Weight-Only Quantization (Prototype)
Introduction
Large Language Models (LLMs) have shown remarkable performance in various natural language processing tasks.
However, deploying them on devices with limited resources is challenging due to their high computational and memory requirements.
To overcome this issue, we propose quantization methods that reduce the size and complexity of LLMs. Unlike normal quantization, such as w8a8, that quantizes both weights and activations, we focus on Weight-Only Quantization (WOQ), which only quantizes the weights statically. WOQ is a better trade-off between efficiency and accuracy, as the main bottleneck of deploying LLMs is the memory bandwidth and WOQ usually preserves more accuracy. Experiments on Qwen-7B, a large-scale LLM, show that we can obtain accurate quantized models with minimal loss of quality.
Supported Framework Model Matrix
| Support Device | RTN* | AWQ* | TEQ* | GPTQ* | AutoRound* | Data type of quantized weight |
|---|---|---|---|---|---|---|
| GPU | ✔ | ✔ | stay tuned* | ✔ | stay tuned* | int4_fullrange |
| Model | Datatype | Device | Algorithm |
|---|---|---|---|
| Llama3-8B | INT4 | Intel® iGPU and dGPU | RTN, GPTQ |
| Phi3-mini | INT4 | Intel® iGPU and dGPU | RTN, GPTQ |
| GPT-J-6B | INT4 | Intel® iGPU and dGPU | RTN, GPTQ |
| Qwen2-7B | INT4 | Intel® iGPU and dGPU | RTN, GPTQ |
| GLM-4-9b-chat | INT4 | Intel® iGPU and dGPU | RTN, GPTQ |
Validation Platforms
Intel® Data Center GPU Max Series
Intel® Arc™ A-Series Graphics
Intel® Arc™ B-Series Graphics
Intel® Core™ Ultra series
Note: For algorithms marked as ‘stay tuned’ are highly recommended to wait for the availability of the INT4 models on the HuggingFace Model Hub, since the LLM quantization procedure is significantly constrained by the machine’s host memory and computation capabilities.
RTN[1]: Rounding to Nearest (RTN) is an intuitively simple method that rounds values to the nearest integer. It boasts simplicity, requiring no additional datasets, and offers fast quantization. Besides, it could be easily applied in other datatype like NF4 (non-uniform). Typically, it performs well on configurations such as W4G32 or W8, but worse than advanced algorithms at lower precision level.
AWQ[2]: AWQ is a popular method that explores weight min-max values and equivalent transformations in a handcrafted space. While effective, the equivalent transformation imposes certain requirements on model architecture, limiting its applicability to broader models or increasing engineering efforts.
TEQ[3]: To our knowledge, it is the first trainable equivalent ransformation method (summited for peer review in 202306). However, it requires more memory than other methods as model-wise loss is used and the equivalent transformation imposes certain requirements on model architecture.
GPTQ[4]: GPTQ is a widely adopted method based on the Optimal Brain Surgeon. It quantizes weight block by block and fine-tunes the remaining unquantized ones to mitigate quantization errors. Occasionally, non-positive semidefinite matrices may occur, necessitating adjustments to hyperparameters.
AutoRound[5]: AutoRound utilizes sign gradient descent to optimize rounding values and minmax values of weights within just 200 steps, showcasing impressive performance compared to recent methods like GPTQ/AWQ. Additionally, it offers hypeparameters tuning compatibility to further enhance performance. However, due to its reliance on gradient backpropagation, currently it is not quite fit for backends like ONNX.
References
[1] Gunho Park, Baeseong Park, Se Jung Kwon, Byeongwook Kim, Youngjoo Lee, and Dongsoo Lee. nuqmm: Quantized matmul for efficient inference of large-scale generative language models. arXiv preprint arXiv:2206.09557, 2022.
[2] Lin, Ji, et al.(2023). AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. arXiv preprint arXiv:2306.00978.
