Launch Script Usage Guide
Overview
As introduced in the Performance Tuning Guide, there are several factors that influence performance. Setting configuration options properly contributes to a performance boost. However, there is no unified configuration that is optimal to all topologies. Users need to try different combinations by themselves. A launch script is provided to automate these configuration settings to free users from this complicated work. This guide helps you to learn some common usage examples that cover many optimized configuration cases.
The configurations are mainly around the following perspectives.
OpenMP library: [Intel OpenMP library (default) | GNU OpenMP library]
Memory allocator: [PyTorch default memory allocator | Jemalloc | TCMalloc (default)]
Number of instances: [Single instance (default) | Multiple instances]
Usage of launch script
The launch script is provided as a module of intel_extension_for_pytorch. You can take advantage of it with the following command:
ipexrun [knobs] <your_pytorch_script> [args]
Available option settings (knobs) are listed below:
| knob | type | default value | help |
|---|---|---|---|
-h, --help |
- | - | show this help message and exit |
-m, --module |
- | False | Changes each process to interpret the launch script as a python module, executing with the same behavior as 'python -m'. |
--no-python |
- | False | Avoid applying python to execute program. |
--silent |
- | False | Suppress printings to stdio. |
--log-dir |
str | '' | The log file directory. Setting it to empty ('') disables logging to files. |
--log-file-prefix |
str | 'run' | log file name prefix |
Launcher Common Arguments:
| knob | type | default value | help |
|---|---|---|---|
--ncores-per-instance |
int | 0 | Number of cores per instance |
--nodes-list |
str | '' | Specify nodes list for multiple instances to run on, in format of list of single node ids "node_id,node_id,..." or list of node ranges "node_id-node_id,...". By default all nodes will be used. |
--use-e-cores |
- | False | Use Efficient-Cores on the workloads or not. By default, only Performance-Cores are used. |
--memory-allocator |
str | 'auto' | Choose which memory allocator to run the workloads with. Supported choices are ['auto', 'default', 'tcmalloc', 'jemalloc']. |
--omp-runtime |
str | 'auto' | Choose which OpenMP runtime to run the workloads with. Supported choices are ['auto', 'default', 'intel']. |
Multi-instance Arguments:
| knob | type | default value | help |
|---|---|---|---|
--ninstances |
int | 0 | Number of instances |
--instance-idx |
int | -1 | Inside the multi instance list, execute a specific instance at index. If it is set to -1, run all of them. |
--use-logical-cores |
- | False | Use logical cores on the workloads or not. By default, only physical cores are used. |
--skip-cross-node-cores |
- | False | Allow instances to be executed on cores across NUMA nodes. |
--multi-task-manager |
str | 'auto' | Choose which multi task manager to run the workloads with. Supported choices are ['auto', 'none', 'numactl', 'taskset']. |
--latency-mode |
- | False | Use 4 cores per instance over all physical cores. |
--throughput-mode |
- | False | Run one instance per node with all physical cores. |
--cores-list |
str | '' | Specify cores list for multiple instances to run on, in format of list of single core ids "core_id,core_id,..." or list of core ranges "core_id-core_id,...". By default all cores will be used. |
--benchmark |
- | False | Enable benchmark config. JeMalloc's MALLOC_CONF has been tuned for low latency. Recommend to use this for benchmarking purpose; for other use cases, this MALLOC_CONF may cause Out-of-Memory crash. |
Distributed Training Arguments With oneCCL backend:
| knob | type | default value | help |
|---|---|---|---|
--nnodes |
int | 0 | Number of machines/devices to use for distributed training |
--nprocs-per-node |
int | 0 | Number of processes run on each machine/device. It is by default the number of available nodes when set to 0. Argument --nodes-list affects this default value. |
--ccl-worker-count |
int | 4 | Number of cores per rank for ccl communication |
--logical-cores-for-ccl |
- | False | Use logical cores for the ccl worker. |
--master-addr |
str | 127.0.0.1 | Address of master node (rank 0), should be either IP address or hostname of node 0. For single node multi-proc training, the --master-addr can simply be 127.0.0.1. |
--master-port |
int | 29500 | Port on master node (rank 0) for communication during distributed training. |
--hostfile |
str | 'hostfile' | Set the hostfile for multi-node multi-proc training. The hostfile includes a node address list containing either IP addresses or hostnames of computation nodes. |
--extra-mpi-params |
str | '' | Extra parameters for mpiexec.hydra except for -np -ppn -hostfile and -genv I_MPI_PIN_DOMAIN |
Codeless Optimization feature related option settings (knobs) are listed below:
| knob | type | default value | help |
|---|---|---|---|
--auto-ipex |
- | False | Auto enabled the ipex optimization feature |
--dtype |
string | False | data type, can choose from ['float32', 'bfloat16'] |
--auto-ipex-verbose |
- | False | This flag is only used for debug and UT of auto ipex. |
--disable-ipex-graph-mode |
- | False | Enable the Graph Mode for ipex.optimize() function |
Note: --latency-mode and --throughput-mode are exclusive knobs to --ninstances, --ncores-per-instance and --use-logical-cores. I.e., setting either of --latency-mode or --throughput-mode overwrites settings of --ninstances, --ncores-per-instance and --use-logical-cores if they are explicitly set in command line. --latency-mode and --throughput-mode are mutually exclusive.
