Channels Last
What is Channels Last
Note: In PyTorch, memory format refers to data representation that describes how multidimensional arrays (nD) are stored in linear (1D) memory address space. Memory format has the same semantic meaning as layout in oneDNN. Layout in PyTorch has other semantic of describing dense or sparse with the attributes: ‘torch.strided’, ‘torch.sparse_coo’.
On CNN models, the canonical order of tensor dimensions is assigned with semantic meaning. For example the input tensor of 2D convolution is of NCHW by default on PyTorch - <batch_size, channels, height, width>. NHWC is an alternative way of describing the tensor dimensions - <batch_size, height, width, channels>.
Look at the following image of illustrating NCHW and NHWC when N=1. Actually when N=1, NHWC has the same format with BMP file image.
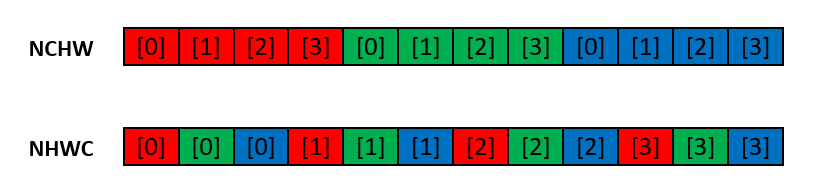
PyTorch refers to NCHW as torch.contiguous_format (the default memory format) and to NHWC as torch.channels_last, which is a new feature as of the 1.5 release.
TensorFlow uses NHWC as the default memory format because NHWC has a performance advantage over NCHW. On Intel® platforms, we propose to optimize Channels Last memory path for the following reasons:
Performance - NHWC performance is not as good as blocked memory format (nChw16c), but it is close, and much better performance than NCHW.
User Experience - Operator coverage of NHWC would be higher than blocked memory format, so user experience is better. To be specific, it is difficult to enable operators that manipulates
dimon blocked format such assum(dim=?). You would need to convert tensor from blocked memory format back to NHWC usingto_dense(), before feeding it intosum(). This is naturally supported on Channels Last memory format already.Upstream - Will be easier since CPU doesn’t hold secret ingredient and both inference and training will be covered.
Memory Format Is All That Matters
On CNN models, memory format is almost the foundation of any upper level design. One important fact is that converting memory format could be very expensive. Thus, in case that multiple CNN operators are performed in sequence, e.g. Conv2d -> ReLU -> Conv2d, it’s beneficial to transform them from different memory formats once, do computation and reorder them back.
On PyTorch, you can use 3 types of memory formats on CNN models:
a. NCHW (default)
device='cpu' # or 'xpu'
if device == 'xpu':
import intel_extension_for_pytorch
## NB: internally blocked format will still be used.
## aka. we do 'reorder' for 'input', 'weight' and 'output',
## and believe me this is expensive, roughly 50% perf loss...
input = torch.randn(1, 10, 32, 32).to(device)
model = torch.nn.Conv2d(10, 20, 1, 1).to(device)
output = model(input)
b. NHWC
device='cpu' # or 'xpu'
if device == 'xpu':
import intel_extension_for_pytorch
input = torch.randn(1, 10, 32, 32).to(device)
model = torch.nn.Conv2d(10, 20, 1, 1).to(device)
## NB: convert to Channels Last memory format.
## oneDNN supports NHWC for feature maps (input, output),
## but weight still needs to be of blocked format.
## Still we can save reorders for feature maps.
input = input.to(memory_format=torch.channels_last)
model = model.to(memory_format=torch.channels_last)
output = model(input)
c. Blocked (nChw16c, on CPU)
from torch.utils import mkldnn as mkldnn_utils
input = torch.randn(1, 10, 32, 32)
model = torch.nn.Conv2d(10, 20, 1, 1)
## NB: convert to blocked memory format.
## Note that 'output' is in blocked memory format,
## in case the subsequent operator doesn't support blocked memory format
## you need to manually reorder it back to NCHW by output.to_dense()
## mkldnn_utils.to_mkldnn(model) is used to prepack the weight, this will save weight reorder time
## for inference. For training, it is not needed.
input = input.to_mkldnn()
model = mkldnn_utils.to_mkldnn(model)
output = model(input)
Better to explain the concepts here with a diagram, the dotted lines indicate simple memory view, no hard copy.
