Layer Wise Quantization (LWQ)
Introduction
Large language models (LLMs) have shown exceptional performance across various tasks, meanwhile, the substantial parameter size poses significant challenges for deployment. Layer-wise quantization(LWQ) can greatly reduce the memory footprint of LLMs, usually 80-90% reduction, which means that users can quantize LLMs even on single node using GPU or CPU. We can quantize the model under memory-constrained devices, therefore making the huge-sized LLM quantization possible.
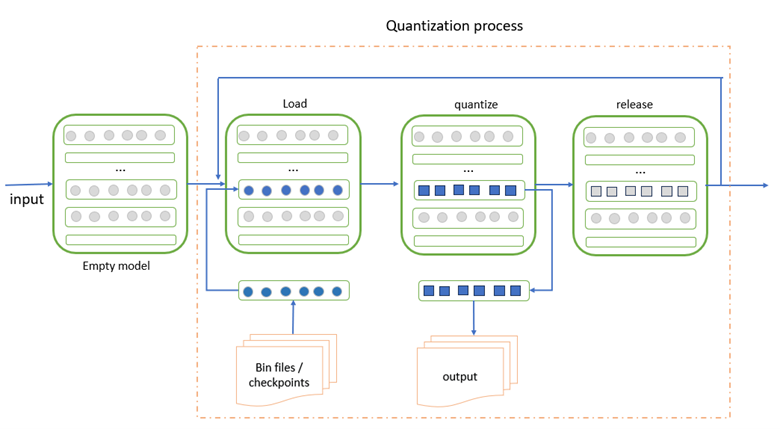
Figure 1: The process of layer-wise quantization for PyTorch model. The color grey means empty parameters and the color blue represents parameters need to be quantized. Every rectangle inside model represents one layer.
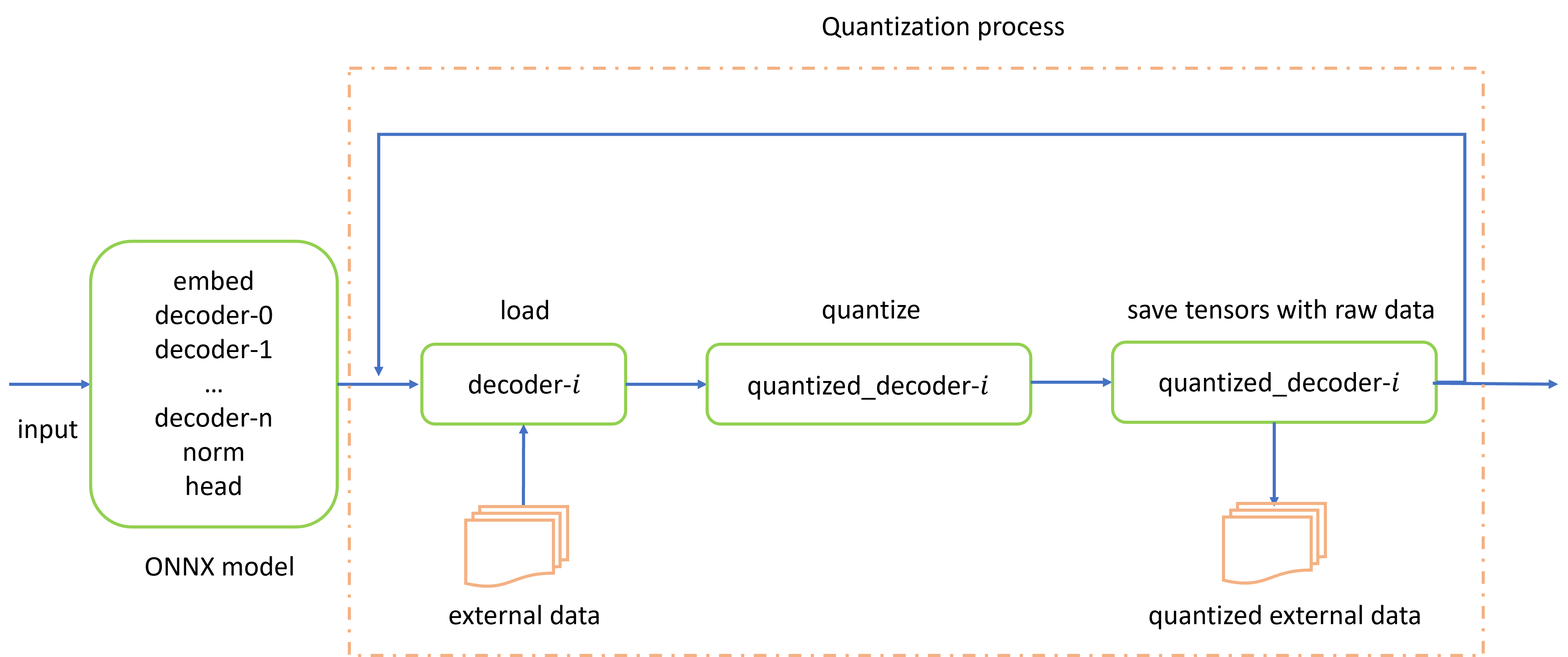
Figure 2: The process of layer-wise quantization for ONNX model. The graph of LLM is split into several parts, and each subgraph is quantized in turn.
Supported Framework Model Matrix
| Types/Framework | PyTorch | ONNX Runtime | |
|---|---|---|---|
| W8A8 Post Training Static Quantization | ✔ | ✔ | |
| Weight-only Quantization | RTN | ✔ | ✕ |
| AWQ | ✕ | ||
| GPTQ | ✔ | ||
| TEQ | ✕ | ||
Examples
PyTorch framework example
from neural_compressor import PostTrainingQuantConfig, quantization
from neural_compressor.adaptor.torch_utils.layer_wise_quant import load_empty_model
fp32_model = load_empty_model(model_name_or_path, torchscript=True)
conf = PostTrainingQuantConfig(
approach="weight_only",
recipes={
"layer_wise_quant": True,
"rtn_args": {"enable_full_range": True},
},
)
q_model = quantization.fit(
fp32_model,
conf,
calib_dataloader=eval_dataloader,
eval_func=lambda x: 0.1,
)
ouput_dir = "./saved_model"
q_model.save(ouput_dir)
q_model = load(ouput_dir, fp32_model, weight_only=True, layer_wise=True)
ONNX Runtime framework example
from neural_compressor import quantization, PostTrainingQuantConfig
conf = PostTrainingQuantConfig(recipes={"layer_wise_quant": True})
q_model = quantization.fit(fp32_model_path, conf, calib_dataloader=dataloader)
q_model.save(int8_model_path)
Refer to ONNX Runtime llama-2 LWQ example