Large Language Models (LLM) Optimization Overview
In the current technological landscape, Generative AI (GenAI) workloads and models have gained widespread attention and popularity. Large Language Models (LLMs) have emerged as the dominant models driving these GenAI applications. Most of LLMs are GPT-like architectures that consist of multiple Decoder layers. The MultiHeadAttention and FeedForward layer are two key components of every Decoder layer. The generation task is memory bound because iterative decode and kv_cache require special management to reduce memory overheads. Intel® Extension for PyTorch* provides a lot of specific optimizations for these LLMs. On the operator level, the extension provides highly efficient GEMM kernel to speed up Linear layer and customized operators to reduce the memory footprint. To better trade-off the performance and accuracy, different low-precision solutions e.g., smoothQuant and weight-only-quantization are also enabled. Besides, tensor parallel can also adopt to get lower latency for LLMs.
These LLM-specific optimizations can be automatically applied with a single frontend API function in Python interface, ipex.llm.optimize(). Check llm.optimize for more details.
ipex.llm Optimized Model List for Inference
Verified for single instance mode
| MODEL FAMILY |
MODEL NAME (Huggingface hub) |
FP32 | BF16 | Weight-Only Quantization INT8 |
Weight-Only Quantization INT4 |
|---|---|---|---|---|---|
LLAMA |
meta-llama/Llama-2-7b-hf |
✅ |
✅ |
✅ |
✅ |
LLAMA |
meta-llama/Llama-2-13b-hf |
✅ |
✅ |
✅ |
✅ |
LLAMA |