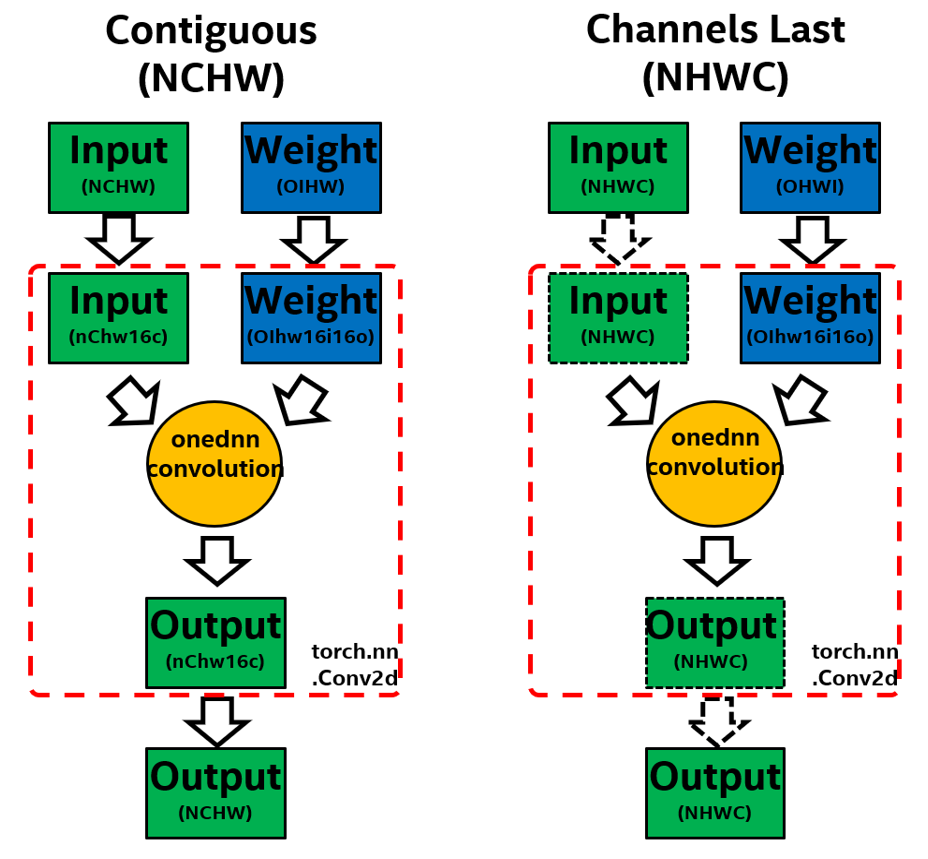
Conclusion is that NHWC path saves the reorders from feature maps compared with NCHW path, but still weight reorder is necessary since oneDNN requires weights to be in blocked memory format. From performance perspective, when batch_size=N, weight reorder is minimum compared to feature map reorder. But when batch_size=1, weight reorder is usually not negligible. So whether to enable weight prepacking on channels last memory format needs further discussion.
PyTorch Strided Layout
Before moving on, let’s explain how PyTorch organizes tensors in memory - the layout. Here we only focus on dense tensors, skipping ‘coo’ layout of sparse tensor.
The question itself can be reinterpreted as, for a tensor of size <N, C, H, W>, how does PyTorch access the element with index <n, c, h, w> from memory? The answer is stride:
tensor: <N, C, H, W>
index: <n, c, h, w>
strides: <CHW, HW, W, 1>
offset(n,c,h,w) = stride_n * n + stride_c * c + stride_h * h + stride_w * w
= CHW * n + HW * c + W * h + 1 * w
One merit of introducing stride is that it can express noncontiguous tensors, e.g. a slice of big tensor. For example, the ‘Xs’ in the following image have a stride of <n1+n2, 1>.
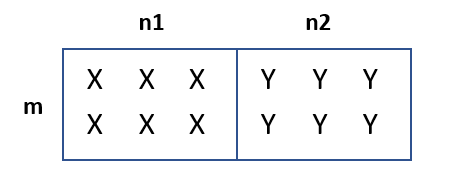
Keep in mind that PyTorch Tensor does not have an attribute called ‘memory_format’ or something else. The memory format expression completely relies on size and stride. The design principle can be found at reference: RFC: Memory format (aka layout aka NHWC) support. No matter what the tensor’s memory format is, we need a logical canonical order for the dimensions - that is NCHW on PyTorch. Thus, size and stride are ALWAYS described in the order of NCHW. Let’s now look at the Channels Last case of the previous question:
tensor: <N, C, H, W>
index: <n, c, h, w>
strides: <HWC, 1, WC, C>
offset(n,c,h,w) = stride_n * n + stride_c * c + stride_h * h + stride_w * w
= HWC * n + 1 * c + WC * h + C * w
Actually, this pattern applies to ALL other memory formats as long as it is 4-dim, e.g. strides for CHWN would be <1, HWN, WN, N>.
Channels Last Memory Format APIs
a. tensor creation
device='cpu' # or 'xpu'
if device == 'xpu':
import intel_extension_for_pytorch
x = torch.empty(N, C, H, W, memory_format=torch.channels_last).to(device)
b. tensor conversion
device='cpu' # or 'xpu'
if device == 'xpu':
import intel_extension_for_pytorch
## .contiguous() transforms NHWC noncontiguous to NHWC contiguous.
## .to() converts NCHW tensor to NHWC one, it is outplace.
x = x.to(device)
x = x.contiguous(memory_format=torch.channels_last)
x = x.to(memory_format=torch.channels_last)
## contiguous check
x.is_contiguous(memory_format=torch.channels_last)
c. model conversion
device='cpu' # or 'xpu'
if device == 'xpu':
import intel_extension_for_pytorch
## NB: tensor.to() is an outplace operation
## model.to() is inplace. It calls _apply() which is inplace.
model = model.to(device).to(memory_format=torch.channels_last)
input = input.to(device).to(memory_format=torch.channels_last)
d. operator coverage in PyTorch
Detailed operator coverage information has been listed at reference Operators-with-Channels-Last-support.