The launch script respects existing environment variables when it get launched, except for LD_PRELOAD. If you have your favorite values for certain environment variables, you can set them before running the launch script. Intel OpenMP library uses an environment variable KMP_AFFINITY to control its behavior. Different settings result in different performance numbers. By default, if you enable Intel OpenMP library, the launch script will set KMP_AFFINITY to granularity=fine,compact,1,0. If you want to try with other values, you can use export command on Linux to set KMP_AFFINITY before you run the launch script. In this case, the script will not set the default value but take the existing value of KMP_AFFINITY, and print a message to stdout.
Execution via the launch script can dump logs into files under a designated log directory so you can do some investigations afterward. By default, it is disabled to avoid undesired log files. You can enable logging by setting knob --log-dir to be:
directory to store log files. It can be an absolute path or relative path.
types of log files to generate. One file (
<prefix>_timestamp_instances.log) contains command and information when the script was launched. Another type of file (<prefix>_timestamp_instance_#_core#-core#....log) contain stdout print of each instance.
For example:
run_20210712212258_instances.log
run_20210712212258_instance_0_cores_0-43.log
Usage Examples
Example script resnet50.py will be used in this guide.
Single instance for inference
Multiple instances for inference
Usage of Jemalloc/TCMalloc/Default memory allocator
Usage of GNU OpenMP library
Note: GIF files below illustrate CPU usage ONLY. Do NOT infer performance numbers.
Single instance for inference
I. Use all physical cores
ipexrun --log-dir ./logs resnet50.py
CPU usage is shown as below. 1 main worker thread was launched, then it launched physical core number of threads on all physical cores.

If you check your log directory, you will find directory structure as below.
.
├── resnet50.py
└── logs
├── run_20210712212258_instance_0_cores_0-43.log
└── run_20210712212258_instances.log
The run_20210712212258_instances.log contains information and command that were used for this execution launch.
$ cat logs/run_20210712212258_instances.log
2021-07-12 21:22:58,764 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-12 21:22:58,764 - __main__ - INFO - OMP_NUM_THREADS=44
2021-07-12 21:22:58,764 - __main__ - INFO - Using Intel OpenMP
