Quantization¶
Quantization Introduction¶
Quantization is a very popular deep learning model optimization technique invented for improving the speed of inference. It minimizes the number of bits required by converting a set of real-valued numbers into the lower bit data representation, such as int8 and int4, mainly on inference phase with minimal to no loss in accuracy. This way reduces the memory requirement, cache miss rate, and computational cost of using neural networks and finally achieve the goal of higher inference performance. On Intel 3rd generation Xeon Scalable processor, user could expect up to 4x theoretical performance speedup. On Nvidia GPU, it could also bring significant inference performance speedup.
Quantization Fundamentals¶
Affine quantization and Scale quantization are two common range mapping techniques used in tensor conversion between different data types.
The math equation is like: $X_{int8} = round(Scale \times X_{fp32} + ZeroPoint)$.
Affine Quantization
This is so-called asymmetric quantization, in which we map the min/max range in the float tensor to the integer range. Here int8 range is [-128, 127], uint8 range is [0, 255].
here:
If INT8 is specified, $Scale = (|X_{f_{max}} - X_{f_{min}}|) / 127$ and $ZeroPoint = -128 - X_{f_{min}} / Scale$.
or
If UINT8 is specified, $Scale = (|X_{f_{max}} - X_{f_{min}}|) / 255$ and $ZeroPoint = - X_{f_{min}} / Scale$.
Scale Quantization
This is so-called Symmetric quantization, in which we use the maximum absolute value in the float tensor as float range and map to the corresponding integer range.
The math equation is like:
here:
If INT8 is specified, $Scale = max(abs(X_{f_{max}}), abs(X_{f_{min}})) / 127$ and $ZeroPoint = 0$.
or
If UINT8 is specified, $Scale = max(abs(X_{f_{max}}), abs(X_{f_{min}})) / 255$ and $ZeroPoint = 128$.
NOTE
Sometimes the reduce_range feature, that’s using 7 bit width (1 sign bit + 6 data bits) to represent int8 range, may be needed on some early Xeon platforms, it’s because those platforms may have overflow issues due to fp16 intermediate calculation result when executing int8 dot product operation. After AVX512_VNNI instruction is introduced, this issue gets solved by supporting fp32 intermediate data.
Quantization Support Matrix¶
| Framework | Backend Library | Symmetric Quantization | Asymmetric Quantization |
|---|---|---|---|
| TensorFlow | oneDNN | Activation (int8/uint8), Weight (int8) | - |
| PyTorch | FBGEMM | Activation (uint8), Weight (int8) | Activation (uint8) |
| IPEX | oneDNN | Activation (int8/uint8), Weight (int8) | - |
| MXNet | oneDNN | Activation (int8/uint8), Weight (int8) | - |
| ONNX Runtime | MLAS | Weight (int8) | Activation (uint8) |
Quantization Scheme in TensorFlow¶
Symmetric Quantization
int8: scale = 2 * max(abs(rmin), abs(rmax)) / (max(int8) - min(int8) - 1)
uint8: scale = max(rmin, rmax) / (max(uint8) - min(uint8))
Quantization Scheme in PyTorch¶
Symmetric Quantization
int8: scale = max(abs(rmin), abs(rmax)) / (float(max(int8) - min(int8)) / 2)
uint8: scale = max(abs(rmin), abs(rmax)) / (float(max(int8) - min(int8)) / 2)
Asymmetric Quantization
uint8: scale = (rmax - rmin) / (max(uint8) - min(uint8)); zero_point = min(uint8) - round(rmin / scale)
Quantization Scheme in IPEX¶
Symmetric Quantization
int8: scale = 2 * max(abs(rmin), abs(rmax)) / (max(int8) - min(int8) - 1)
uint8: scale = max(rmin, rmax) / (max(uint8) - min(uint8))
Quantization Scheme in MXNet¶
Symmetric Quantization
int8: scale = 2 * max(abs(rmin), abs(rmax)) / (max(int8) - min(int8) - 1)
uint8: scale = max(rmin, rmax) / (max(uint8) - min(uint8))
Quantization Scheme in ONNX Runtime¶
Symmetric Quantization
int8: scale = 2 * max(abs(rmin), abs(rmax)) / (max(int8) - min(int8) - 1)
Asymmetric Quantization
uint8: scale = (rmax - rmin) / (max(uint8) - min(uint8)); zero_point = min(uint8) - round(rmin / scale)
Reference¶
Quantization Approaches¶
Quantization has three different approaches: 1) post training dynamic quantization 2) post training static quantization 3) quantization aware training. The first two approaches belong to optimization on inference. The last belongs to optimization during training.
