Welcome to Intel® Extension for PyTorch* Documentation!
Retirement Plan
You may already be aware that we plan to retire Intel® Extension for PyTorch* soon. This was announced in the Intel® Extension for PyTorch* 2.8 release notes and also highlighted in community ticket #867.
We launched the Intel® Extension for PyTorch* in 2020 with the goal of extending the official PyTorch* to simplify achieving high performance on Intel® CPU and GPU platforms. Over the years, we have successfully upstreamed most of our features and optimizations for Intel® platforms into PyTorch* itself. As a result, we have discontinued active development of the Intel® Extension for PyTorch* and ceased official quarterly releases following the 2.8 release. We strongly recommend using PyTorch* directly going forward, as we remain committed to delivering robust support and performance with PyTorch* for Intel® CPU and GPU platforms.
We will continue to provide critical bug fixes and security patches for two additional quarters to ensure a smooth transition for our partners and the broader community. After that, we plan to mark the project End-of-Life unless there is a solid need to continue maintenance. Concretely, this means:
We will continue to provide critical bug fixes and security patches in the main branches of Intel® Extension for PyTorch*: CPU and GPU.
We have stopped official quarterly releases. We will not create release branches or publish official binary wheels for Intel® Extension for PyTorch*.
We will maintain Intel® Extension for PyTorch* as an open source project until the end of March 2026, to allow projects which depend on Intel® Extension for PyTorch* to completely remove the dependency.
Thank you all for your continued support! Let’s keep the momentum going together!
Introduction
Intel® Extension for PyTorch* extends PyTorch* with the latest performance optimizations for Intel hardware.
Optimizations take advantage of Intel® Advanced Vector Extensions 512 (Intel® AVX-512) Vector Neural Network Instructions (VNNI) and Intel® Advanced Matrix Extensions (Intel® AMX) on Intel CPUs as well as Intel XeMatrix Extensions (XMX) AI engines on Intel discrete GPUs.
Moreover, Intel® Extension for PyTorch* provides easy GPU acceleration for Intel discrete GPUs through the PyTorch* xpu device.
The extension can be loaded as a Python module for Python programs or linked as a C++ library for C++ programs. In Python scripts, users can enable it dynamically by importing intel_extension_for_pytorch.
Note
GPU features are not included in CPU-only packages.
Optimizations for CPU-only may have a newer code base due to different development schedules.