meta-llama/Llama-2-70b-hf |
✅ |
✅ |
✅ |
✅ |
LLAMA |
meta-llama/Meta-Llama-3-8B |
✅ |
✅ |
✅ |
✅ |
LLAMA |
meta-llama/Meta-Llama-3-70B |
✅ |
✅ |
✅ |
✅ |
LLAMA |
meta-llama/Meta-Llama-3.1-8B-Instruct |
✅ |
✅ |
✅ |
✅ |
LLAMA |
meta-llama/Llama-3.2-3B-Instruct |
✅ |
✅ |
✅ |
✅ |
LLAMA |
meta-llama/Llama-3.2-11B-Vision-Instruct |
✅ |
✅ |
✅ |
✅ |
GPT-J |
EleutherAI/gpt-j-6b |
✅ |
✅ |
✅ |
✅ |
GPT-NEOX |
EleutherAI/gpt-neox-20b |
✅ |
✅ |
✅ |
✅ |
DOLLY |
databricks/dolly-v2-12b |
✅ |
✅ |
✅ |
✅ |
FALCON |
tiiuae/falcon-7b |
✅ |
✅ |
✅ |
✅ |
FALCON |
tiiuae/falcon-11b |
✅ |
✅ |
✅ |
✅ |
FALCON |
tiiuae/falcon-40b |
✅ |
✅ |
✅ |
✅ |
FALCON |
tiiuae/Falcon3-7B-Instruct |
✅ |
✅ |
✅ |
✅ |
OPT |
facebook/opt-30b |
✅ |
✅ |
✅ |
✅ |
OPT |
facebook/opt-1.3b |
✅ |
✅ |
✅ |
✅ |
Bloom |
bigscience/bloom-1b7 |
✅ |
✅ |
✅ |
✅ |
CodeGen |
Salesforce/codegen-2B-multi |
✅ |
✅ |
✅ |
✅ |
Baichuan |
baichuan-inc/Baichuan2-7B-Chat |
✅ |
✅ |
✅ |
✅ |
Baichuan |
baichuan-inc/Baichuan2-13B-Chat |
✅ |
✅ |
✅ |
✅ |
Baichuan |
baichuan-inc/Baichuan-13B-Chat |
✅ |
✅ |
✅ |
✅ |
ChatGLM |
THUDM/chatglm3-6b |
✅ |
✅ |
✅ |
✅ |
ChatGLM |
THUDM/chatglm2-6b |
✅ |
✅ |
✅ |
✅ |
GPTBigCode |
bigcode/starcoder |
✅ |
✅ |
✅ |
✅ |
T5 |
google/flan-t5-xl |
✅ |
✅ |
✅ |
✅ |
MPT |
mosaicml/mpt-7b |
✅ |
✅ |
✅ |
✅ |
Mistral |
mistralai/Mistral-7B-v0.1 |
✅ |
✅ |
✅ |
✅ |
Mixtral |
mistralai/Mixtral-8x7B-v0.1 |
✅ |
✅ |
✅ |
✅ |
Stablelm |
stabilityai/stablelm-2-1_6b |
✅ |
✅ |
✅ |
✅ |
Qwen |
Qwen/Qwen-7B-Chat |
✅ |
✅ |
✅ |
✅ |
Qwen |
Qwen/Qwen2-7B |
✅ |
✅ |
✅ |
✅ |
Qwen |
Qwen/Qwen2.5-7B-Instruct |
✅ |
✅ |