[3] Cheng, W., Cai, Y., Lv, K & Shen, H. (2023). TEQ: Trainable Equivalent Transformation for Quantization of LLMs. arXiv preprint arXiv:2310.10944.
[4] Frantar, Elias, et al. “Gptq: Accurate post-training quantization for generative pre-trained transformers.” arXiv preprint arXiv:2210.17323 (2022).
[5] Cheng, W., Zhang, W., Shen, H., Cai, Y., He, X., & Lv, K. (2023). Optimize weight rounding via signed gradient descent for the quantization of llms. arXiv preprint arXiv:2309.05516.
Weight-Only Quantization LLM features in Intel® Extension for PyTorch*
In this section, we will describe the implementation of Weight-Only Quantization LLM features in Intel® Extension for PyTorch*. These operators are highly optimized on Intel® GPU platform.
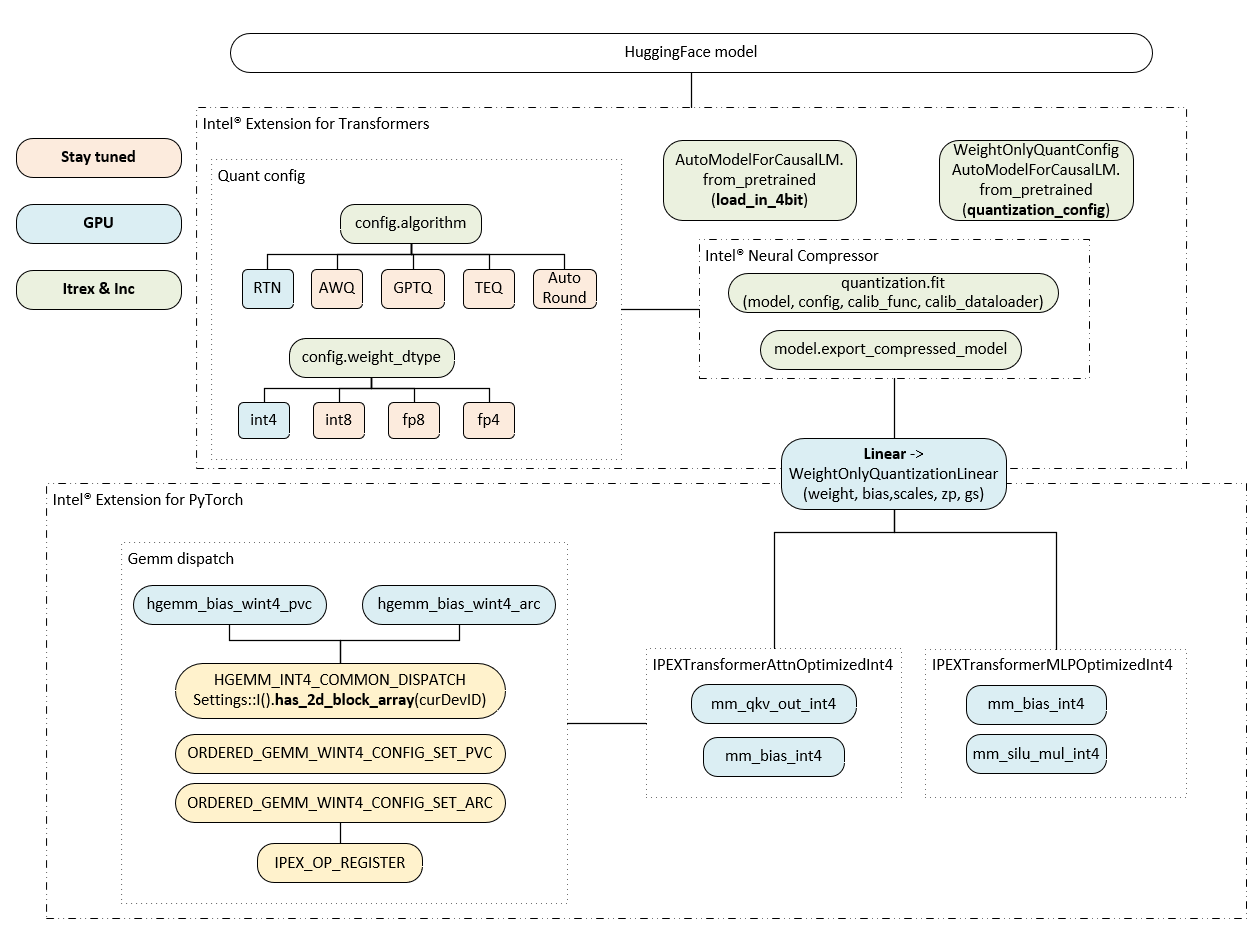
Weight-Only Quantization Initialization
On Intel® GPU, the easiest way to load INT4 models is to use the load_in_4bit interface provided by Intel® Neural Compressor*, which hooks the AutoModelForCausalLM.from_pretrained function to use load_in_4bit on Intel® GPU. Pass the argument load_in_4bit=True to load a model in 4bit when calling the from_pretrained method, which can read the model weight in INT4 format directly.
