Pruning¶
-
1.2. Pruning Patterns
1.3. Pruning Criteria
1.4. Pruning Schedule
Introduction¶
Neural Network Pruning¶
Neural network pruning (briefly known as pruning or sparsity) is one of the most promising model compression techniques. It removes the least important parameters in the network and achieves compact architectures with minimal accuracy drop and maximal inference acceleration. As current state-of-the-art models have increasingly more parameters, pruning plays a crucial role in enabling them to run on devices whose memory footprints and computing resources are limited.
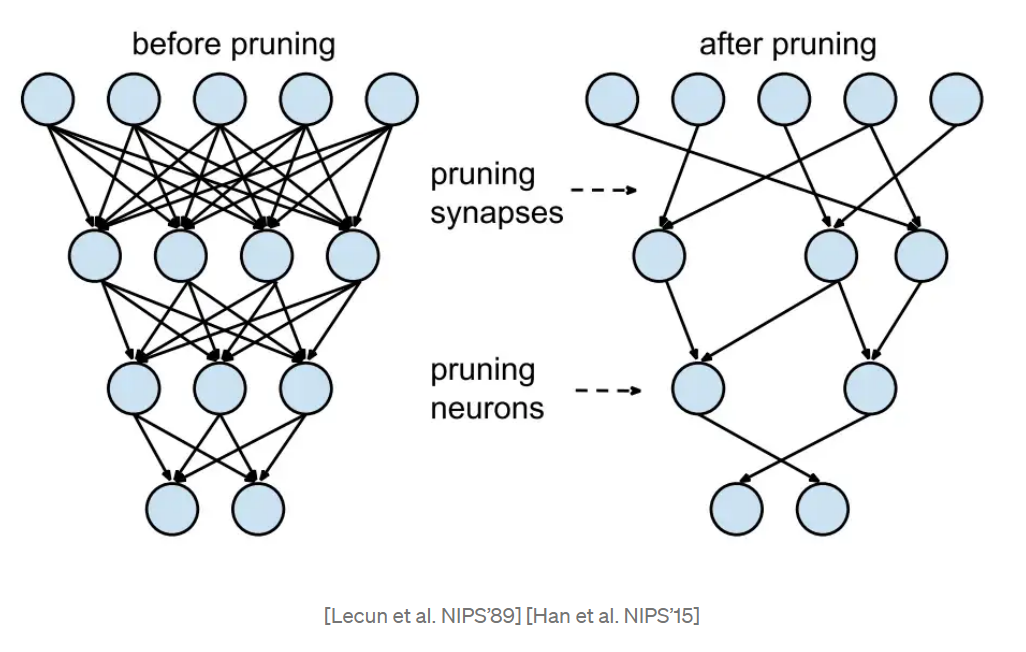
Pruning Patterns¶
Pruning patterns defines the rules of pruned weights’ arrangements in space.

Unstructured Pruning
Unstructured pruning means finding and removing the less salient connection in the model where the nonzero patterns are irregular and could be anywhere in the matrix.
2in4 Pruning
NVIDIA proposed 2:4 sparsity (or known as “2in4 sparsity”) in Ampere architecture, for every 4 continuous elements in a matrix, two of them are zero and others are non-zero.
Structured Pruning
Structured pruning means finding parameters in groups, deleting entire blocks, filters, or channels according to some pruning criterions. In general, structured pruning leads to lower accuracy due to restrictive structure than unstructured pruning; However, it can accelerate the model execution significantly because it can fit hardware design better.
