filter. These functions are tied together, so that each analytics operation can perform decompress-only, filter-only, or decompress-and-filter processing, as illustrated in the figure below.
Alternatively, you can compress the input with the compression part.
Decompress SQL Filter Decompress
Bypass Bypass Output
/------------------\ |\ /--------------------\
| +--------------+ | | \ | +-------------+ | |\
Source1 | | DEFLATE | \-->| |-+->| SQL Filter | \---->| \
-----------+-| Decompressor |---->| / | Functions |-------->| |------------>
| +--------------+ |/ +-------------+ | / Analytics
| Decompress | | |/ Engine Output
Source2 | Config/State | | SQL Filter
-----------(--------------(----------------------/ Output
| Compress | Filter Optional
| Config/State | Second Input
| |
| +--------------+
| | DEFLATE |
+-| Compressor |----------------------------------------------------->
+--------------+
Intel® Query Processing Library (Intel® QPL) pipeline
With the library, you can store columnar databases in a compressed form, decreasing memory footprint. In addition to increased effective memory capacity, this also reduces memory bandwidth by executing the filter function used for database queries “on the fly”, avoiding use of memory bandwidth for uncompressed raw data transfer.
Intel QPL supports decompression compatible with the Deflate compression standard described in RFC 1951. The uncompressed data may be written directly to memory or passed to the input of the filter function.
Attention
In Intel QPL, compression is always done using a history buffer size of 4 KB.
Decompression is supported for Deflate streams where the size of the
history buffer is no more than 4 KB, otherwise QPL_STS_BAD_DIST_ERR code is
returned.
The library also supports Deflate compression, along with the calculation of arbitrary CRCs.
The SQL filter function block takes one or two input streams, a primary input, and an optional secondary input. The primary input may be read from memory or received from the decompression block. The second input, if used, is always read from memory. The data streams logically contain an array of unsigned values, but they may be formatted in any of several ways, e.g., as a packed array. If the bit-width of the values is 1, the stream will be referenced as a “bit-vector”, otherwise, it will be referenced as an “array”.
The output of the filter function may be either an array or a bit vector, depending on the function.
In addition to generating output data, Intel QPL computes a 32-bit CRC of the uncompressed data (either the result of decompression, or the direct input to the filter function), the XOR checksum of this data, and several “aggregates” of the output data. The CRC, XOR checksum, and aggregates are written to the completion record.
Architecture Overview#
The diagram below includes both the architecture of Intel QPL and the external components that the library interacts with. The components in the diagram are numbered from 0 to 9, each with a short description.
