Export
Introduction
Open Neural Network Exchange (ONNX) is an open standard format for representing machine learning models. Exporting FP32 PyTorch/Tensorflow models has become popular and easy to use. For Intel Neural Compressor, we hope to export the INT8 model into the ONNX format to achieve higher applicability in multiple frameworks.
Here is the workflow of our export API for PyTorch/Tensorflow FP32/INT8 model.
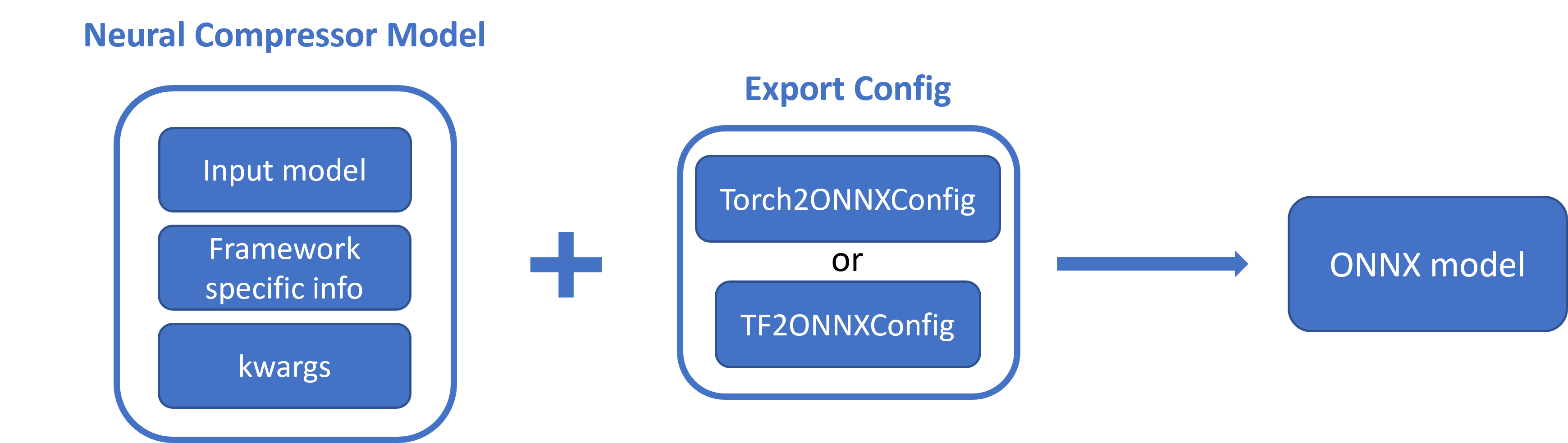
Supported Framework Model Matrix
| Framework | model type | exported ONNX model type |
|---|---|---|
| PyTorch | FP32 | FP32 |
| Post-Training Static Quantized INT8 | QOperator/QDQ INT8 | |
| Post-Training Dynamic Quantized INT8 | QOperator INT8 | |
| Quantization-aware Training INT8 | QOperator/QDQ INT8 | |
| TensorFlow | FP32 | FP32 |
| Post-Training Static Quantized INT8 | QDQ INT8 | |
| Quantization-aware Training INT8 | QDQ INT8 |
Examples
PyTorch Model
FP32 Model Export
from neural_compressor.experimental.common import Model
from neural_compressor.config import Torch2ONNXConfig
inc_model = Model(model)
fp32_onnx_config = Torch2ONNXConfig(
dtype="fp32",
example_inputs=torch.randn(1, 3, 224, 224),
input_names=["input"],
output_names=["output"],
dynamic_axes={
"input": {0: "batch_size"},
"output": {0: "batch_size"},
},
)
inc_model.export("fp32-model.onnx", fp32_onnx_config)
INT8 Model Export
# q_model is a Neural Compressor model after performing quantization.
from neural_compressor.config import Torch2ONNXConfig
int8_onnx_config = Torch2ONNXConfig(
dtype="int8",
opset_version=14,
quant_format="QOperator", # or QDQ
example_inputs=torch.randn(1, 3, 224, 224),
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}},
)
q_model.export("int8-model.onnx", int8_onnx_config)
Note: Two export examples covering computer vision and natural language processing tasks exist in examples. Users can leverage them to verify the accuracy and performance of the exported ONNX model.
Tensorflow Model
FP32 Model Export
from neural_compressor.experimental.common import Model
from neural_compressor.config import TF2ONNXConfig
inc_model = Model(model)
config = TF2ONNXConfig(dtype="fp32")
inc_model.export("fp32-model.onnx", config)
INT8 Model Export
# q_model is a Neural Compressor model after performing quantization.
from neural_compressor.config import TF2ONNXConfig
config = TF2ONNXConfig(dtype="int8")
q_model.export("int8-model.onnx", config)
Note: Some export examples of computer vision task exist in examples. Users can leverage them to verify the accuracy and performance of the exported ONNX model.
Appendix
Supported quantized ops
This table lists the TorchScript operators that are supported by ONNX export with torch v2.0. Refer to this link for more supported/unsupported ops.
| Operator | opset_version(s) |
|---|---|
quantized::add |
Since opset 10 |
quantized::add_relu |
Since opset 10 |
quantized::cat |
Since opset 10 |
quantized::conv1d_relu |
Since opset 10 |
quantized::conv2d |
Since opset 10 |
quantized::conv2d_relu |
Since opset 10 |
quantized::group_norm |
Since opset 10 |
quantized::hardswish |
Since opset 10 |
quantized::instance_norm |
Since opset 10 |
quantized::layer_norm |
Since opset 10 |
quantized::leaky_relu |
Since opset 10 |
quantized::linear |
Since opset 10 |
quantized::mul |
Since opset 10 |
quantized::sigmoid |
Since opset 10 |
Note: The export function may fail due to unsupported operations. Please fallback unsupported quantized ops by setting ‘op_type_dict’ or ‘op_name_dict’ in ‘QuantizationAwareTrainingConfig’ or ‘PostTrainingQuantConfig’ config. Fallback examples please refer to Text classification