Different from 2:4 sparsity above, we propose the block-wise structured sparsity patterns that we are able to demonstrate the performance benefits on existing Intel hardwares even without the support of hardware sparsity. A block-wise sparsity pattern with block size
Smeans the contiguousSelements in this block are all zero values.For a typical GEMM, the weight dimension is
ICxOC, whereICis the number of input channels andOCis the number of output channels. Note that sometimesICis also called dimensionK, andOCis called dimensionN. The sparsity dimension is onOC(orN).For a typical Convolution, the weight dimension is
OC x IC x KH x KW, whereOCis the number of output channels,ICis the number of input channels, andKHandKWis the kernel height and weight. The sparsity dimension is also onOC.Here is a figure showing a matrix with
IC= 32 andOC= 16 dimension, and a block-wise sparsity pattern with block size 4 onOCdimension.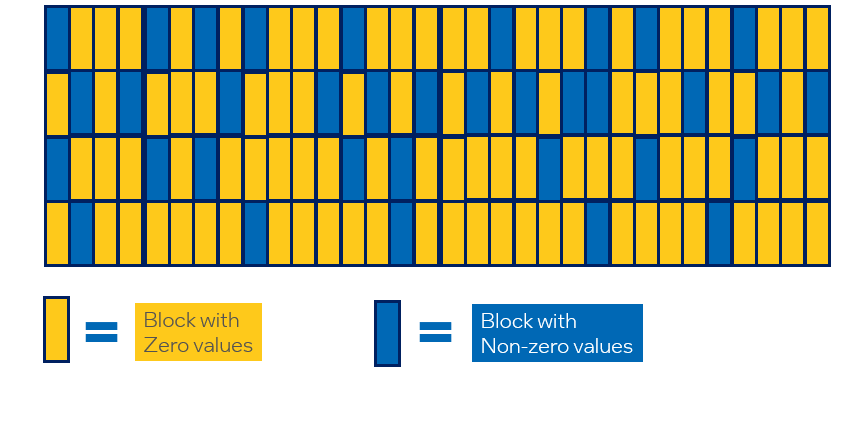
Pruning Criteria¶
Pruning criteria defines the rules of which weights are least important to be pruned, in order to maintain the model’s original accuracy. Most popular criteria examine weights’ absolute value and their corresponding gradients.
Magnitude
The algorithm prunes the weight by the lowest absolute value at each layer with given sparsity target.
Gradient sensitivity
The algorithm prunes the head, intermediate layers, and hidden states in NLP model according to importance score calculated by following the paper FastFormers.
Group Lasso
The algorithm uses Group lasso regularization to prune entire rows, columns or blocks of parameters that result in a smaller dense network.
Pattern Lock
The algorithm locks the sparsity pattern in finetuning phase by freezing those zero values of weight tensor during weight update of training. It can be applied in the following scenario: after the model is pruned under a large dataset, pattern lock can be used to retrain the sparse model on a downstream task (a smaller dataset). Please refer to Prune once for all for more information.
SNIP
The algorithm prunes the dense model at its initialization, by analyzing the weights’ effect to the loss function when they are masked. Please refer to the original paper for details
SNIP with momentum
The algorithm improves original SNIP algorithms and introduces weights’ score maps which updates in a momentum way.
In the following formula, $n$ is the pruning step and $W$ and $G$ are model’s weights and gradients respectively. $$Score_{n} = 1.0 \times Score_{n-1} + 0.9 \times |W_{n} \times G_{n}|$$
Pruning Schedule¶
Pruning schedule defines the way the model reach the target sparsity (the ratio of pruned weights).
One-shot Pruning
One-shot pruning means the model is pruned to its target sparsity with one single step. This pruning method often works at model’s initialization step. It can easily cause accuracy drop, but save much training time.
Iterative Pruning
Iterative pruning means the model is gradually pruned to its target sparsity during a training process. The pruning process contains several pruning steps, and each step raises model’s sparsity to a higher value. In the final pruning step, the model reaches target sparsity and the pruning process ends.
Pruning Support Matrix¶
| Pruning Type | Pruning Granularity | Pruning Algorithm | Framework |
|---|---|---|---|
| Unstructured Pruning | Element-wise | Magnitude | PyTorch, TensorFlow |
| Pattern Lock | PyTorch | ||
| SNIP with momentum | PyTorch | ||
| Structured Pruning | Filter/Channel-wise | Gradient Sensitivity | PyTorch |
| SNIP with momentum | PyTorch | ||
| Block-wise | Group Lasso | PyTorch | |
| SNIP with momentum | PyTorch | ||
| Element-wise | Pattern Lock | PyTorch | |
| SNIP with momentum | PyTorch |
Get Started with Pruning API¶
Neural Compressor Pruning API is defined under neural_compressor.training, which takes a user defined yaml file as input. Below is the launcher code of applying the API to execute a pruning process.