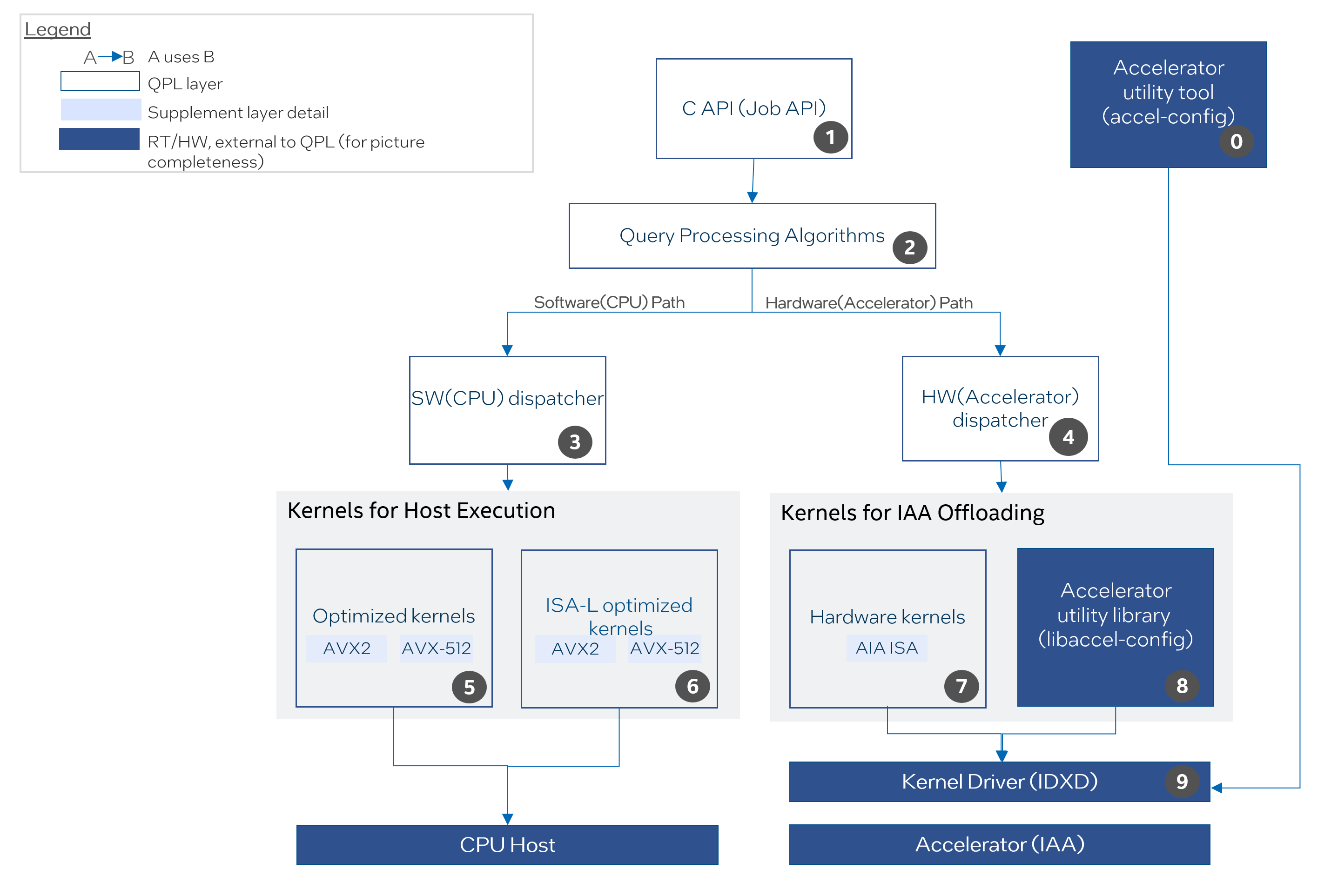
Architecture Diagram of Intel QPL#
Users should use the accelerator utility tool (
accel-config), which cooperates with Intel® Data Accelerator Driver (idxd), to pre-configure Intel IAA hardware.C Job API is compatible with C and C++.
Contains the sequences of steps, including optimized function calls or accelerator operations, needed to handle specific query processing cases, and returns appropriate status back to users.
The CPU dispatcher detects what instruction sets are available in CPU.
The accelerator dispatcher detects available capabilities in Intel IAA hardware and records available devices and workqueues.
Set of optimized kernels for CPU that can be used if Intel IAA hardware is not available on the platform.
Set of optimized kernels for CPU, which are adopted from Intel® Intelligent Storage Acceleration Library (Intel® ISA-L). Intel QPL keeps its own copy of relevant source code from Intel ISA-L.
Set of low-level descriptors and service functions for interaction with Intel IAA hardware using Intel® Accelerator Interfacing Architecture.
The accelerator utility library (
libaccel-config), which is linked to Intel QPL, provides APIs for communicating with Intel IAA hardware.The Intel® Data Accelerator Driver (
idxd) is a kernel driver that manages Intel IAA devices.
Features#
Operations#
Intel QPL supports:
Deflate compression/decompression with the history size limited to 4 KB
Huffman-only compression/decompression
Filter operations
Warning
The implementation of Huffman-only compression/decompression is in progress.
Execution Paths#
Intel QPL supports several execution paths that help to achieve the optimal system resources utilization:
Hardware Path- requested functionality will be executed by Intel IAA. If an operation is not supported by the accelerator, corresponding error code will be returned.Software Path- requested functionality will be executed on the CPU host.Auto Path- library will always attempt to execute on the accelerator first. If a functionality is not supported by the accelerator or execution on Intel IAA fails (for example, due to the accelerator initialization error), fallback to the CPU host will be used.
Attention
Currently, there are several specifics to consider when using Auto Path.
Please refer to Asynchronous Execution and Auto Path,
Limitations for Compression and Decompression across multiple jobs
and Page Faults Handling for more details.
Intel QPL also doesn’t provide an API to query if execution happened on the accelerator or host for Auto Path.
To check whether host fallback happens in a job, Intel QPL could be built with the
option -DLOG_HW_INIT=ON, which prints diagnostic message about accelerator initialization,
execution path, and other useful information.
Devices Selection and NUMA Support#
To select a device for execution, Intel QPL uses the dispatcher that detects all configured devices and work queues on the system and selects the most appropriate device for the requested operation.