✅ |
✅ |
Qwen |
Qwen/Qwen3-14B |
✅ |
✅ |
✅ |
|
Qwen |
Qwen/Qwen3-30B-A3B |
✅ |
✅ |
✅ |
✅ |
LLaVA |
liuhaotian/llava-v1.5-7b |
✅ |
✅ |
✅ |
✅ |
GIT |
microsoft/git-base |
✅ |
✅ |
✅ |
✅ |
Yuan |
IEITYuan/Yuan2-102B-hf |
✅ |
✅ |
✅ |
|
Phi |
microsoft/phi-2 |
✅ |
✅ |
✅ |
✅ |
Phi |
microsoft/Phi-3-mini-4k-instruct |
✅ |
✅ |
✅ |
✅ |
Phi |
microsoft/Phi-3-mini-128k-instruct |
✅ |
✅ |
✅ |
✅ |
Phi |
microsoft/Phi-3-medium-4k-instruct |
✅ |
✅ |
✅ |
✅ |
Phi |
microsoft/Phi-3-medium-128k-instruct |
✅ |
✅ |
✅ |
✅ |
Phi |
microsoft/Phi-4-mini-instruct |
✅ |
✅ |
✅ |
|
Phi |
microsoft/Phi-4-multimodal-instruct |
✅ |
✅ |
✅ |
|
Whisper |
openai/whisper-large-v2 |
✅ |
✅ |
✅ |
✅ |
Whisper |
openai/whisper-large-v3 |
✅ |
✅ |
✅ |
|
Maira |
microsoft/maira-2 |
✅ |
✅ |
✅ |
✅ |
Jamba |
ai21labs/Jamba-v0.1 |
✅ |
✅ |
✅ |
✅ |
DeepSeek |
deepseek-ai/DeepSeek-V2.5-1210 |
✅ |
✅ |
✅ |
✅ |
DeepSeek |
meituan/DeepSeek-R1-Channel-INT8 |
✅ |
Verified for distributed inference mode via DeepSpeed
| MODEL FAMILY |
MODEL NAME (Huggingface hub) |
BF16 | Weight-Only Quantization INT8 |
|---|---|---|---|
LLAMA |
meta-llama/Llama-2-7b-hf |
✅ |
✅ |
LLAMA |
meta-llama/Llama-2-13b-hf |
✅ |
✅ |
LLAMA |
meta-llama/Llama-2-70b-hf |
✅ |
✅ |
LLAMA |
meta-llama/Meta-Llama-3-8B |
✅ |
✅ |
LLAMA |
meta-llama/Meta-Llama-3-70B |
✅ |
✅ |
LLAMA |
meta-llama/Meta-Llama-3.1-8B-Instruct |
✅ |
✅ |
LLAMA |
meta-llama/Llama-3.2-3B-Instruct |
✅ |
✅ |
LLAMA |
meta-llama/Llama-3.2-11B-Vision-Instruct |
✅ |
✅ |
GPT-J |
EleutherAI/gpt-j-6b |
✅ |
✅ |
GPT-NEOX |
EleutherAI/gpt-neox-20b |
✅ |
✅ |
DOLLY |
