Performance
Overview
This page shows performance boost with Intel® Extension for PyTorch* on several popular topologies.
Performance Data for Intel® AI Data Center Products
Find the latest performance data for 4th gen Intel® Xeon® Scalable processors and 3rd gen Intel® Xeon® processors, including detailed hardware and software configurations, at Intel® Developer Zone article.
LLM Performance
We benchmarked LLaMA2 7B, 13B, GPT-J 6B with test input token length set to 256 and 1024 respectively. The tests were carried out on AWS M7i and M6i instances. CPUs of M6i instances are 3rd Gen Intel® Xeon® Processors which do not have AMX instructions for BF16 computing acceleration, so we take FP32 precision for benchmarking instead of BF16 on M6i instances.
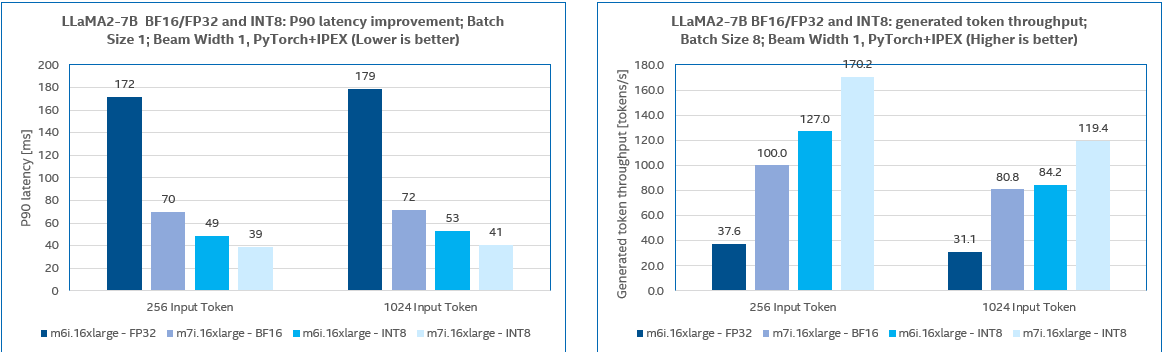
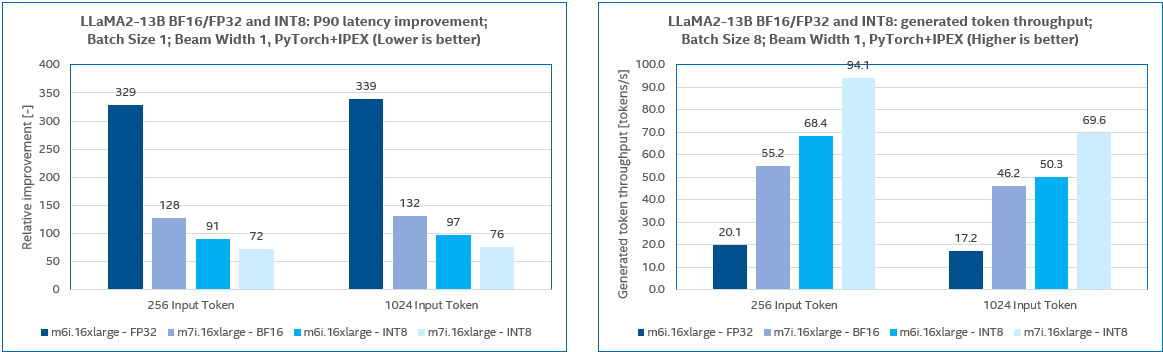
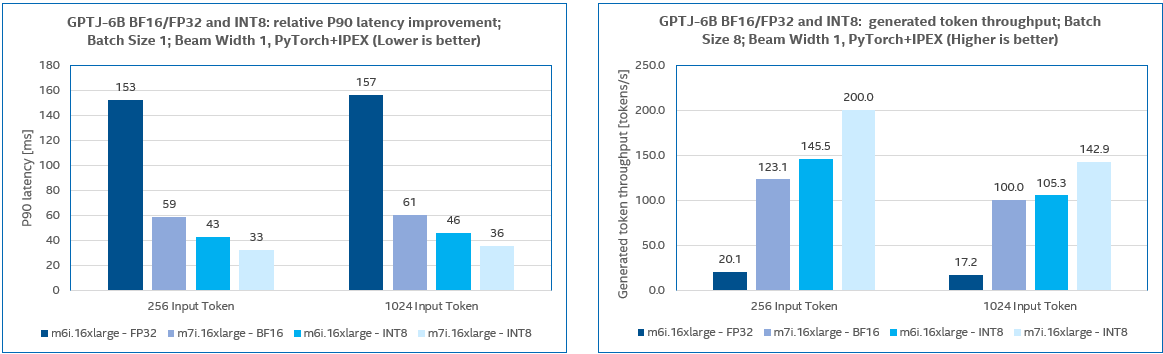
The LLM inference performances on M7i and M6i instances are compared based on the above results. M7i, with the 4th Gen Xeon® processors, has a remarkable performance advantage over M6i with the 3rd Gen Xeon® processors.
