Welcome to Intel® Extension for PyTorch* Documentation
Intel® Extension for PyTorch* extends PyTorch* with up-to-date features optimizations for an extra performance boost on Intel hardware. Optimizations take advantage of AVX-512 Vector Neural Network Instructions (AVX512 VNNI) and Intel® Advanced Matrix Extensions (Intel® AMX) on Intel CPUs as well as Intel Xe Matrix Extensions (XMX) AI engines on Intel discrete GPUs. Moreover, through PyTorch* xpu device, Intel® Extension for PyTorch* provides easy GPU acceleration for Intel discrete GPUs with PyTorch*.
Intel® Extension for PyTorch* provides optimizations for both eager mode and graph mode, however, compared to eager mode, graph mode in PyTorch* normally yields better performance from optimization techniques, such as operation fusion. Intel® Extension for PyTorch* amplifies them with more comprehensive graph optimizations. Therefore we recommend you to take advantage of Intel® Extension for PyTorch* with TorchScript whenever your workload supports it. You could choose to run with torch.jit.trace() function or torch.jit.script() function, but based on our evaluation, torch.jit.trace() supports more workloads so we recommend you to use torch.jit.trace() as your first choice.
The extension can be loaded as a Python module for Python programs or linked as a C++ library for C++ programs. In Python scripts users can enable it dynamically by importing intel_extension_for_pytorch.
Intel® Extension for PyTorch* is structured as shown in the following figure:
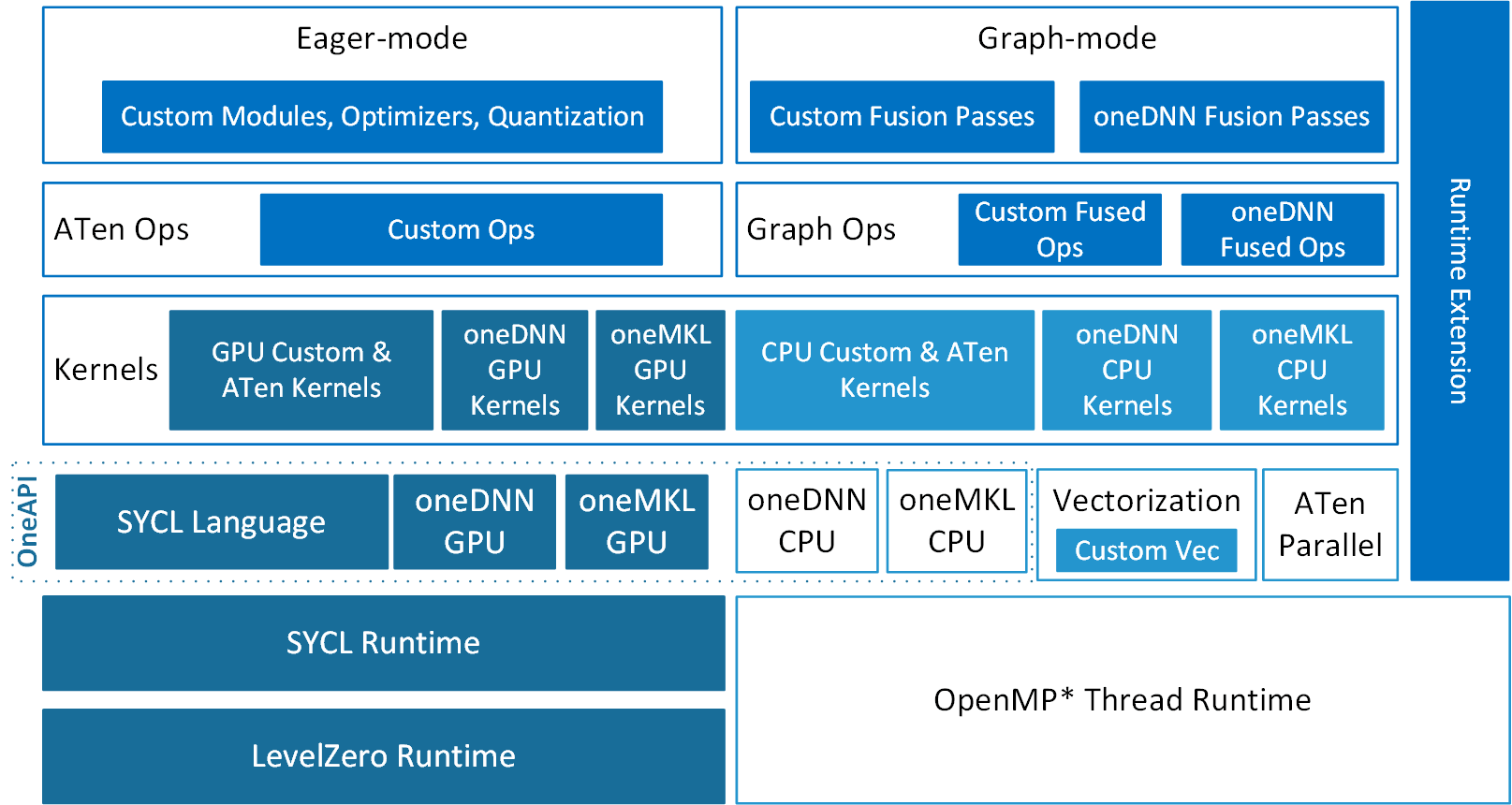
Optimizations for both eager mode and graph mode contribute to extra performance accelerations with the extension. In eager mode, the PyTorch frontend is extended with custom Python modules (such as fusion modules), optimal optimizers, and INT8 quantization APIs. Further performance boost is available by converting the eager-mode model into graph mode via extended graph fusion passes. In the graph mode, the fusions reduce operator/kernel invocation overheads, and thus increase performance. On CPU, Intel® Extension for PyTorch* dispatches the operators into their underlying kernels automatically based on ISA that it detects and leverages vectorization and matrix acceleration units available on Intel hardware. Intel® Extension for PyTorch* runtime extension brings better efficiency with finer-grained thread runtime control and weight sharing. On GPU, optimized operators and kernels are implemented and registered through PyTorch dispatching mechanism. These operators and kernels are accelerated from native vectorization feature and matrix calculation feature of Intel GPU hardware. Intel® Extension for PyTorch* for GPU utilizes the DPC++ compiler that supports the latest SYCL* standard and also a number of extensions to the SYCL* standard, which can be found in the sycl/doc/extensions directory.
Note
GPU features are not included in CPU only packages.
Intel® Extension for PyTorch* has been released as an open–source project at Github. Source code is available at xpu-master branch. Check the tutorial for detailed information. Due to different development schedule, optimizations for CPU only might have a newer code base. Source code is available at master branch. Check the CPU tutorial for detailed information on the CPU side.