databricks/dolly-v2-12b |
✅ |
✅ |
FALCON |
tiiuae/falcon-11b |
✅ |
✅ |
FALCON |
tiiuae/falcon-40b |
✅ |
✅ |
FALCON |
tiiuae/Falcon3-7B-Instruct |
✅ |
✅ |
OPT |
facebook/opt-30b |
✅ |
✅ |
OPT |
facebook/opt-1.3b |
✅ |
✅ |
Bloom |
bigscience/bloom-1b7 |
✅ |
✅ |
CodeGen |
Salesforce/codegen-2B-multi |
✅ |
✅ |
Baichuan |
baichuan-inc/Baichuan2-7B-Chat |
✅ |
✅ |
Baichuan |
baichuan-inc/Baichuan2-13B-Chat |
✅ |
✅ |
Baichuan |
baichuan-inc/Baichuan-13B-Chat |
✅ |
✅ |
GPTBigCode |
bigcode/starcoder |
✅ |
✅ |
T5 |
google/flan-t5-xl |
✅ |
✅ |
Mistral |
mistralai/Mistral-7B-v0.1 |
✅ |
✅ |
Mistral |
mistralai/Mixtral-8x7B-v0.1 |
✅ |
✅ |
MPT |
mosaicml/mpt-7b |
✅ |
✅ |
Stablelm |
stabilityai/stablelm-2-1_6b |
✅ |
✅ |
Qwen |
Qwen/Qwen-7B-Chat |
✅ |
✅ |
Qwen |
Qwen/Qwen2-7B |
✅ |
✅ |
Qwen |
Qwen/Qwen2.5-7B-Instruct |
✅ |
✅ |
Qwen |
Qwen/Qwen3-14B |
✅ |
✅ |
Qwen |
Qwen/Qwen3-30B-A3B |
✅ |
✅ |
GIT |
microsoft/git-base |
✅ |
✅ |
Phi |
microsoft/phi-2 |
✅ |
✅ |
Phi |
microsoft/Phi-3-mini-4k-instruct |
✅ |
✅ |
Phi |
microsoft/Phi-3-mini-128k-instruct |
✅ |
✅ |
Phi |
microsoft/Phi-3-medium-4k-instruct |
✅ |
✅ |
Phi |
microsoft/Phi-3-medium-128k-instruct |
✅ |
✅ |
Whisper |
openai/whisper-large-v2 |
✅ |
✅ |
Whisper |
openai/whisper-large-v3 |
✅ |
✅ |
DeepSeek |
deepseek-ai/DeepSeek-V2.5-1210 |
✅ |
✅ |
DeepSeek |
meituan/DeepSeek-R1-Channel-INT8 |
✅ |
Note: The above verified models (including other models in the same model family, like “codellama/CodeLlama-7b-hf” from LLAMA family) are well supported with all optimizations like indirect access KV cache, fused ROPE, and customized linear kernels. We are working in progress to better support the models in the tables with various data types. In addition, more models will be optimized in the future.