Some spontaneous questions:
How to tell whether this model or operator support Channels Last? - This requires manual memory format check, aka. ‘torch.channels_last’ input and weight shall NOT generate ‘torch.contiguous_format’ output.
What if the model comprises of operator not supported Channels Last? - No errors messages will be shown, the NHWC tensor will be handled by the operator as a non-contiguous NCHW tensor, so result might not be correct depending on the algorithm of this operator.
Writing Channels Last Kernels on CPU
a. Register Channels Last Kernel in ATen Native Manner
The general guideline has been listed under reference Writing-memory-format-aware-operators, not to repeat here. You may take one of my recent PR optimize upsample performance linear mode on CPU as an example, which also demonstrates NHWC performance advantage over NCHW because of the ease of vectorization.
b. Register oneDNN Kernel on Channels Last
Registering a oneDNN kernel under Channels Last memory format on CPU is no different from cuDNN: Only very few upper level changes are needed, such as accommodate ‘contiguous()’ to ‘contiguous(suggested_memory_format)’. The automatic reorder of oneDNN weight shall have been hidden in ideep.
oneDNN NHWC APIs
Compared to NCHW interfaces, 2 parts need to be addressed on NHWC interfaces:
a. Create NHWC Memory
The logical size and stride description of oneDNN is always in NCHW, this is identical to PyTorch. Example code such as
/* create md from memory::format_tag */
auto src_md = memory::desc(
{N, C, H, W}, // logical dims, the order is defined by a primitive
memory::data_type::f32, // tensor's data type
memory::format_tag::nhwc // memory format, NHWC in this case
);
/* alternative: create md from strides */
auto src_md = memory::desc(
{N, C, H, W}, // logical dims, the order is defined by a primitive
memory::data_type::f32, // tensor's data type
{stride_N, stride_C, stride_H, stride_W} // the strides
);
/* create memory */
auto src_mem = memory(src_md, src_data_ptr, engine);
b. Create Convolution Primitive
NCHW - create
memory::descwith any card for ‘input’, ‘output’ and ‘weight’; query proposedmemory::descfrom convolution primitive;NHWC - create
memory::descwithformat_tag::nhwcfor ‘input’ and ‘output’, use any for ‘weight’; if we usehwiofor ‘weight’ convolution primitive will be created with gemm rather jit avx512.
Channels Last 1D support on XPU
Both stock PyTorch and Intel® Extension for PyTorch* support Channels Last(2D) and Channels Last 3D, however, regarding Channels Last 1D, they are different. Stock PyTorch doesn’t support Channels Last 1D, while XPU could supply limited support for Channels Last 1D. We only support Channels Last 1D memory format in these operators: Conv1D, BatchNorm1D, MaxPool1D, Concat, binary add, binary div, upsample linear and upsample nearest.
The usage of Channels Last 1D on XPU is different from stock PyTorch Channels Last(2D) or Channels Last 3D. We use torch.xpu.to_channels_last_1d() to do conversation for both input tensor and model. See below:
import torch
import intel_extension_for_pytorch
sycl_device = torch.device("xpu")
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.block = torch.nn.Sequential(
torch.nn.Conv1d(3, 3, kernel_size=3, stride=1, padding=1, bias=False),
torch.nn.BatchNorm1d(3)
)
def forward(self, x):
x = self.block(x)
return x
model = Model()
test_input = torch.rand([2, 3, 4])
test_input_xpu = test_input.to(sycl_device)
test_input_xpu = torch.xpu.to_channels_last_1d(test_input_xpu) # Channels Last 1D conversation for tenor
model = model.to(sycl_device)
model = torch.xpu.to_channels_last_1d(model) # Channels Last 1D conversation for mode
xpu_res = model(test_input_xpu)
print(torch.xpu.is_contiguous_channels_last_1d(xpu_res))
a. tensor conversion with Channels Last 1D
input_xpu = torch.xpu.to_channels_last_1d(input_xpu)
b. model conversion with Channels Last 1D
model = torch.xpu.to_channels_last_1d(model)
c. determine if in Channels Last 1D memory format
print(torch.xpu.is_contiguous_channels_last_1d(input))
Note that because Meta doesn’t support Channels Last 1D feature now: RFC: A suggestion of channels last memory format implementation for 3D tensor, expect Channels Last 1D APIs above, other APIs from stock PyTorch may be invalid. E.g.: If you want to use memory format corrsponding API for Channels Last 1D, it cannot work as you wish.