Post Training Dynamic Quantization¶
The weights of the neural network get quantized into int8 format from float32 format offline. The activations of the neural network is quantized as well with the min/max range collected during inference runtime.
This approach is widely used in dynamic length neural networks, like NLP model.
Post Training Static Quantization¶
Compared with post training dynamic quantization, the min/max range in weights and activations are collected offline on a so-called calibration dataset. This dataset should be able to represent the data distribution of those unseen inference dataset. The calibration process runs on the original fp32 model and dumps out all the tensor distributions for Scale and ZeroPoint calculations. Usually preparing 100 samples are enough for calibration.
This approach is major quantization approach people should try because it could provide the better performance comparing with post training dynamic quantization.
Quantization Aware Training¶
Quantization aware training emulates inference-time quantization in the forward pass of the training process by inserting fake quant ops before those quantizable ops. With quantization aware training, all weights and activations are fake quantized during both the forward and backward passes of training: that is, float values are rounded to mimic int8 values, but all computations are still done with floating point numbers. Thus, all the weight adjustments during training are made while aware of the fact that the model will ultimately be quantized; after quantizing, therefore, this method will usually yield higher accuracy than either dynamic quantization or post-training static quantization.
Accuracy Aware Tuning¶
Accuracy aware tuning is one of unique features provided by Intel(R) Neural Compressor, compared with other 3rd party model compression tools. This feature can be used to solve accuracy loss pain points brought by applying low precision quantization and other lossy optimization methods.
This tuning algorithm creates a tuning space by querying framework quantization capability and model structure, selects the ops to be quantized by the tuning strategy, generates quantized graph, and evaluates the accuracy of this quantized graph. The optimal model will be yielded if the pre-defined accuracy goal is met.
Working Flow¶
Currently accuracy aware tuning supports post training quantization, quantization aware training, and pruning. Other during-training optimization tunings are under development.
User could refer to below chart to understand the whole tuning flow.
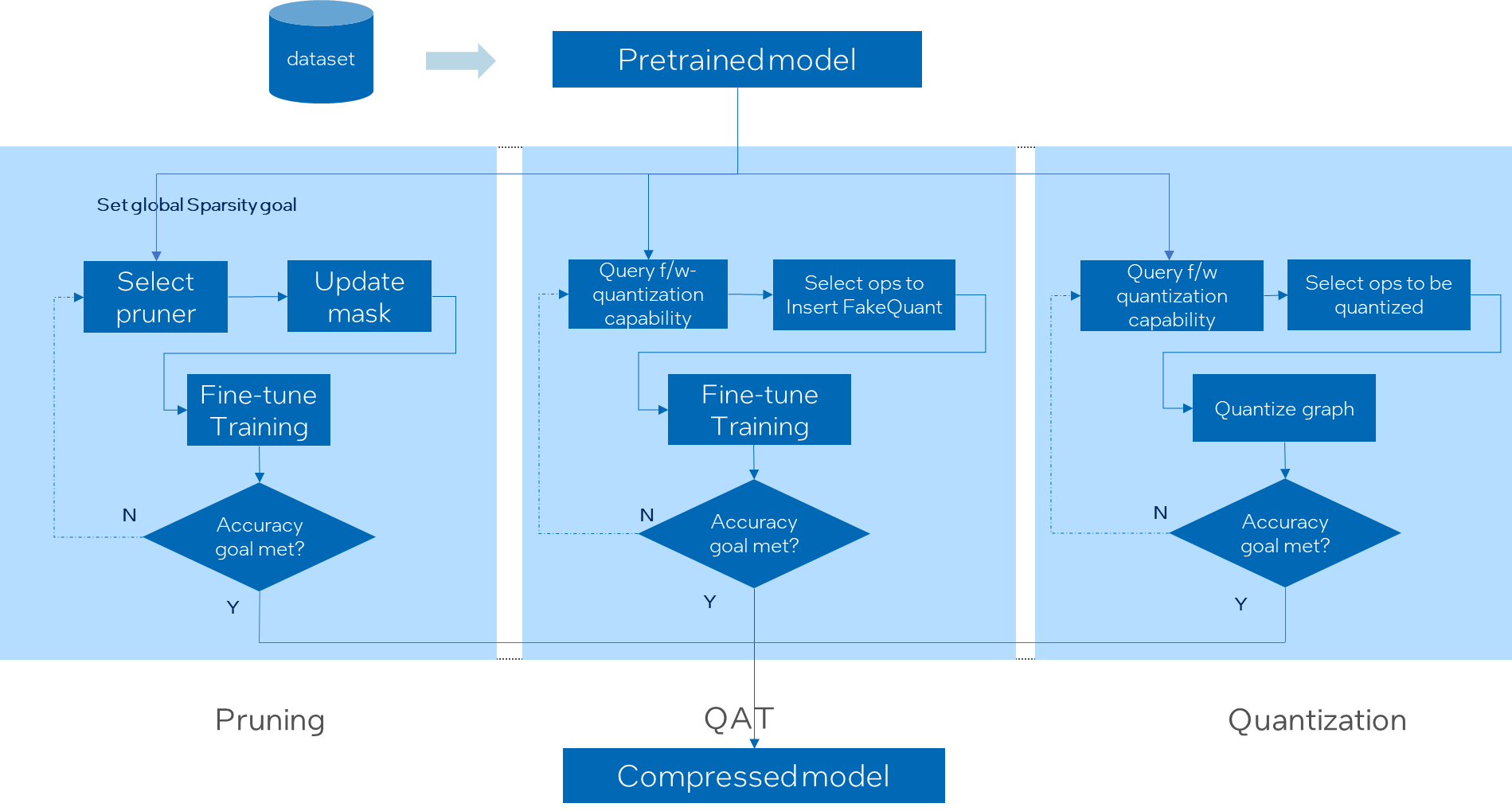
Supported Feature Matrix¶
Quantization methods include the following three types:
| Types | Quantization | Dataset Requirements | Framework | Backend |
|---|---|---|---|---|
| Post-Training Static Quantization (PTQ) | weights and activations | calibration | PyTorch | PyTorch Eager/PyTorch FX/IPEX |