Please check LLM best known practice for instructions to install/setup environment and example scripts.
Module Level Optimization API for customized LLM (Prototype)
In the past year, LLM has been flourishing with many open-sourced models contributed to the community, while researchers are building their own LLMs from transformer blocks with variants in implementation details. To help LLM researchers and developers improve their productivity, Intel® Extension for PyTorch* provides module level optimizations for commonly used LLM modules and functionalities, which are operators or certain operator combinations in nature.
Please check LLM module level optimization practice to better understand how to use module level APIs to optimize your LLM and achieve better performance.
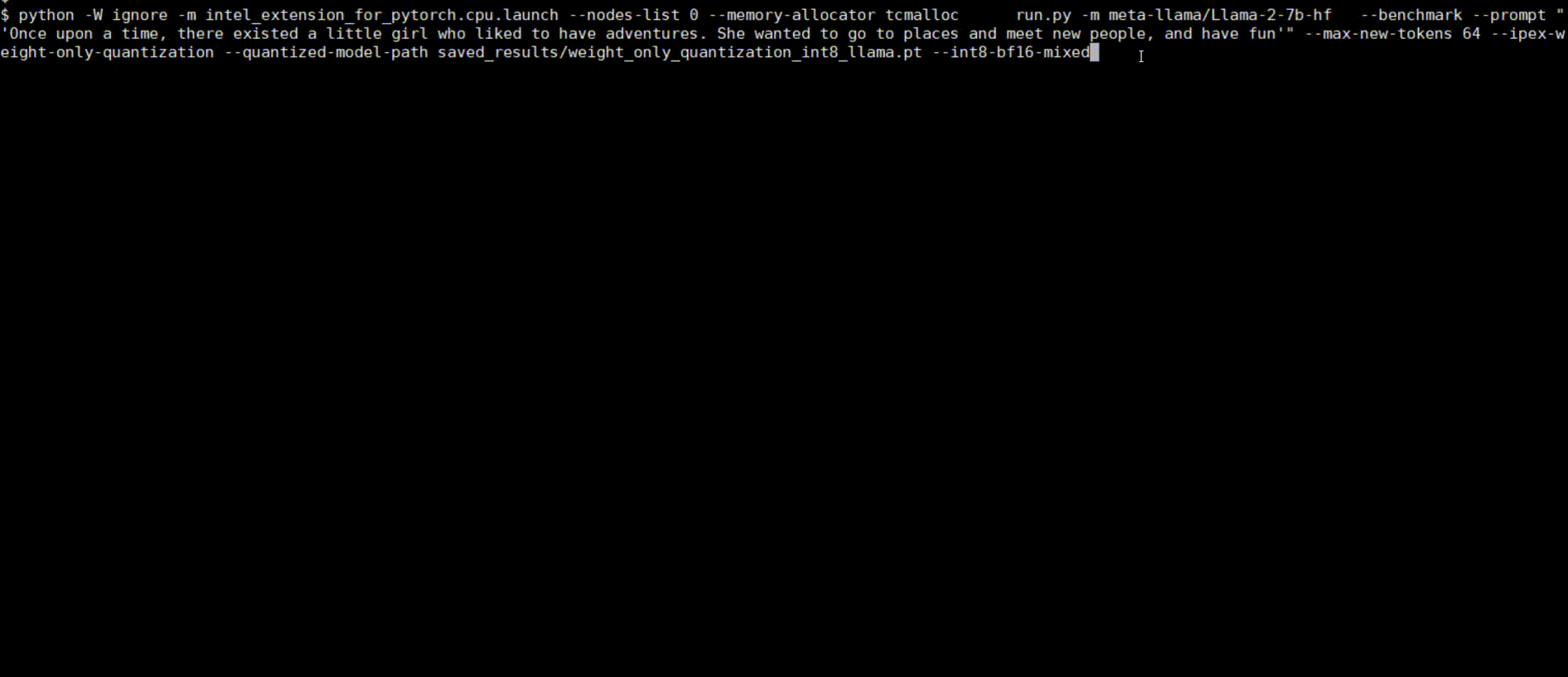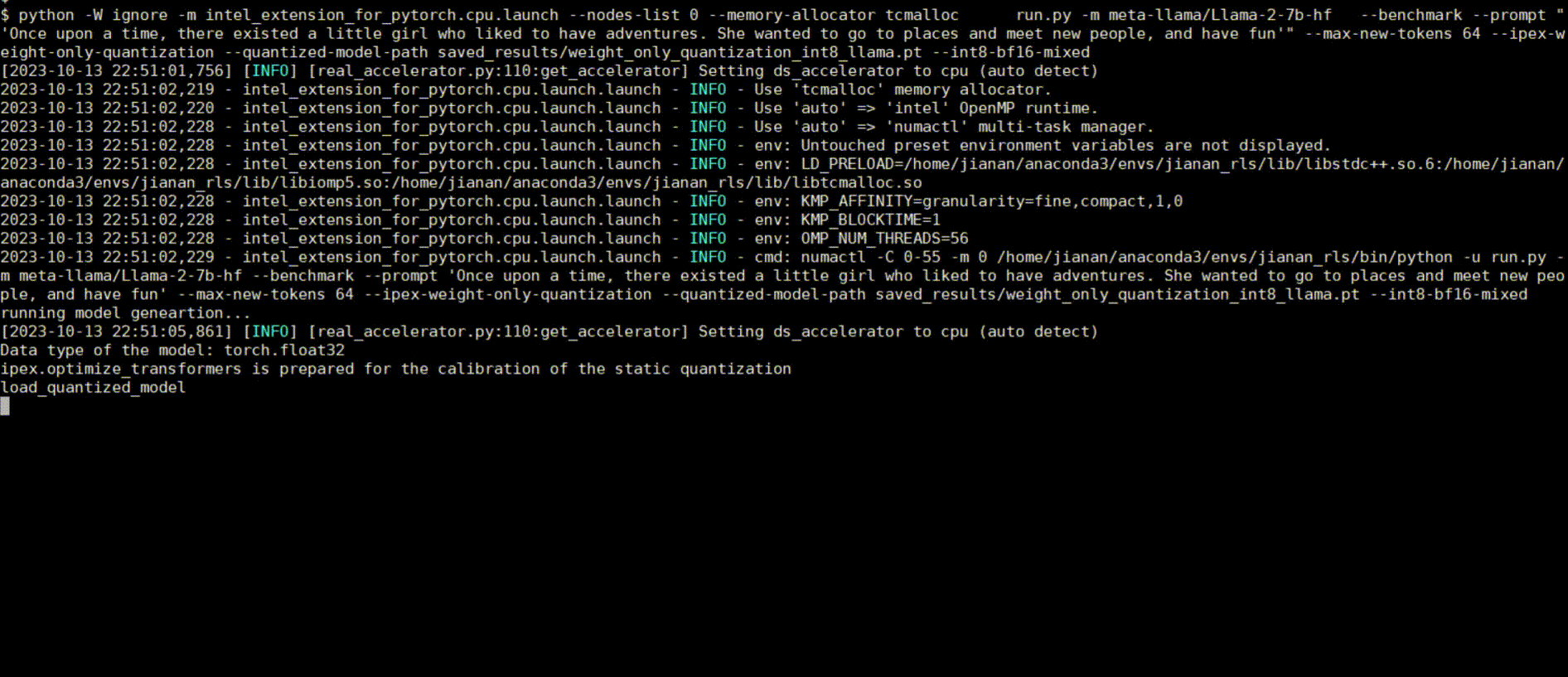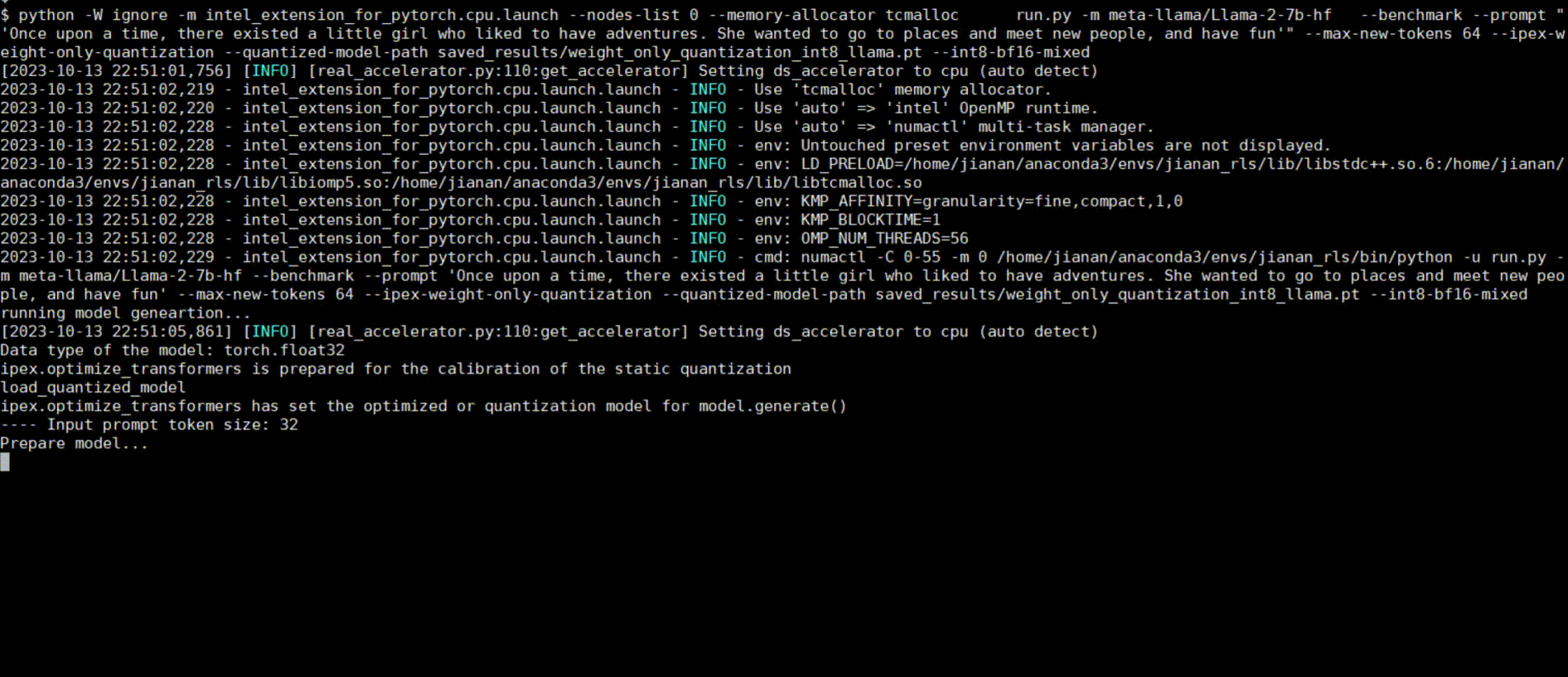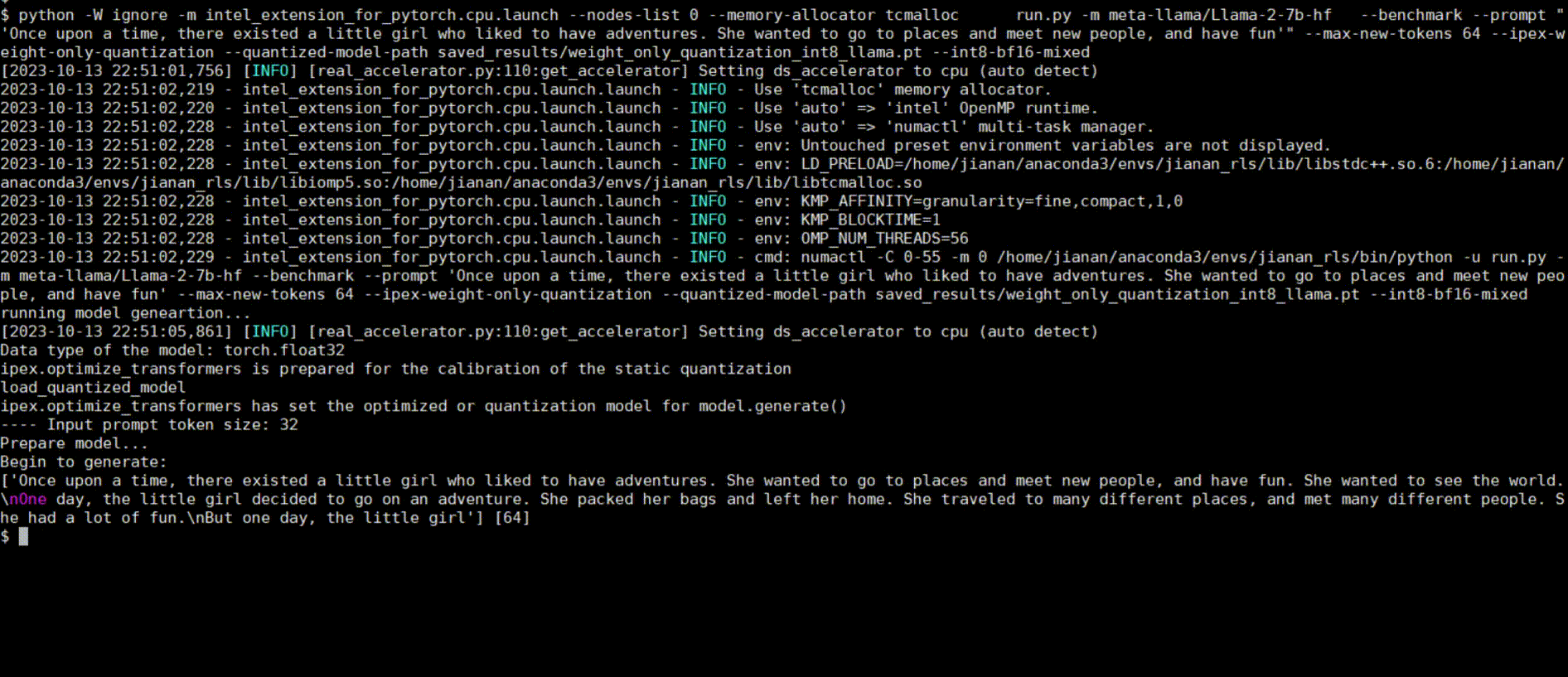
Demos
Intel® Extension for PyTorch* LLM optimizations can be integrated into a typical LLM Q&A web service.
|
|
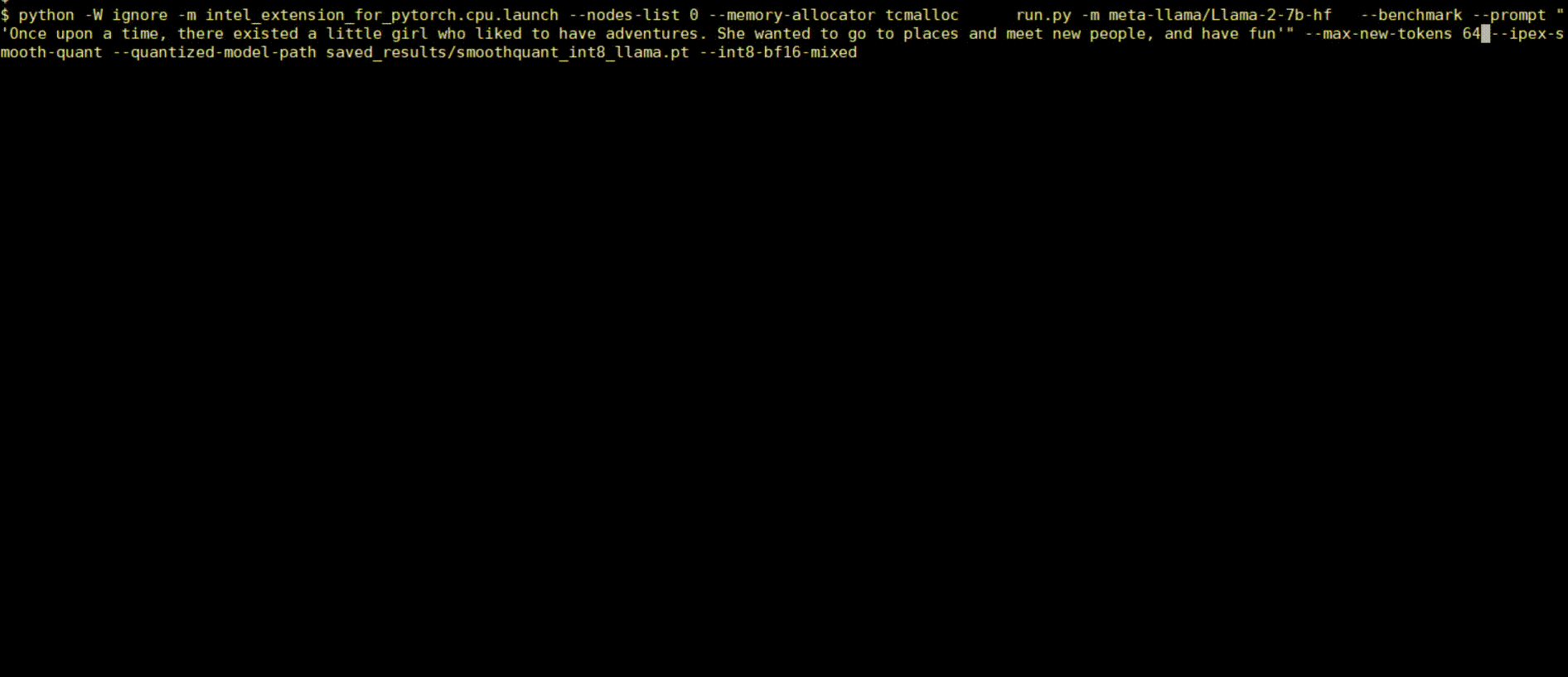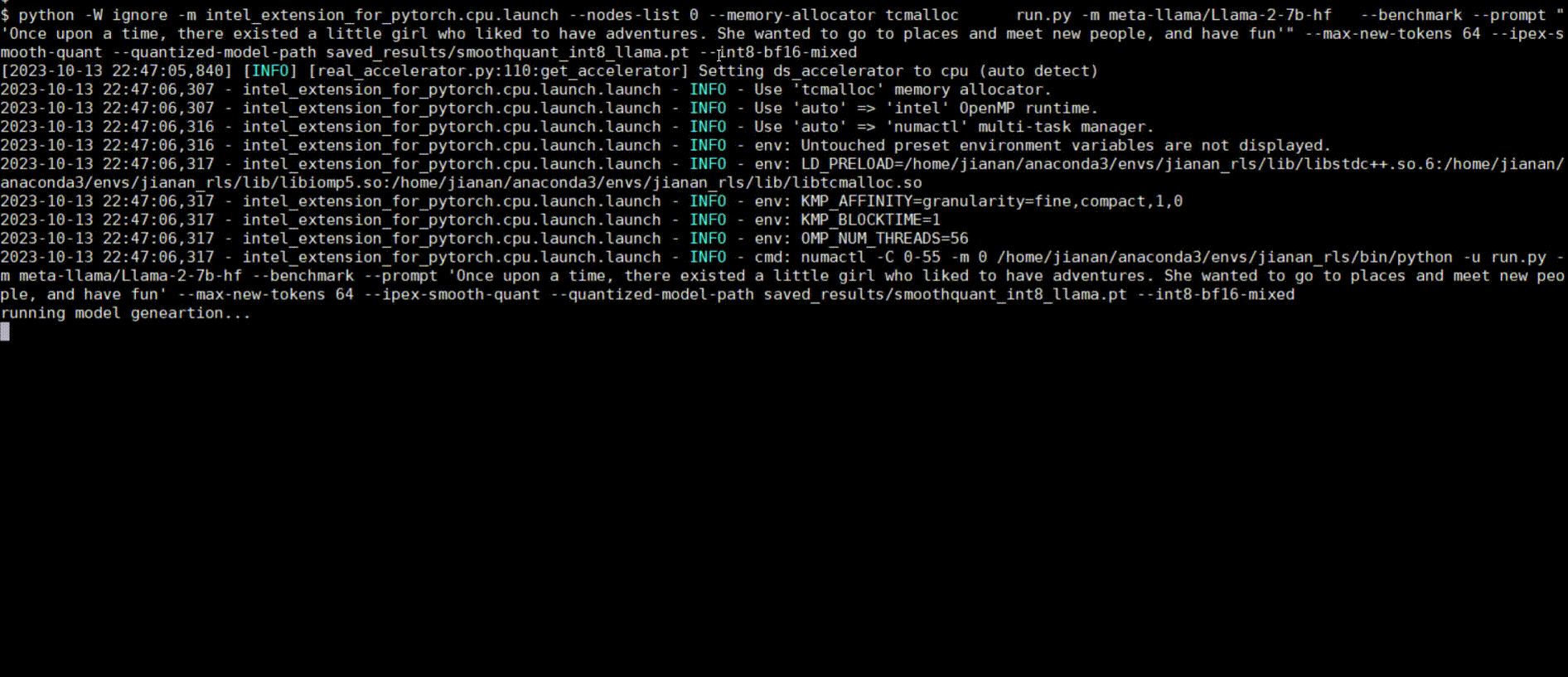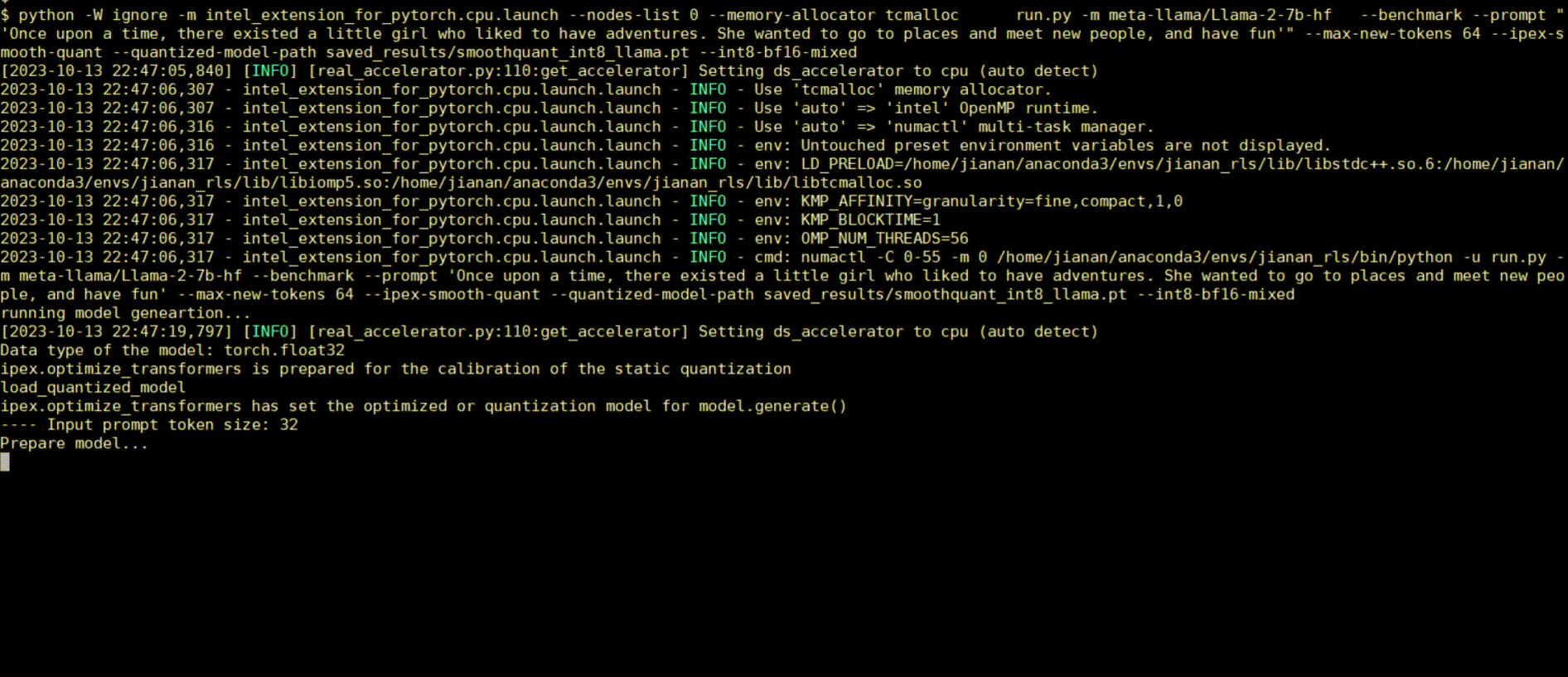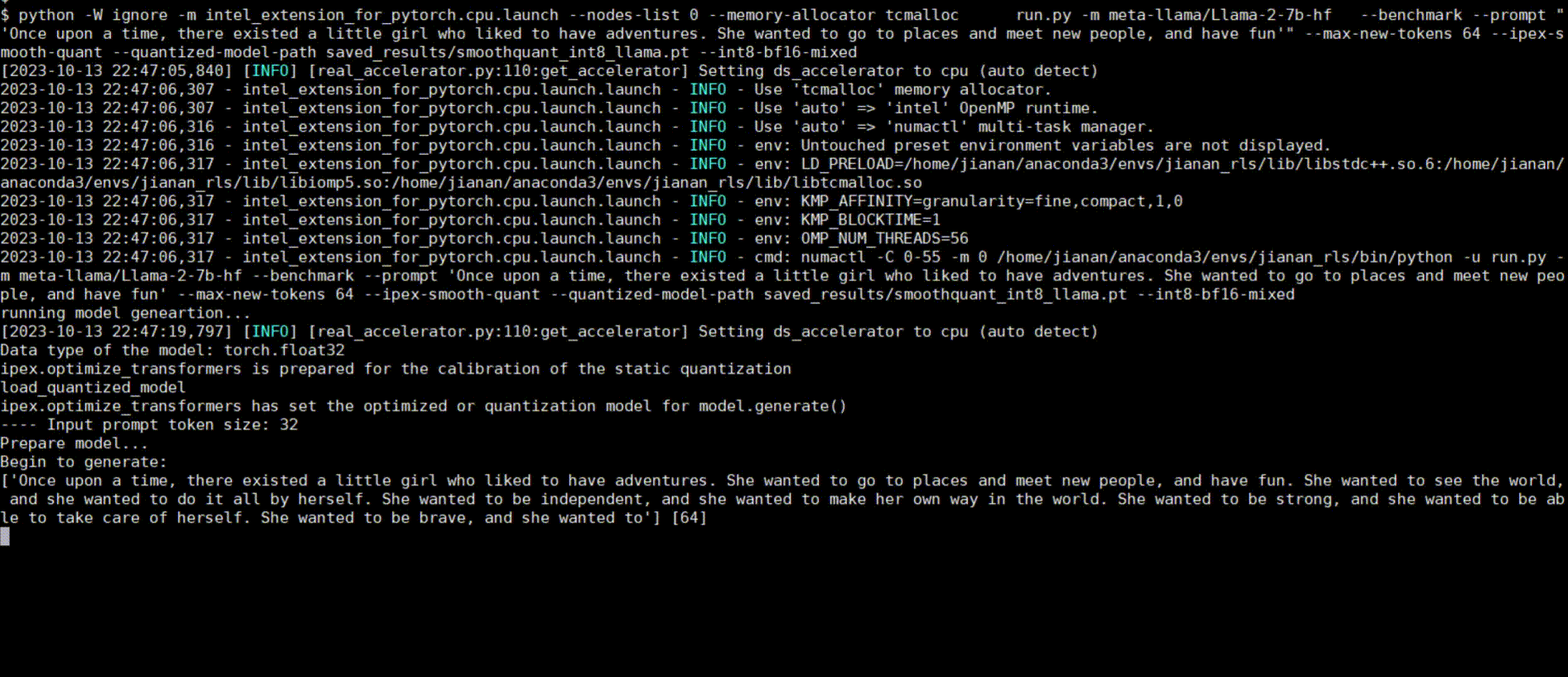
Following figures show demos with Llama 2 model and GPT-J model with single inference and distributed inference with deepspeed with lower precision data types.