M7i performance boost ratio over M6i for non-quantized (BF16 or FP32) models:
| Speedup | Throughput | |
|---|---|---|
| LLaMA2 7B | 2.47x | 2.62x |
| LLaMA2 13B | 2.57x | 2.62x |
| GPT-J 6B | 2.58x | 2.85x |
M7i performance boost ratio over M6i for INT8 quantized models:
| Speedup | Throughput | |
|---|---|---|
| LLaMA2 7B | 1.27x | 1.38x |
| LLaMA2 13B | 1.27x | 1.27x |
| GPT-J 6B | 1.29x | 1.36x |
We can also conclude that with a larger batch size the capacity of the model service can be improved at the cost of longer response latency for the individual sessions. The following table exhibits that for INT8 quantized LLaMA2-7b model on M7i instances, input batch_size=8 would increase the total throughput by 6.47x compared with batch_size=1, whereas P90 token latency gets 1.26x longer.
| Batch size | Decoder latency | Total tokens per sec |
|---|---|---|
| 1 | 39 | 26.32 |
| 8 | 49 | 170.21 |
| Ratio | 1.26x | 6.47x |
Note: Measured by Intel on 17th Aug 2023; M7i.16xLarge, M6i.16xLarge instances in US-west-2. OS-Ubuntu 22.04-lts, kernel 6.20.0-1009-aws, SW: PyTorch* 2.1 and Intel® Extension for PyTorch* 2.1/llm_feature_branch.
INT8 with v1.11
Performance Numbers
| Hardware | Workload1 | Precision | Throughput Inference2 | Realtime Inference3 | Model Type | Dataset | Input Data Shape | Tunable Parameters | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Batch Size | Boost Ratio | Batch Size | Boost Ratio | |||||||
| Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz | ResNet50 | INT8 | 80 | 1.83x | 1 | 1.44x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
| SSD-ResNet34 | INT8 | 80 | 2.16x | 1 | 1.83x | Computer Vision | COCO | Input shape [3, 1200, 1200] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| ResNext 32x16d | INT8 | 80 | 1.81x | 1 | 1.21x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| VGG-11 | INT8 | 80 | 1.75x | 1 | 1.19x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| ShuffleNetv2_x1.0 | INT8 | 80 | 2.07x | 1 | 1.47x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; |
|
| BERT-Large | INT8 | 80 | 2.78x | 1 | 2.04x | NLP | Squad | max_seq_len=384 Task: Question Answering |
Jemalloc; Intel(R) OpenMP; inference scripts |
|
| Bert-Base | INT8 | 80 | 2.05x | 1 | 1.96x | NLP | MRPC | max_seq_len=128 Task: Text Classification |
Jemalloc; Intel(R) OpenMP; inference scripts |
|
| DistilBERT-Base | INT8 | 80 | 2.12x | 1 | 1.57x | NLP | Squad | max_seq_len=384 Task: Question Answering |
Jemalloc; Intel(R) OpenMP; inference scripts |
|
1. Model Zoo for Intel® Architecture
2. Throughput inference runs with single instance per socket.
3. Realtime inference runs with multiple instances, 4 cores per instance.
Note: Performance numbers with stock PyTorch are measured with its most performant configuration.
Note: Environment variable DNNL_PRIMITIVE_CACHE_CAPACITY is set to 1024.