qmodel = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True, device_map="xpu", trust_remote_code=True, use_llm_runtime=False)
Another option that Intel® Neural Compressor* offers is to extend the AutoModelForCausalLM.from_pretrained function to allow quantization_config to take WeightOnlyQuantConfig as an argument, which enables conversion on the Intel® GPU platform. We currently support the RTN algorithm and the weight_dtype setting of int4_fullrange (which means that all linear weights are converted to INT4).
woq_quantization_config = WeightOnlyQuantConfig(compute_dtype="fp16", weight_dtype="int4_fullrange", scale_dtype="fp16", group_size=64)
qmodel = AutoModelForCausalLM.from_pretrained(model_name, device_map="xpu", quantization_config=woq_quantization_config, trust_remote_code=True)
In Weight-Only Quantization INT4 case, when using AutoModelForCausalLM.from_pretrained from Intel® Neural Compressor* to load the model, it will use Intel® Neural Compressor according to the running device to perform quantization deployment.
inc_model = quantization.fit(model,
conf,
calib_func=calib_func,
calib_dataloader=calib_dataloader)
model = inc_model.export_compressed_model(compression_dtype=torch.int8,
compression_dim=0,
use_optimum_format=False,
scale_dtype=convert_dtype_str2torch("fp16"))
When running on Intel® GPU, it will replace the linear in the model with WeightOnlyQuantizedLinear. After that, the model linear weight loaded by ipex.llm.optimize is in INT4 format, and it contains not only weight and bias information, but also scales, zero_points, and blocksize information. When optimizing transformers at the front end, Intel® Extension for PyTorch* will use WeightOnlyQuantizedLinear to initialize this information in the model if they are present, otherwise, it will use IPEXTransformerLinear to initialize the linear parameters in the model.
Weight-Only Quantization Runtime
On Intel® GPU, after using ipex.llm.optimize, Intel® Extension for PyTorch* will automatically replace the original attention module with IPEXTransformerAttnOptimizedInt4 and the original MLP module with IPEXTransformerMLPOptimizedInt4 in the model.
The major changes between IPEXTransformerAttnOptimizedInt4 for INT4 scenario and ipex.llm.optimize for FP16 scenario include: replace the linear used to calculate qkv with torch.ops.torch_ipex.mm_qkv_out_int4 and out_linear with torch.ops.torch_ipex.mm_bias_int4.
The major changes between IPEXTransformerMLPOptimizedInt4 for INT4 scenario and ipex.llm.optimize for FP16 scenario include: replace the linear used in MLP with torch.ops.torch_ipex.mm_bias_int4, if activation is used in the MLP module, then correspondingly, it will be replaced with our fused linear+activation kernel, such as torch.ops.torch_ipex.mm_silu_mul_int4.
