Neural Insights
Neural Insights is a web application for easier use of Intel® Neural Compressor diagnosis feature.
It provides the capability to show the model graph, histograms of weights and activations, quantization configs, etc.
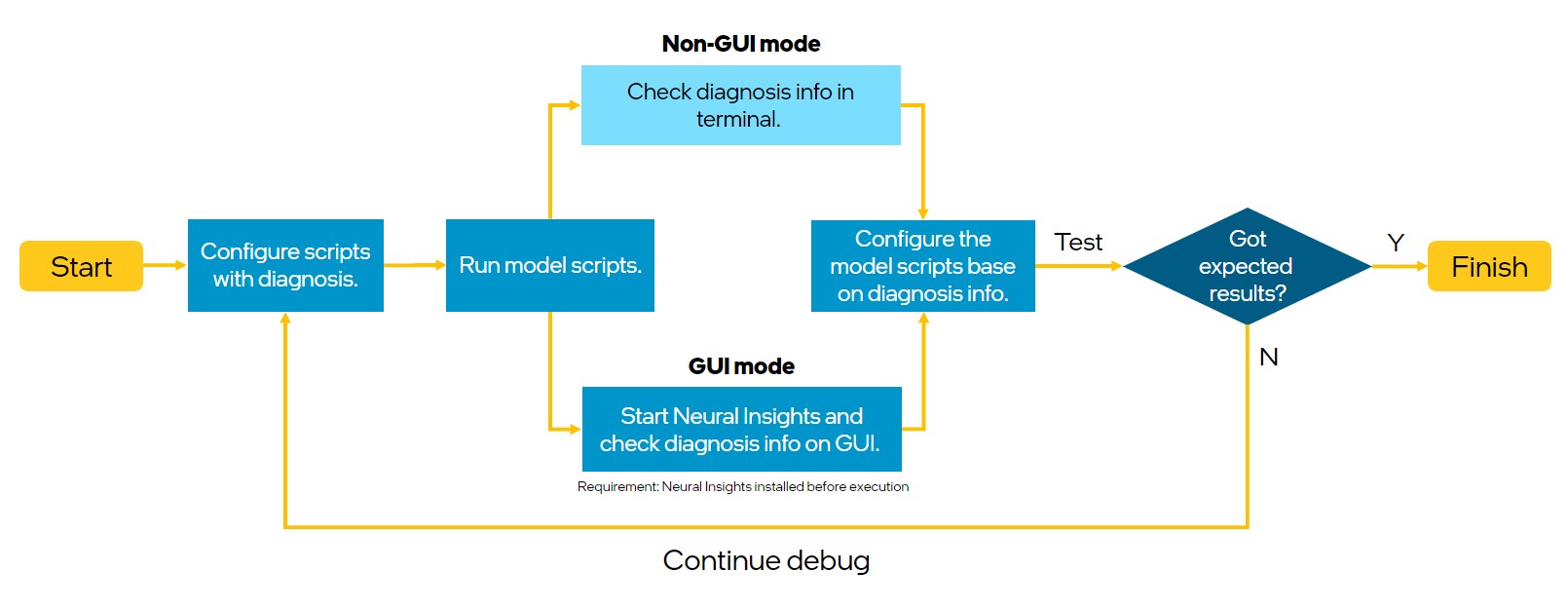
The workflow shows the relationship of Neural Insights and diagnosis.
Installation
Installation of Neural Insights is possible in one of following ways:
Install from pypi
pip install neural-insights
Install from Source
# Install Neural Compressor
git clone https://github.com/intel/neural-compressor.git
cd neural-compressor
pip install -r requirements.txt
python setup.py install
# Install Neural Insights
pip install -r neural_insights/requirements.txt
python setup.py install neural_insights
Getting Started
Start the Neural Insights
To start the Neural Insights server execute neural_insights command:
neural_insights
The server generates a self-signed TLS certificate and prints instruction how to access the Web UI.
Neural Insights Server started.
Open address https://10.11.12.13:5000/?token=338174d13706855fc6924cec7b3a8ae8
Server generated certificate is not trusted by your web browser, you will need to accept usage of such certificate.
You might also use additional parameters and settings:
Neural Insights listens on port 5000. Make sure that port 5000 is accessible to your browser (you might need to open it in your firewall), or specify different port that is already opened, for example 8080:
neural_insights -p 8080
To start the Neural Insights server with your own TLS certificate add
--certand--keyparameters:neural_insights --cert path_to_cert.crt --key path_to_private_key.key
To start the Neural Insights server without TLS encryption use
--allow-insecure-connectionsparameter:neural_insights --allow-insecure-connectionsThis enables access to the server from any machine in your local network (or the whole Internet if your server is exposed to it).
You are forfeiting security, confidentiality and integrity of all client-server communication. Your server is exposed to external threats.
Quantization with Python API
# Install Intel Neural Compressor and TensorFlow
pip install neural-compressor
pip install neural-insights
pip install tensorflow
# Prepare fp32 model
wget https://storage.googleapis.com/intel-optimized-tensorflow/models/v1_6/mobilenet_v1_1.0_224_frozen.pb
from neural_compressor import Metric
from neural_compressor.config import PostTrainingQuantConfig
from neural_compressor.data import DataLoader
from neural_compressor.data import Datasets
top1 = Metric(name="topk", k=1)
dataset = Datasets("tensorflow")["dummy"](shape=(1, 224, 224, 3))
dataloader = DataLoader(framework="tensorflow", dataset=dataset)
from neural_compressor.quantization import fit
q_model = fit(
model="./mobilenet_v1_1.0_224_frozen.pb",
conf=PostTrainingQuantConfig(diagnosis=True),
calib_dataloader=dataloader,
eval_dataloader=dataloader,
eval_metric=top1,
)
When the quantization is started, the workload should appear on the Neural Insights page and successively, new information should be available while quantization is in progress (such as weights distribution and accuracy data).
Note that above example uses dummy data which is used to describe usage of Neural Insights. For diagnosis purposes you should use real dataset specific for your use case.
Tensor dump examples
Step by Step Diagnosis Example
Refer to Step by Step Diagnosis Example with TensorFlow and Step by Step Diagnosis Example with ONNXRT to get started with some basic quantization accuracy diagnostic skills.
Research Collaborations
Welcome to raise any interesting research ideas on model compression techniques and feel free to reach us (inc.maintainers@intel.com). Look forward to our collaborations on Neural Insights!