PyTorch Weight Only Quantization
Introduction
As large language models (LLMs) become more prevalent, there is a growing need for new and improved quantization methods that can meet the computational demands of these modern architectures while maintaining the accuracy. Compared to normal quantization like W8A8, weight only quantization is probably a better trade-off to balance the performance and the accuracy, since we will see below that the bottleneck of deploying LLMs is the memory bandwidth and normally weight only quantization could lead to better accuracy.
Model inference: Roughly speaking , two key steps are required to get the model’s result. The first one is moving the model from the memory to the cache piece by piece, in which, memory bandwidth $B$ and parameter count $P$ are the key factors, theoretically the time cost is $P*4 /B$. The second one is computation, in which, the device’s computation capacity $C$ measured in FLOPS and the forward FLOPs $F$ play the key roles, theoretically the cost is $F/C$.
Text generation: The most famous application of LLMs is text generation, which predicts the next token/word based on the inputs/context. To generate a sequence of texts, we need to predict them one by one. In this scenario, $F\approx P$ if some operations like bmm are ignored and past key values have been saved. However, the $C/B$ of the modern device could be to 100X, that makes the memory bandwidth as the bottleneck in this scenario.
Besides, as mentioned in many papers[1][2], activation quantization is the main reason to cause the accuracy drop. So for text generation task, weight only quantization is a preferred option in most cases.
Theoretically, round-to-nearest (RTN) is the most straightforward way to quantize weight using scale maps. However, when the number of bits is small (e.g. 3), the MSE loss is larger than expected. A group size is introduced to reduce elements using the same scale to improve accuracy.
Supported Matrix
| Algorithms/Backend | PyTorch eager mode |
|---|---|
| RTN | ✔ |
| GPTQ | ✔ |
| AutoRound | ✔ |
| AWQ | ✔ |
| TEQ | ✔ |
| HQQ | ✔ |
| > RTN: A quantification method that we can think of very intuitively. It does not require additional datasets and is a very fast quantization method. Generally speaking, RTN will convert the weight into a uniformly distributed integer data type, but some algorithms, such as Qlora, propose a non-uniform NF4 data type and prove its theoretical optimality. |
GPTQ: A new one-shot weight quantization method based on approximate second-order information, that is both highly-accurate and highly efficient[4]. The weights of each column are updated based on the fixed-scale pseudo-quantization error and the inverse of the Hessian matrix calculated from the activations. The updated columns sharing the same scale may generate a new max/min value, so the scale needs to be saved for restoration.
AutoRound: AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It’s tailored for a wide range of models and consistently delivers noticeable improvements, often significantly outperforming SignRound[5] with the cost of more tuning time for quantization.
AWQ: Proved that protecting only 1% of salient weights can greatly reduce quantization error. the salient weight channels are selected by observing the distribution of activation and weight per channel. The salient weights are also quantized after multiplying a big scale factor before quantization for preserving.
TEQ: A trainable equivalent transformation that preserves the FP32 precision in weight-only quantization. It is inspired by AWQ while providing a new solution to search for the optimal per-channel scaling factor between activations and weights.
HQQ: The HQQ[6] method focuses specifically on minimizing errors in the weights rather than the layer activation. Additionally, by incorporating a sparsity-promoting loss, such as the $l_{p<1}$-norm, we effectively model outliers through a hyper-Laplacian distribution. This distribution more accurately captures the heavy-tailed nature of outlier errors compared to the squared error, resulting in a more nuanced representation of error distribution.
Usage
Get Started
WeightOnlyQuant quantization for PyTorch is using prepare and convert APIs.
Common arguments
| Config | Capability |
|---|---|
| dtype (str) | ['int', 'nf4', 'fp4'] |
| bits (int) | [1, ..., 8] |
| group_size (int) | [-1, 1, ..., $C_{in}$] |
| use_sym (bool) | [True, False] |
| quant_lm_head (bool) | [False, True] |
| use_double_quant (bool) | [True, False] |
| double_quant_dtype (str) | ['int'] |
| double_quant_bits (int) | [1, ..., bits] |
| double_quant_use_sym (bool) | [True, False] |
| double_quant_group_size (int) | [-1, 1, ..., $C_{in}$] |
Notes:
group_size = -1 refers to per output channel quantization. Taking a linear layer (input channel = $C_{in}$, output channel = $C_{out}$) for instance, when group size = -1, quantization will calculate total $C_{out}$ quantization parameters. Otherwise, when group_size = gs quantization parameters are calculate with every $gs$ elements along with the input channel, leading to total $C_{out} \times (C_{in} / gs)$ quantization parameters.