Accuracy
| Workload | Metric | FP32 | INT8 | INT8/FP32 |
|---|---|---|---|---|
| BERT-base_text_classification | f1 | 0.81 | 0.81 | 99.79% |
| BERT-Large | f1 | 93.16 | 93.02 | 99.85% |
| Distilbert-base | f1 | 86.84 | 86.13 | 99.19% |
| ResNet50 | Top1 | 76.15 | 75.98 | 99.78% |
| ResNext 32x16d | Top1 | 84.17 | 84.05 | 99.86% |
| SSD-ResNet34 | mAP | 0.200 | 0.199 | 99.48% |
| VGG11 | Top1 | 69.04 | 67.96 | 98.44% |
| Shufflenetv2_x1.0 | Top1 | 69.36 | 67.92 | 97.93%1 |
1. ShuffleNet INT8 accuracy is expected to improve w/o performance trade-off via histogram calibration algorithm.
Configuration
Software Version
| Software | Version |
|---|---|
| PyTorch | v1.11.0 |
| Intel® Extension for PyTorch* | v1.11.0 |
Hardware Configuration
| 3rd Generation Intel® Xeon® Scalable Processors | |
|---|---|
| CPU | Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz |
| Number of nodes | 1 |
| Number of sockets | 2 |
| Cores/Socket | 40 |
| Threads/Core | 2 |
| uCode | 0xd0002a0 |
| Hyper-Threading | ON |
| TurboBoost | ON |
| BIOS version | 04.12.02 |
| Number of DDR Memory slots | 16 |
| Capacity of DDR memory per slot | 16GB |
| DDR frequency | 3200 |
| Total Memory/Node (DDR+DCPMM) | 256GB |
| Host OS | CentOS Linux release 8.4.2105 |
| Host Kernel | 4.18.0-305.10.2.el8_4.x86_64 |
| Docker OS | Ubuntu 18.04.5 LTS |
| Spectre-Meltdown Mitigation | Mitigated |
FP32 with v1.11.200 on an AWS EC2 C6i.2xlarge instance
Performance Numbers
| Hardware | Workload1 | Precision | Throughput Inference2 | Real-time Inference3 | Model Type | Dataset | Input Data Shape | Tunable Parameters | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Batch Size | Boost Ratio | Batch Size | Boost Ratio | |||||||
| AWS EC2 C6i.2xlarge | ResNet50 | Float32 | 64 | 1.24x | 1 | 1.31x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
| ResNext 32x16d | Float32 | 64 | 1.07x | 1 | 1.05x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| VGG-11 | Float32 | 64 | 1.15x | 1 | 1.21x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| ShuffleNetv2_x1.0 | Float32 | 64 | 1.12x | 1 | 1.30x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; |
|
| MobileNet v2 | Float32 | 64 | 1.08x | 1 | 1.12x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; |
|
| BERT-Large | Float32 | 64 | 1.05x | 1 | 1.03x | NLP | Squad | max_seq_len=384 Task: Question Answering |
Default memory allocator; Intel(R) OpenMP; inference scripts; Recommend to set auto_kernel_selection to ON when seq_len exceeds 64 |
|
| Bert-Base | Float32 | 64 | 1.08x | 1 | 1.09x | NLP | MRPC | max_seq_len=128 Task: Text Classification |
Jemalloc; Intel(R) OpenMP; inference scripts; Recommend to set auto_kernel_selection to ON when seq_len exceeds 128 |
|
1. Model Zoo for Intel® Architecture
2. Throughput inference runs with single instance per socket.
3. Realtime inference runs with multiple instances, 4 cores per instance.
Note: Performance numbers with stock PyTorch are measured with its most performant configuration.
Note: Environment variable DNNL_PRIMITIVE_CACHE_CAPACITY is set to 1024.