Weight-Only Quantization Linear Dispatch
As explained before, after applying ipex.llm.optimize, The linear kernel that Intel® Extension for PyTorch* has registered to substitute the original linear will be used in the model.
The method is:
Firstly, a new operator in Intel® Extension for PyTorch* will be registered through IPEX_OP_REGISTER("mm_bias_int4.xpu", at::AtenIpexTypeXPU::mm_bias_int4) and the operator name will be mm_bias_int4.
Then HGEMMXetla_INT4 will be used to register the corresponding policy for mm_bias_int4 beforehand. Later, we use policy.run() to make the configured policy take effect.
During execution, Intel® Extension for PyTorch* will determine the current running platform according to the machine configuration Settings::I().has_2d_block_array(curDevID) and look for a suitable policy for it. If it is Intel® Data Center GPU Max Series platform, it will use the policy implemented in ORDERED_GEMM_WINT4_CONFIG_SET_PVC. If it is Intel® Arc™ A-Series Graphics platform, it will use the policy implemented in ORDERED_GEMM_WINT4_CONFIG_SET_ARC.
After the policy is selected, Intel® Extension for PyTorch* will use HGEMM_INT4_COMMON_DISPATCH to dispatch the operator to different kernels based on different linear configuration parameters and platforms. For example, mm_bias_int4 on the Intel® Arc™ A-Series Graphics platform will be dispatched to the hgemm_bias_wint4_arc kernel.
Usage of running Weight-Only Quantization LLM For Intel® GPU
Intel® Extension for PyTorch* implements Weight-Only Quantization for Intel® Data Center GPU Max Series and Intel® Arc™ A-Series Graphics with Intel® Extension for Transformers*. Below section uses Qwen-7B to demonstrate the detailed usage.
Environment Setup
Please refer to the env setup.
Example can be found at Learn WOQ.
Run Weight-Only Quantization LLM on Intel® GPU
Quantize Model and Inference
import intel_extension_for_pytorch as ipex
from neural_compressor.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
device = "xpu"
model_name = "Qwen/Qwen-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
prompt = "Once upon a time, there existed a little girl,"
inputs = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
woq_quantization_config = WeightOnlyQuantConfig(compute_dtype="fp16", weight_dtype="int4_fullrange", scale_dtype="fp16", group_size=128)
qmodel = AutoModelForCausalLM.from_pretrained(model_name, device_map="xpu", quantization_config=woq_quantization_config, trust_remote_code=True)
# optimize the model with Intel® Extension for PyTorch*, it will improve performance.
qmodel = ipex.llm.optimize(qmodel, inplace=True, dtype=torch.float16, quantization_config=woq_quantization_config, device="xpu")
output = qmodel.generate(inputs)
Note: It is recommended quantizing and saving the model first, then loading the model as below on a GPU device without sufficient device memory. Otherwise you could skip below instruction, execute quantization and inference on your device directly.
Save and Load Quantized Model (Optional)
from neural_compressor.transformers import AutoModelForCausalLM
qmodel = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", load_in_4bit=True, device_map="xpu", trust_remote_code=True)
# Please note, saving model should be executed before ipex.llm.optimize function is called.
model.save_pretrained("saved_dir")
# Load model
loaded_model = AutoModelForCausalLM.from_pretrained("saved_dir", trust_remote_code=True)
# Before executed the loaded model, you can call ipex.llm.optimize function.
loaded_model = ipex.llm.optimize(loaded_model, inplace=True, dtype=torch.float16, woq=True, device="xpu")
output = loaded_model.generate(inputs)
Execute WOQ benchmark script
bash run_benchmark_woq.sh
Note:
Do save quantized model before call
ipex.llm.optimizefunction.The
ipex.llm.optimizefunction is designed to optimize transformer-based models within frontend python modules, with a particular focus on Large Language Models (LLMs). It provides optimizations for both model-wise and content-generation-wise. Please refer to Transformers Optimization Frontend API for the detail ofipex.llm.optimize.