4-bit NormalFloat(NF4) is proposed in QLoRA[7]. ‘fp4’ includes fp4_e2m1 and fp4_e2m1_bnb. By default, fp4 refers to fp4_e2m1_bnb.
quant_lm_head defaults to False. This means that, except for transformer blocks, the last layer in transformer models will not be quantized by default. The last layer may be named “lm_head”, “output_layer” or “embed_out”.
Only RTN and GPTQ support double quant.
RTN
| rtn_args | comments | default value |
|---|---|---|
| group_dim (int) | Dimension for grouping | 1 |
| use_full_range (bool) | Enables full range for activations | False |
| use_mse_search (bool) | Enables mean squared error (MSE) search | False |
| use_layer_wise (bool) | Enables quantize model per layer | False |
| model_path (str) | Model path that is used to load state_dict per layer |
Notes:
model_pathis only used when use_layer_wise=True.layer-wiseis stay-tuned.
# Quantization code
from neural_compressor.torch.quantization import prepare, convert, RTNConfig
quant_config = RTNConfig()
model = prepare(model, quant_config)
model = convert(model)
GPTQ
| gptq_args | comments | default value |
|---|---|---|
| use_mse_search (bool) | Enables mean squared error (MSE) search | False |
| use_layer_wise (bool) | Enables quantize model per layer | False |
| model_path (str) | Model path that is used to load state_dict per layer | |
| use_double_quant (bool) | Enables double quantization | False |
| act_order (bool) | Whether to sort Hessian's diagonal values to rearrange channel-wise quantization order | False |
| hybrid_act_order (bool) | Enables Group Aware activations Reordering (GAR): elements can be reordered within each group and the groups themselves can also be reordered, but elements cannot move between groups | False |
| percdamp (float) | Percentage of Hessian's diagonal values' average, which will be added to Hessian's diagonal to increase numerical stability | 0.01 |
| block_size (int) | Execute GPTQ quantization per block, block shape = [C_out, block_size] | 128 |
| static_groups (bool) | Whether to calculate group wise quantization parameters in advance. This option mitigate actorder's extra computational requirements. | False |
| true_sequential (bool) | Whether to quantize layers within a transformer block in their original order. This can lead to higher accuracy but slower overall quantization process. | False |
> Note: model_path is only used when use_layer_wise=True. layer-wise is stay-tuned. |
# Quantization code
from neural_compressor.torch.quantization import prepare, convert, GPTQConfig
quant_config = GPTQConfig()
model = prepare(model, quant_config)
run_fn(model) # calibration
model = convert(model)
DPQ
| dpq_args | comments | default value |
|---|---|---|
| fp8_aware (bool) | Enables an FP8-aware GPTQ quantization flow, where an intermediate FP8 quantization step is applied. | False |
| protective_range (bool) | protective range is added to prevent dequant overflow from INT4 to FP8 (WIP) | False |
from neural_compressor.torch.quantization import prepare, convert, GPTQConfig, HybridGPTQConfig
# Quantization code
quant_config = GPTQConfig()
quant_config.fp8_aware = True
model = prepare(model, quant_config)
run_fn(model) # calibration
model = convert(model)
# Inference code
# This can be implemented in one or two steps. See neural-compressor-fork/examples/fp8_sample/README.html for more details.