When selecting a device for executing the requested operation, the dispatcher considers the following:
Device capabilities (e.g., supported operations).
Device configuration (e.g., max transfer size).
Device state (e.g., device is busy or not).
Device NUMA node ID (in case of NUMA-aware selection, see below for details).
Intel QPL supports NUMA-aware device selection. If the user wants to select devices only from a specific NUMA node, they can set the NUMA ID parameter of the job to the specific node ID:
qpl_job *qpl_job_ptr;
job->numa_id = <int32_t>;
By default (i.e., when job->numa_id is set to default -1 value),
the library selects devices from any NUMA node within the socket of the calling thread.
Attention
The library behavior changed starting from Intel QPL 1.6.0.
Previously, the library only selected devices from the NUMA node of the calling thread
and the flags QPL_DEVICE_NUMA_ID_ANY, QPL_DEVICE_NUMA_ID_SOCKET,
and QPL_DEVICE_NUMA_ID_CURRENT were not available.
Starting from Intel QPL 1.6.0 release, the library can be configured to select devices from a NUMA node of the calling thread or to use any available device from the system. To configure the behavior of the device dispatcher, use the following environment variables:
QPL_DEVICE_NUMA_ID_ANYto select any device available on the system.QPL_DEVICE_NUMA_ID_SOCKETto select devices from any NUMA node within the socket of the calling thread (e.g., when jobs need to be reset to the default value).QPL_DEVICE_NUMA_ID_CURRENTto select devices from the NUMA node of the calling thread.
Note
To bind the library to a specific NUMA node, numactl --cpunodebind <numa_id> --membind <numa_id> /path/to/executable can be used.
Page Faults Handling#
If a page fault occurs during operations supported by Intel QPL on Intel IAA, no partial completion is available and the operation must be resubmitted to the device.
If Block on Fault is set (that is, the block_on_fault attribute must be set to 1
with the accel-config for each work queue), the device waits for page faults to be resolved
and then continues the operation.
If the user, for performance or any other reason, chooses to not rely on Block on Fault
(that is, the block_on_fault attribute is set to 0), Intel QPL tries to resolve a page fault
on the software level and then resubmit the operation to the device.
In the case of Hardware Path, single resubmission to the device is attempted, and, in the case of the failure,
QPL_STS_INTL_PAGE_FAULT or QPL_STS_INTL_W_PAGE_FAULT is returned.
In the case of Auto Path, single resubmission to the device is attempted, and, in the case of the failure,
the operation is continued on the Software Path.
Refer to Getting Configured Accelerator Properties in User Application for more details on setting block_on_fault and other attributes.
Getting Configured Accelerator Properties in User Application#
Intel(R) QPL behavior depends on accelerator configuration. There is a limitation on qpl_job.available_in and qpl_job.available_out
based on configured max_transfer_size. There is also a behavior dependent on block_on_fault described in Page Faults Handling.
If you need to identify these limitations or expected behavior, query the accelerator configuration.
Intel(R) QPL does not support APIs to check accelerator configuration. Use the accel-config
library directly. See the example of checking max_transfer_size in Multi-chunk Compression with Fixed Block.
Work Queue Support#
Intel® In-Memory Analytics Accelerator (Intel® IAA) 2.0 supports the ability to configure which operations are supported using the OPCFG register.
As of Intel QPL 1.3.0 or higher with libaccel-config library version 4.0
or higher, the device dispatcher respects each work queue’s OPCFG register.
The operation isn’t submitted to work queues that do not support it and returns a
QPL_STS_NOT_SUPPORTED_BY_WQ status if no available work queue supports the operation.
In the case of older Intel QPL version, operations are submitted to any available work queue. This may result in errors when the work queue does not support the operation.
In the case of an older Intel IAA or libaccel-config version without OPCFG support, no issues
would arise as work queues would allow all available operations.
Limitations#
Library does not work with Dedicated Work Queues on the accelerator, but uses Shared Work Queues only.
Library does not have APIs for the hardware path configuration.
Library does not have APIs for
Load Balancingfeature customization.Library does not support hardware path on Windows OS.
Library is not developed for kernel mode usage. It is user level driver library.
APIs#
Intel QPL provides Low-Level C API, that represents a state-based interface. The base idea is to allocate a single state and configure one with different ways to perform necessary operation. All memory allocations are happening on user side or via user-provided allocators. See Low-Level C API Key Concepts for more details.