In the current technological landscape, Generative AI (GenAI) workloads and models have gained widespread attention and popularity. Large Language Models (LLMs) have emerged as the dominant models driving these GenAI applications. Starting from 2.1.0, specific optimizations for certain LLM models are introduced in the Intel® Extension for PyTorch*.
Intel® Extension for PyTorch* has been released as an open–source project at Github. You can find the source code and instructions on how to get started at:
CPU: CPU main branch | Get Started
XPU: XPU main branch | Get Started
Architecture
Intel® Extension for PyTorch* is structured as shown in the following figure:
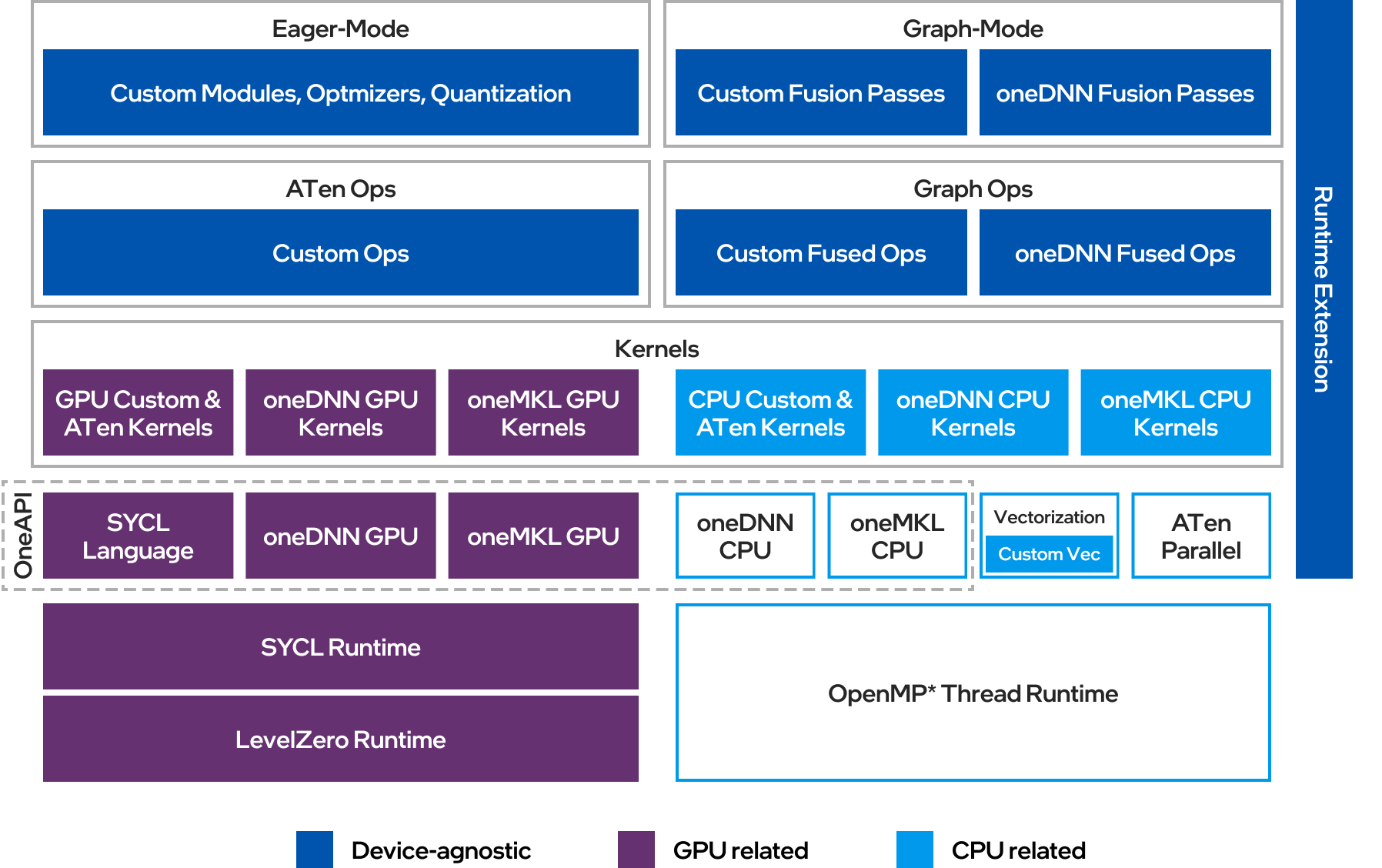
Eager Mode: In the eager mode, the PyTorch frontend is extended with custom Python modules (such as fusion modules), optimal optimizers, and INT8 quantization APIs. Further performance improvement is achieved by converting eager-mode models into graph mode using extended graph fusion passes.
Graph Mode: In the graph mode, fusions reduce operator/kernel invocation overhead, resulting in improved performance. Compared to the eager mode, the graph mode in PyTorch* normally yields better performance from the optimization techniques like operation fusion. Intel® Entension for PyTorch* amplifies them with more comprehensive graph optimizations. Both PyTorch
TorchscriptandTorchDynamograph modes are supported. WithTorchscript, we recommend usingtorch.jit.trace()as your preferred option, as it generally supports a wider range of workloads compared totorch.jit.script(). WithTorchDynamo, ipex backend is available to provide good performances.CPU Optimization: On CPU, Intel® Extension for PyTorch* automatically dispatches operators to underlying kernels based on detected ISA. The extension leverages vectorization and matrix acceleration units available on Intel hardware. The runtime extension offers finer-grained thread runtime control and weight sharing for increased efficiency.
GPU Optimization: On GPU, optimized operators and kernels are implemented and registered through PyTorch dispatching mechanism. These operators and kernels are accelerated from native vectorization feature and matrix calculation feature of Intel GPU hardware. Intel® Extension for PyTorch* for GPU utilizes the DPC++ compiler that supports the latest SYCL* standard and also a number of extensions to the SYCL* standard, which can be found in the sycl/doc/extensions directory.
Support
The team tracks bugs and enhancement requests using GitHub issues. Before submitting a suggestion or bug report, search the existing GitHub issues to see if your issue has already been reported.