model = load(path_to_quantized_model) # loading a model with 4-bit weights
config = HybridGPTQConfig.from_json_file(path_to_measure_json) # measure.json is required
model = prepare(model, config)
run_fn(model) # to measure activation scales from BF16 to FP8
finalize_calibration(model)
config = HybridGPTQConfig.from_json_file(path_to_quant_json) # quant.json is required
model = convert(model, config) # after this step, the model is ready for W4A8 inference
AutoRound
| autoround_args | comments | default value |
|---|---|---|
| enable_full_range (bool) | Whether to enable full range quantization | False |
| batch_size (int) | Batch size for training | 8 |
| lr_scheduler | The learning rate scheduler to be used | None |
| enable_quanted_input (bool) | Whether to use quantized input data | True |
| enable_minmax_tuning (bool) | Whether to enable min-max tuning | True |
| lr (float) | The learning rate | 0 |
| minmax_lr (float) | The learning rate for min-max tuning | None |
| low_gpu_mem_usage (bool) | Whether to use low GPU memory | True |
| iters (int) | Number of iterations | 200 |
| seqlen (int) | Length of the sequence | 2048 |
| n_samples (int) | Number of samples | 512 |
| sampler (str) | The sampling method | "rand" |
| seed (int) | The random seed | 42 |
| n_blocks (int) | Number of blocks | 1 |
| gradient_accumulate_steps (int) | Number of gradient accumulation steps | 1 |
| not_use_best_mse (bool) | Whether to use mean squared error | False |
| dynamic_max_gap (int) | The dynamic maximum gap | -1 |
| scale_dtype (str) | The data type of quantization scale to be used, different kernels have different choices | "float16" |
| scheme (str) | A preset scheme that defines the quantization configurations. | "W4A16" |
| layer_config (dict) | Layer-wise quantization config | None |
# Quantization code
from neural_compressor.torch.quantization import prepare, convert, AutoRoundConfig
quant_config = AutoRoundConfig()
model = prepare(model, quant_config)
run_fn(model) # calibration
model = convert(model)
AWQ
| awq_args | comments | default value |
|---|---|---|
| group_dim (int) | Dimension for grouping | 1 |
| use_full_range (bool) | Enables full range for activations | False |
| use_mse_search (bool) | Enables mean squared error (MSE) search | False |
| use_layer_wise (bool) | Enables quantize model per layer | False |
| use_auto_scale (bool) | Enables best scales search based on activation distribution | True |
| use_auto_clip (bool) | Enables clip range search | True |
| folding(bool) | Allow insert mul before linear when the scale cannot be absorbed by last layer | False. |
> Notes: layer-wise is stay-tuned. |
# Quantization code
from neural_compressor.torch.quantization import prepare, convert, AWQConfig
quant_config = AWQConfig()
model = prepare(model, quant_config, example_inputs=example_inputs)
run_fn(model) # calibration
model = convert(model)
TEQ
| teq_args | comments | default value |
|---|---|---|
| group_dim (int) | Dimension for grouping | 1 |
| use_full_range (bool) | Enables full range for activations | False |
| use_mse_search (bool) | Enables mean squared error (MSE) search | False |
| use_layer_wise (bool) | Enables quantize model per layer | False |
| use_double_quant (bool) | Enables double quantization | False |
| folding(bool) | Allow insert mul before linear when the scale cannot be absorbed by last layer | False |
> Notes: layer-wise is stay-tuned. |
# Quantization code
from neural_compressor.torch.quantization import prepare, convert, TEQConfig
quant_config = TEQConfig()
model = prepare(model, quant_config, example_inputs=example_inputs)
train_fn(model) # calibration
model = convert(model)
HQQ
| hqq_args | comments | default value |
|---|---|---|
| quant_zero (bool) | Whether to quantize zero point | True |
| quant_scale: (bool) | Whether to quantize scale: point | False |
| scale_quant_group_size (int) | The group size for quantizing scale | 128 |
# Quantization code
from neural_compressor.torch.quantization import prepare, convert, HQQConfig
quant_config = HQQConfig()
model = prepare(model, quant_config)
run_fn(model) # calibration
model = convert(model)
Specify Quantization Rules
Intel(R) Neural Compressor support specify quantization rules by operator name or operator type. Users can set local in dict or use set_local method of config class to achieve the above purpose.
Example of setting
localfrom a dict
quant_config = {
"rtn": {
"global": {
"dtype": "int",
"bits": 4,
"group_size": -1,
"use_sym": True,
},
"local": {
"lm_head": {
"dtype": "fp32",
},
},
}
}
Example of using
set_local
quant_config = RTNConfig()
lm_head_config = RTNConfig(dtype="fp32")
quant_config.set_local("lm_head", lm_head_config)
Example of using
layer_configfor AutoRound
# layer_config = {
# "layer1": {
# "data_type": "int",
# "bits": 3,
# "group_size": 128,
# "sym": True,
# },
# "layer2": {
# "W8A16"
# }
# }
# Use the AutoRound specific 'layer_config' instead of the 'set_local' API.
layer_config = {"lm_head": {"data_type": "int"}}
quant_config = AutoRoundConfig(layer_config=layer_config)
Saving and Loading
The saved_results folder contains two files: quantized_model.pt and qconfig.json, and the generated model is a quantized model. The quantitative model will include WeightOnlyLinear. To support low memory inference, Intel(R) Neural Compressor implemented WeightOnlyLinear, a torch.nn.Module, to compress the fake quantized fp32 model. Since torch does not provide flexible data type storage, WeightOnlyLinear combines low bits data into a long date type, such as torch.int8 and torch.int32. Low bits data includes weights and zero points. When using WeightOnlyLinear for inference, it will restore the compressed data to float32 and run torch linear function.