Users can pass the customized training/evaluation functions to Pruning for flexible scenarios. In this case, pruning process can be done by pre-defined hooks in Neural Compressor. Users need to put those hooks inside the training function.
The following section exemplifies how to use hooks in user pass-in training function to perform model pruning. Through the pruning API, multiple pruner objects are supported in one single Pruning object to enable layer-specific configurations and a default setting is used as a complement.
Step 1: Define a dict-like configuration in your training codes. We provide you a template of configuration below.
configs = [ { ## pruner1 'target_sparsity': 0.9, # Target sparsity ratio of modules. 'pruning_type': "snip_momentum", # Default pruning type. 'pattern': "4x1", # Default pruning pattern. 'op_names': ['layer1.*'], # A list of modules that would be pruned. 'excluded_op_names': ['layer3.*'], # A list of modules that would not be pruned. 'start_step': 0, # Step at which to begin pruning. 'end_step': 10, # Step at which to end pruning. 'pruning_scope': "global", # Default pruning scope. 'pruning_frequency': 1, # Frequency of applying pruning. 'min_sparsity_ratio_per_op': 0.0, # Minimum sparsity ratio of each module. 'max_sparsity_ratio_per_op': 0.98, # Maximum sparsity ratio of each module. 'sparsity_decay_type': "exp", # Function applied to control pruning rate. 'pruning_op_types': ['Conv', 'Linear'], # Types of op that would be pruned. }, { ## pruner2 "op_names": ['layer3.*'], # A list of modules that would be pruned. "pruning_type": "snip_momentum_progressive", # Pruning type for the listed ops. # 'target_sparsity' } # For layer3, the missing target_sparsity would be complemented by default setting (i.e. 0.8) ]
Step 2: Insert API functions in your codes. Only 5 lines of codes are required.
""" All you need is to insert following API functions to your codes: on_train_begin() # Setup pruner on_step_begin() # Prune weights on_before_optimizer_step() # Do weight regularization on_after_optimizer_step() # Update weights' criteria, mask weights on_train_end() # end of pruner, Print sparse information """ from neural_compressor.training import prepare_compression, WeightPruningConfig ##setting configs pruning_configs=[ {"op_names": ['layer1.*'],"pattern":'4x1'}, {"op_names": ['layer2.*'],"pattern":'1x1', 'target_sparsity':0.5} ] config = WeightPruningConfig(pruning_configs, target_sparsity=0.8, excluded_op_names=['classifier']) ##default setting config = WeightPruningConfig(configs) compression_manager = prepare_compression(model, config) compression_manager.callbacks.on_train_begin() ## insert hook for epoch in range(num_train_epochs): model.train() for step, batch in enumerate(train_dataloader): compression_manager.callbacks.on_step_begin(step) ## insert hook outputs = model(**batch) loss = outputs.loss loss.backward() compression_manager.callbacks.on_before_optimizer_step() ## insert hook optimizer.step() compression_manager.callbacks.on_after_optimizer_step() ## insert hook lr_scheduler.step() model.zero_grad() ... compression_manager.callbacks.on_train_end() ...
In the case mentioned above, pruning process can be done by pre-defined hooks in Neural Compressor. Users need to place those hooks inside the training function. The pre-defined Neural Compressor hooks are listed below.
on_train_begin() : Execute at the beginning of training phase.
on_epoch_begin(epoch) : Execute at the beginning of each epoch.
on_step_begin(batch) : Execute at the beginning of each batch.
on_step_end() : Execute at the end of each batch.
on_epoch_end() : Execute at the end of each epoch.
on_before_optimizer_step() : Execute before optimization step.
on_after_optimizer_step() : Execute after optimization step.
on_train_end() : Execute at the ending of training phase.
Examples¶
We validate the sparsity on typical models across different domains (including CV, NLP, and Recommendation System). Validated pruning examples shows the sparsity pattern, sparsity ratio, and accuracy of sparse and dense (Reference) model for each model.
Please refer to pruning examples(TensorFlow, PyTorch) for more information.