| TensorFlow | TensorFlow/Intel TensorFlow | |||
| ONNX Runtime | QLinearops/QDQ | |||
| Post-Training Dynamic Quantization | weights | none | PyTorch | PyTorch eager mode/PyTorch fx mode/IPEX |
| ONNX Runtime | QIntegerops | |||
| Quantization-aware Training (QAT) | weights and activations | fine-tuning | PyTorch | PyTorch eager mode/PyTorch fx mode/IPEX |
| TensorFlow | TensorFlow/Intel TensorFlow |
Get Started¶
The design philosophy of the quantization interface of Intel(R) Neural Compressor is easy-of-use. It requests user to provide model, calibration dataloader, and evaluation function. Those parameters would be used to quantize and tune the model.
model is the framework model location or the framework model object.
calibration dataloader is used to load the data samples for calibration phase. In most cases, it could be the partial samples of the evaluation dataset.
evaluation function is a function used to evaluate model accuracy. This function should be same with how user makes evaluation on fp32 model, just taking model as input and returning a scalar value represented the evaluation accuracy.
User could execute:
Quantization without tuning
This means user could leverage Intel(R) Neural Compressor to directly generate a fully quantized model without accuracy aware tuning. It’s user responsibility to ensure the accuracy of the quantized model meets expectation.
# main.py
# Original code
model = ResNet50()
val_dataset = ...
val_dataloader = torch.utils.data.Dataloader(
val_dataset,
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, ping_memory=True)
# Quantization code
from neural_compressor import quantization
from neural_compressor.config import PostTrainingQuantConfig
conf = PostTrainingQuantConfig()
q_model = quantization.fit(model=model,
conf=conf,
calib_dataloader=val_dataloader)
q_model.save('./output')
Quantization with accuracy aware tuning
This means user could leverage the advance feature of Intel(R) Neural Compressor to tune out a best quantized model which has best accuracy and good performance.
# main.py
# Original code
model = ResNet50()
val_dataset = ...
val_dataloader = torch.utils.data.Dataloader(
val_dataset,
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, ping_memory=True)
criterion = ...
def validate(val_loader, model, criterion, args):
...
return top1.avg
# Quantization code
def train_func(model):
...
from neural_compressor import QuantizationAwareTrainingConfig
from neural_compressor.training import prepare_compression
conf = QuantizationAwareTrainingConfig()
compression_manager = prepare_compression(model, conf)
compression_manager.callbacks.on_train_begin()
model = compression_manager.model
train_func(model)
compression_manager.callbacks.on_train_end()
compression_manager.save('./output')
Examples¶
User could refer to examples on how to quantize a new model.