Configuration
Software Version
| Software | Version |
|---|---|
| PyTorch | v1.11.0 |
| Intel® Extension for PyTorch* | v1.11.200 |
FP32 and BFloat16 with v1.10
Performance Numbers
| Hardware | Workload1 | Precision | Throughput Inference2 | Real-time Inference3 | Model Type | Dataset | Input Data Shape | Tunable Parameters | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Batch Size | Boost Ratio | Batch Size | Boost Ratio | |||||||
| Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz | ResNet50 | Float32 | 80 | 1.39x | 1 | 1.35x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
| SSD-ResNet34 | Float32 | 160 | 1.55x | 1 | 1.06x | Computer Vision | COCO | Input shape [3, 1200, 1200] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| ResNext 32x16d | Float32 | 80 | 1.08x | 1 | 1.08x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| Faster R-CNN ResNet50 FPN | Float32 | 80 | 1.71x | 1 | 1.07x | Computer Vision | COCO | Input shape [3, 1200, 1200] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| VGG-11 | Float32 | 160 | 1.20x | 1 | 1.13x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| ShuffleNetv2_x1.0 | Float32 | 160 | 1.32x | 1 | 1.20x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; |
|
| MobileNet v2 | Float32 | 160 | 1.48x | 1 | 1.12x | Computer Vision | ImageNet | Input shape [3, 224, 224] |
Default memory allocator; Intel(R) OpenMP; |
|
| DLRM | Float32 | 80 | 1.11x | 1 | - | Recommendation | Terabyte | - | Default memory allocator; Intel(R) OpenMP; inference scripts |
|
| BERT-Large | Float32 | 80 | 1.14x | 1 | 1.02x | NLP | Squad | max_seq_len=384 Task: Question Answering |
Default memory allocator; Intel(R) OpenMP; inference scripts; Recommend to set auto_kernel_selection to ON when seq_len exceeds 64 |
|
| Bert-Base | Float32 | 160 | 1.10x | 1 | 1.33x | NLP | MRPC | max_seq_len=128 Task: Text Classification |
Jemalloc; Intel(R) OpenMP; inference scripts; Recommend to set auto_kernel_selection to ON when seq_len exceeds 128 |
|
| Intel(R) Xeon(R) Platinum 8380H CPU @ 2.90GHz | BERT-Large | BFloat16 | 56 | 1.67x | 1 | 1.45x | NLP | Squad | max_seq_len=384 Task: Question Answering |
Jemalloc; Intel(R) OpenMP; inference scripts |
| Bert-Base | BFloat16 | 112 | 1.77x | 1 | 1.18x | NLP | MRPC | max_seq_len=128 Task: Text Classification |
Jemalloc; Intel(R) OpenMP; inference scripts |
|
1. Model Zoo for Intel® Architecture
2. Throughput inference runs with single instance per socket.
3. Realtime inference runs with multiple instances, 4 cores per instance.
Note: Performance numbers with stock PyTorch are measured with its most performant configuration.
Note: Environment variable DNNL_PRIMITIVE_CACHE_CAPACITY is set to 1024.
Configuration
Software Version
| Software | Version |
|---|---|
| PyTorch | v1.10.1 |
| Intel® Extension for PyTorch* | v1.10.100 |
Hardware Configuration
| 3rd Generation Intel® Xeon® Scalable Processors | Products formerly Cooper Lake | |
|---|---|---|
| CPU | Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz | Intel(R) Xeon(R) Platinum 8380H CPU @ 2.90GHz |
| Number of nodes | 1 | 1 |
| Number of sockets | 2 | 2 |
| Cores/Socket | 40 | 28 |
| Threads/Core | 2 | 2 |
| uCode | 0xd0002a0 | 0x700001c |
| Hyper-Threading | ON | ON |
| TurboBoost | ON | ON |
| BIOS version | 04.12.02 | WLYDCRB1.SYS.0016.P29.2006080250 |
| Number of DDR Memory slots | 16 | 12 |
| Capacity of DDR memory per slot | 16GB | 64GB |
| DDR frequency | 3200 | 3200 |
| Total Memory/Node (DDR+DCPMM) | 256GB | 768GB |
| Host OS | CentOS Linux release 8.4.2105 | Ubuntu 18.04.4 LTS |
| Host Kernel | 4.18.0-305.10.2.el8_4.x86_64 | 4.15.0-76-generic |
| Docker OS | Ubuntu 18.04.5 LTS | Ubuntu 18.04.5 LTS |
| Spectre-Meltdown Mitigation | Mitigated | Mitigated |