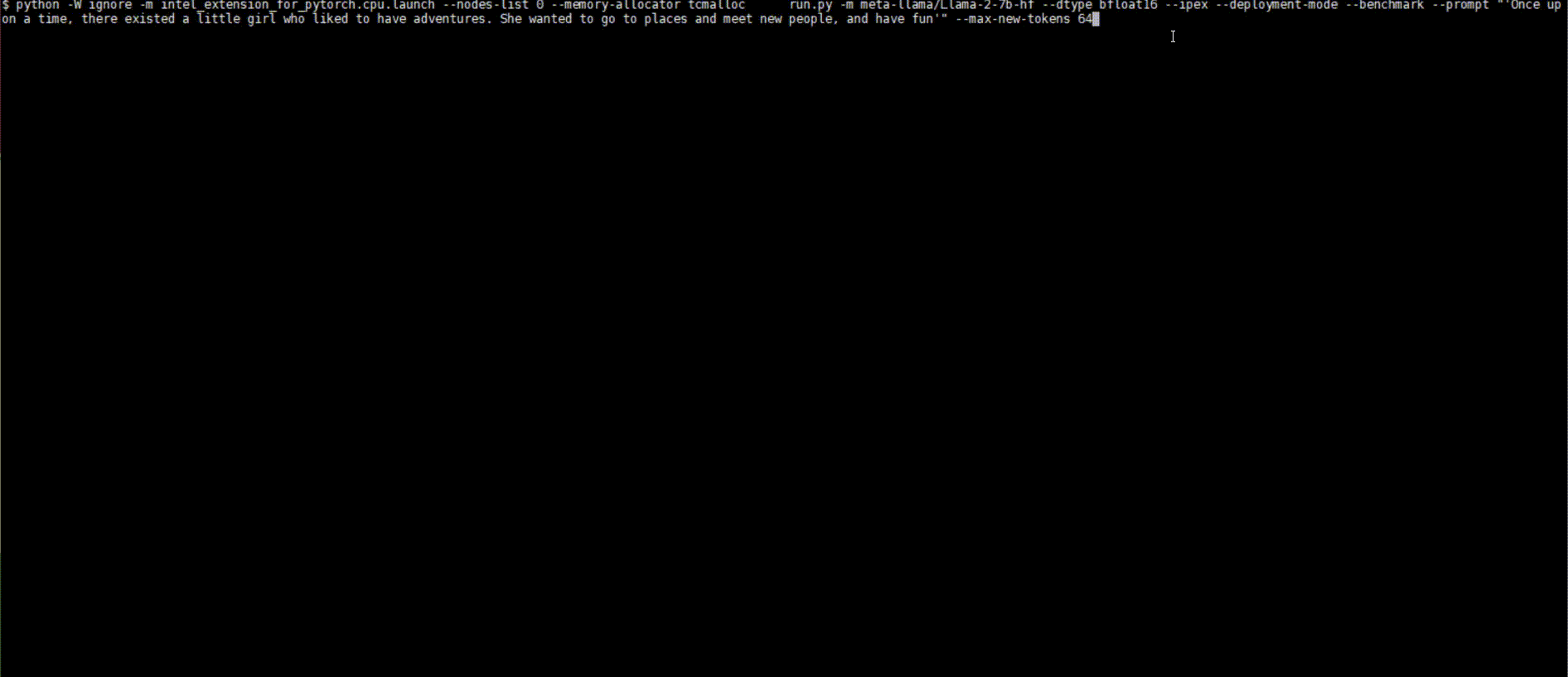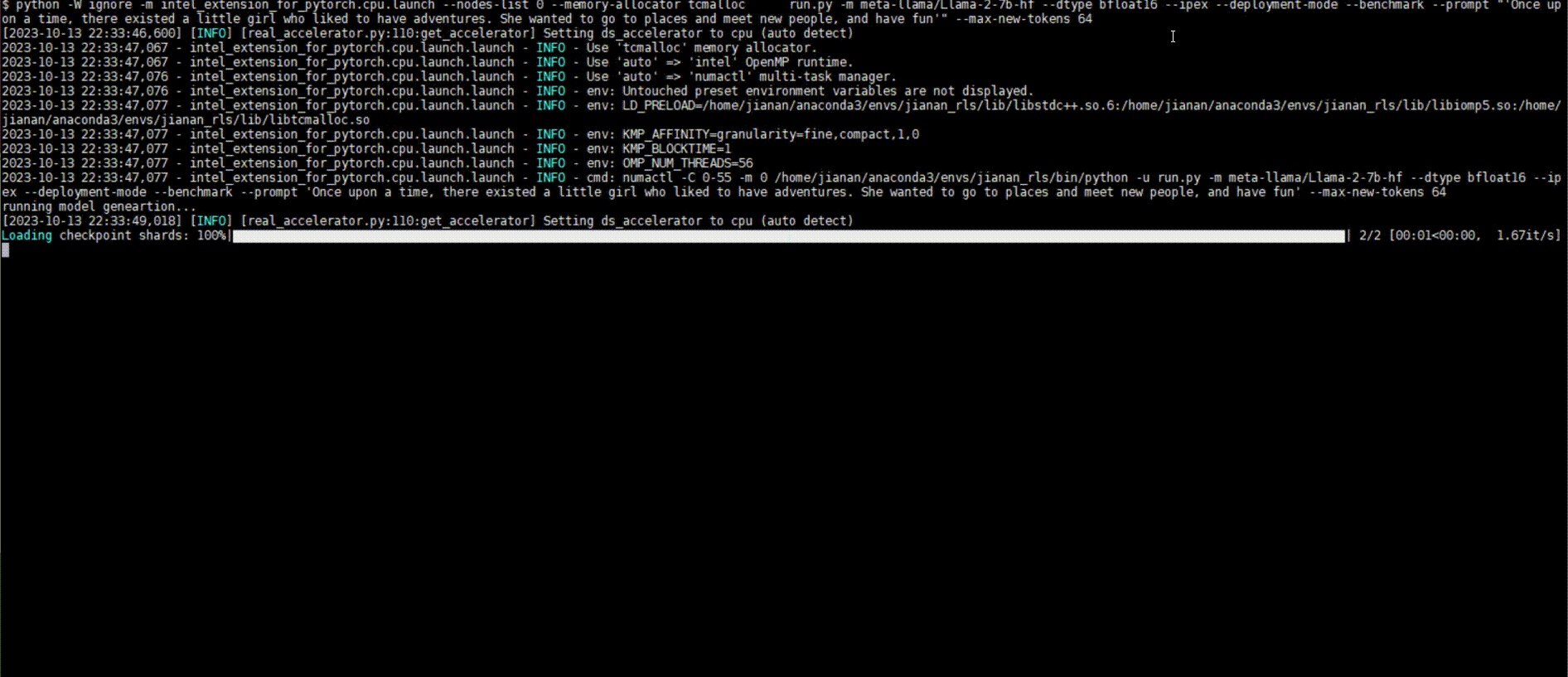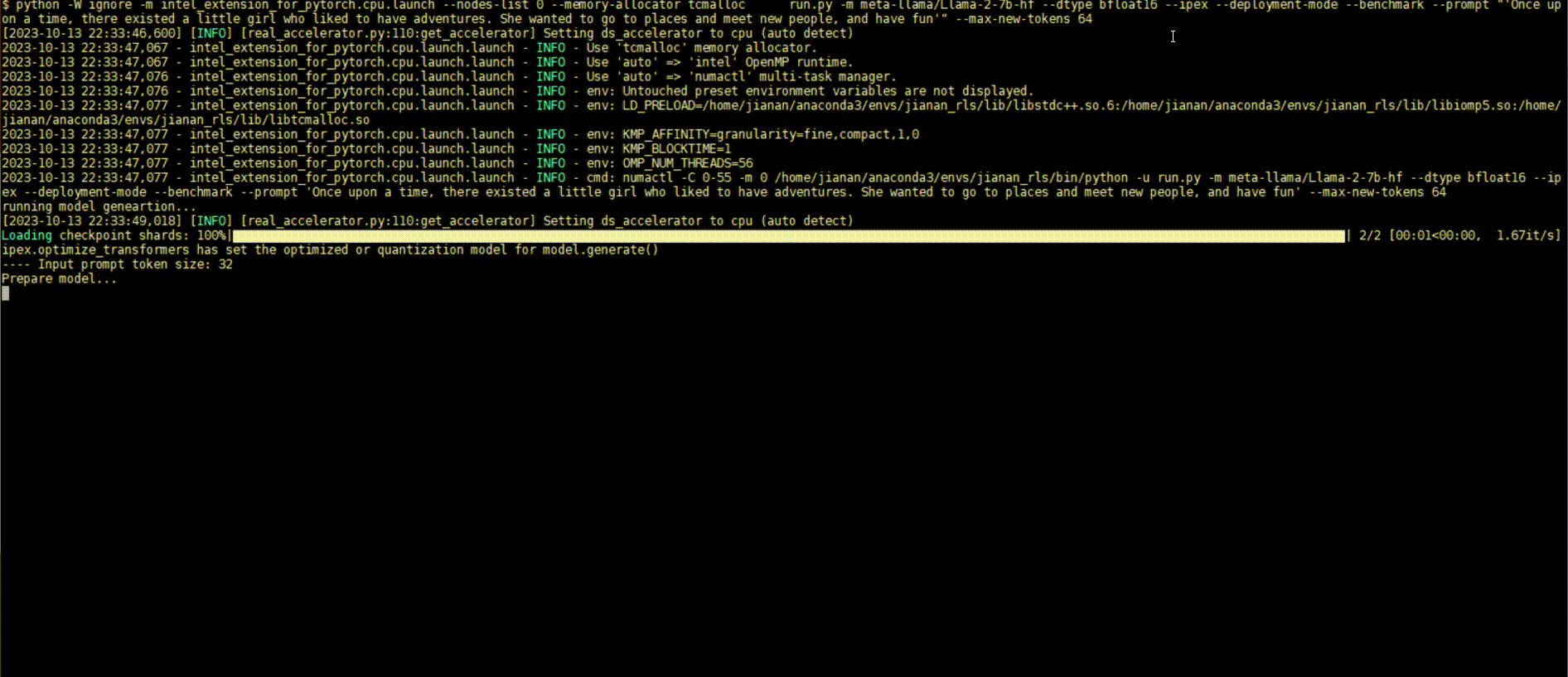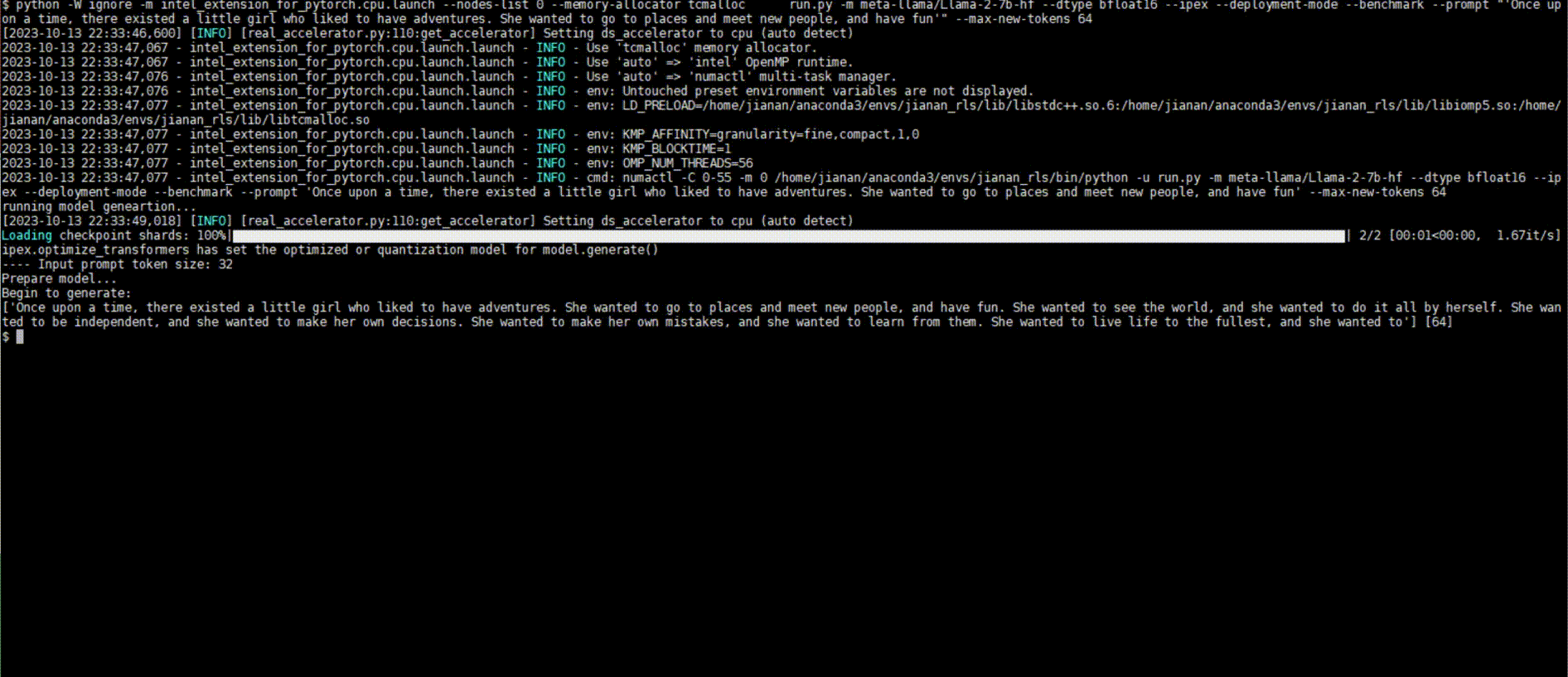
a |
b |
c |

d |
e |
f |
Figure Legends:
Llama 2 model with BF16
Llama 2 model with INT8 Quantization with SmoothQuant technique
Llama 2 model with INT8 Weight Only Quantization
GPT-J model with INT4 Weight Only Quantization
Llama 2 model Distributed Inference with DeepSpeed with AutoTP feature on BF16
Llama 2 model Distributed Inference with DeepSpeed with AutoTP feature with Weight Only Quantization INT8
Optimization Methodologies
The section below provides a brief introduction to LLM optimization methodologies:
Linear Operator Optimization
Linear operator is the most obvious hotspot in LLMs inference. Intel® Extension for PyTorch* provides dedicated optimization to speedup linear GEMM kernels, through oneDNN, customized linear kernels for weight only quantization, and some other specific tuning. All of them use specific block format to utilize hardware resources in a highly efficient way.