# Quantization code
from neural_compressor.torch.quantization import prepare, convert, RTNConfig
quant_config = RTNConfig()
model = prepare(model, quant_config)
model = convert(model)
# save
model.save("saved_results")
# load
from neural_compressor.torch.quantization import load
orig_model = YOURMODEL()
loaded_model = load(
"saved_results", original_model=orig_model
) # Please note that the original_model parameter passes the original model.
Layer Wise Quantization
As the size of LLMs continues to grow, loading the entire model into a single GPU card or the RAM of a client machine becomes impractical. To address this challenge, we introduce Layer-wise Quantization (LWQ), a method that quantizes LLMs layer by layer or block by block. This approach significantly reduces memory consumption. The diagram below illustrates the LWQ process.
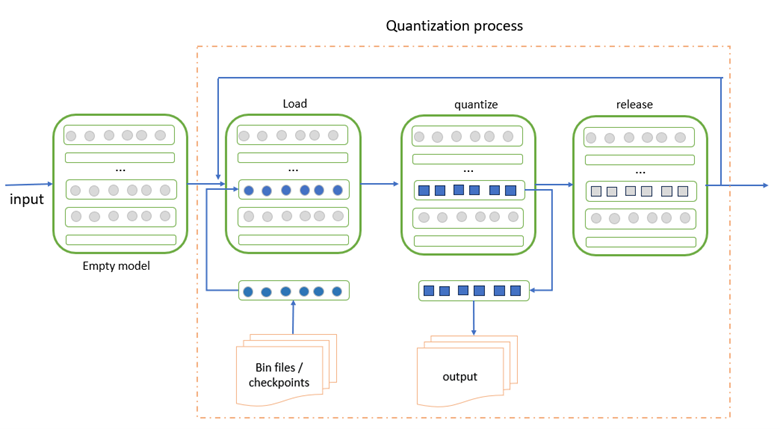
Figure 1: The process of layer-wise quantization for PyTorch model. The color grey means empty parameters and the color blue represents parameters need to be quantized. Every rectangle inside model represents one layer.
Currently, we support LWQ for RTN, AutoRound, and GPTQ.
Here, we take the RTN algorithm as example to demonstrate the usage of LWQ.
from neural_compressor.torch.quantization import RTNConfig, convert, prepare
from neural_compressor.torch import load_empty_model
model_state_dict_path = "/path/to/model/state/dict"
float_model = load_empty_model(model_state_dict_path)
quant_config = RTNConfig(use_layer_wise=True)
prepared_model = prepare(float_model, quant_config)
quantized_model = convert(prepared_model)
Efficient Usage on Client-Side
For client machines with limited RAM and cores, we offer optimizations to reduce computational overhead and minimize memory usage. For detailed information, please refer to Quantization on Client.
Examples
Users can also refer to examples on how to quantize a model with WeightOnlyQuant.
Reference
[1]. Xiao, Guangxuan, et al. “Smoothquant: Accurate and efficient post-training quantization for large language models.” arXiv preprint arXiv:2211.10438 (2022).
[2]. Wei, Xiuying, et al. “Outlier suppression: Pushing the limit of low-bit transformer language models.” arXiv preprint arXiv:2209.13325 (2022).
[3]. Lin, Ji, et al. “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration.” arXiv preprint arXiv:2306.00978 (2023).
[4]. Frantar, Elias, et al. “Gptq: Accurate post-training quantization for generative pre-trained transformers.” arXiv preprint arXiv:2210.17323 (2022).
[5]. Cheng, Wenhua, et al. “Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs” arXiv preprint arXiv:2309.05516 (2023).
[6]. Badri, Hicham and Shaji, Appu. “Half-Quadratic Quantization of Large Machine Learning Models.” [Online] Available: https://mobiusml.github.io/hqq_blog/ (2023).
[7]. Dettmers, Tim, et al. “Qlora: Efficient finetuning of quantized llms.” arXiv preprint arXiv:2305.14314 (2023).