Low Precision Data Types
While Generative AI (GenAI) workloads and models are getting more and more popular, LLMs used in these workloads are getting more and more parameters. The increasing size of LLMs enhances workload accuracies; however, it also leads to significantly heavier computations and places higher requirements to the underlying hardware. Given that, quantization becomes a more important methodology for inference workloads.
Quantization with shorter data types benefits from its nature to improve memory IO throughputs and amount of computations on CPU. Moreover, shorter data types make it possible to keep more data in CPU cache, thus reducing memory access occurrences. Comparing to cache access, memory access is much more time costing. Specifically from computation perspective, AVX-512 Vector Neural Network Instructions (VNNI) instruction set shipped with the 2nd Generation Intel® Xeon® Scalable Processors and newer, as well as Intel® Advanced Matrix Extensions (Intel® AMX) instruction set shipped with the 4th Generation Intel® Xeon® Scalable Processors, provide instruction level accelerations to INT8 computations.
Except for the mixed-precision and INT8 native quantization solution, e.g., post-training static quantization and dynamic quantization in Pytorch, SmoothQuant and weight only quantization (both INT8 weight and INT4 weight are supported) are also enabled in Intel® Extension for PyTorch* to get beeter accuracy and performance compared with native solution.
Intel® Extension for PyTorch* speeds up INT8 computations by leveraging oneDNN and oneDNN graph as the backend. Intel® Extension for PyTorch* static quantization provides a default recipe to automatically decide which operators to quantize. Its backend oneDNN graph brings matrix-multiplication-based fusions for common seen operator patterns and other common fusions like quantization + data type casting. These fusions help achieve best computation cache locality and efficiency, and thus reduce INT8 quantization overhead significantly.
Intel® Extension for PyTorch* also delivers INT4 optimizations via 4-bit weight-only quantization (WOQ). As the name indicates, WOQ quantizes only weights to 4-bit integers to further improve the computation efficiency via saved memory bandwidth utilization. This technique reduces text generation latency especially from the second token. AMX INT8 instructions and fusions are also applied for these performant computations.
Indirect Access KV Cache
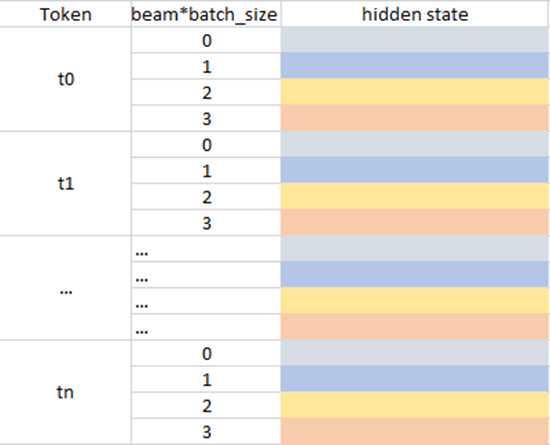
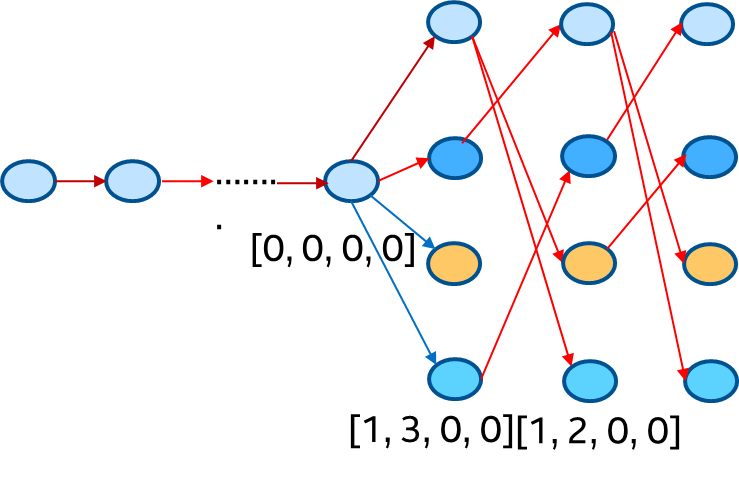
kv_cache is used to reduce computation for decoder layer but it also brings memory overheads. For example, when we use beam search, the kv_cache should be reordered according to latest beam idx and the current key/value should also be concat with kv_cache in the attention layer to get entire context to do scale dot product. When the sequence is very long, memory overheads caused by the reorder_cache and concat will be performance bottleneck. Indirect Access KV_cache (IAKV) is provided to reduce these overheads. Firstly, IAKV pre-allocates buffers (key and value use different buffer) to store all key/value hidden states and beam index information, the data format is shown in the following left figure (beam_width=4 in this case) and token state of key (value) in every timestamp will be store in this pre-allocated buffer. Secondly, we can use beam index history which is shown in the following right figure to decide which beam should be used by a timestamp and this information will generate a offset to access the kv_cache buffer which means that the reorder_cache and concat overheads will be eliminated by this way.
Graph Optimization
Operators fusion is generally used to enable sub-graph fusion to reduce the memory footprint. Except for linear post ops fusion, e.g, linear + activation function, a lot of customized operators are also provided in Intel® Extension for PyTorch* for further performance improvement. For example, Rotary Position Embedding (ROPE) and Root Mean Square Layer Normalization (RMSNorm).
Distributed Inference
All above optimizations already help you to get very good performance with single instance. To further reduce the inference latency and improve throughput, tensor parallel is also enabled in our solution. You can firstly use DeepSpeed to auto shard the model and then apply above optimizations with the frontend API function provided by Intel® Extension for PyTorch.