2021-07-12 21:22:58,764 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-12 21:22:58,764 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-12 21:22:58,764 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-12 21:22:58,764 - __main__ - WARNING - Numa Aware: cores:['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43'] on different NUMA nodes
2021-07-12 21:22:58,764 - __main__ - INFO - numactl -C 0-43 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712212258_instance_0_cores_0-43.log
II. Use all cores including logical cores
ipexrun --use-logical-core --log-dir ./logs resnet50.py
CPU usage is shown as below. 1 main worker thread was launched, then it launched threads on all cores, including logical cores.
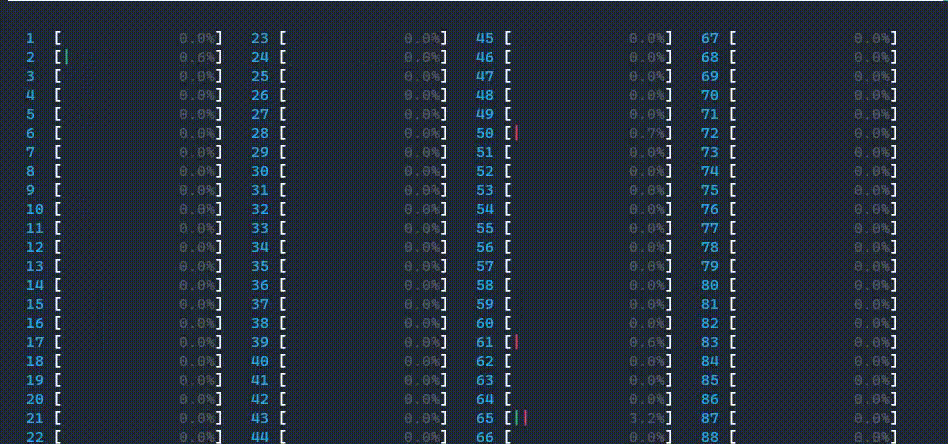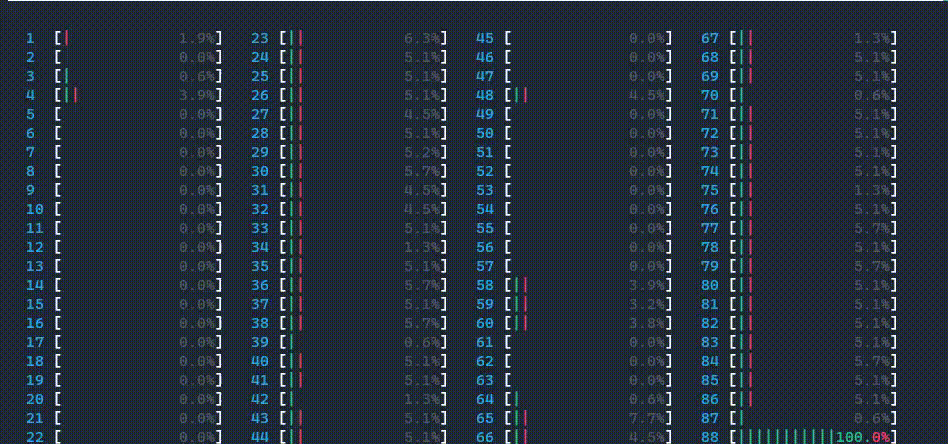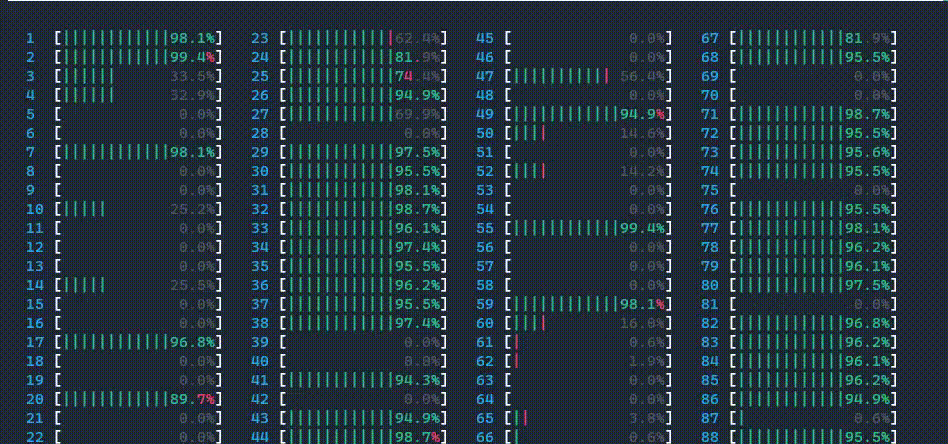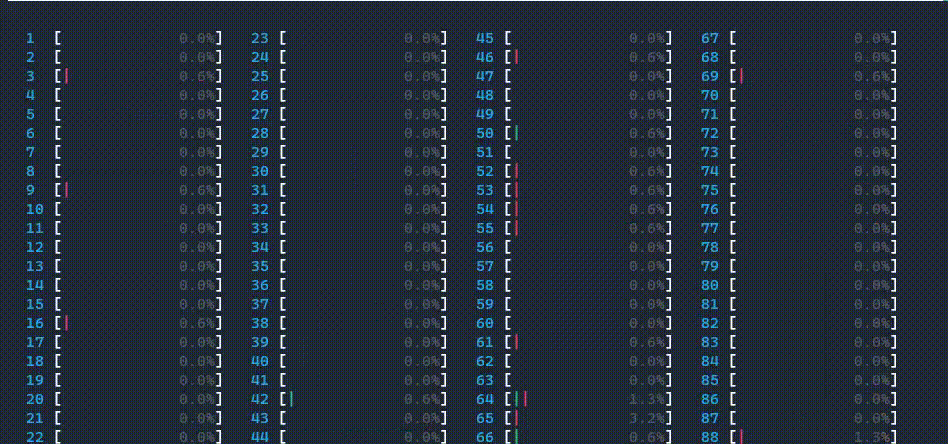
If you check your log directory, you will find directory structure as below.
.
├── resnet50.py
└── logs
├── run_20210712223308_instances.log
└── run_20210712223308_instance_0_cores_0-87.log
The run_20210712223308_instances.log contains information and command that were used for this execution launch.
$ cat logs/run_20210712223308_instances.log
2021-07-12 22:33:08,117 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-12 22:33:08,117 - __main__ - INFO - OMP_NUM_THREADS=88
2021-07-12 22:33:08,117 - __main__ - INFO - Using Intel OpenMP
2021-07-12 22:33:08,118 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-12 22:33:08,118 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-12 22:33:08,118 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-12 22:33:08,118 - __main__ - WARNING - Numa Aware: cores:['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87'] on different NUMA nodes
2021-07-12 22:33:08,118 - __main__ - INFO - numactl -C 0-87 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712223308_instance_0_cores_0-87.log
III. Use physical cores on designated nodes
ipexrun --nodes-list 1 --log-dir ./logs resnet50.py
CPU usage is shown as below. 1 main worker thread was launched, then it launched threads on all other cores on the same numa node.

If you check your log directory, you will find directory structure as below.
.
├── resnet50.py
└── logs
├── run_20210712214504_instances.log
└── run_20210712214504_instance_0_cores_22-43.log
The run_20210712214504_instances.log contains information and command that were used for this execution launch.
$ cat logs/run_20210712214504_instances.log
2021-07-12 21:45:04,512 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-12 21:45:04,513 - __main__ - INFO - OMP_NUM_THREADS=22
2021-07-12 21:45:04,513 - __main__ - INFO - Using Intel OpenMP
2021-07-12 21:45:04,513 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-12 21:45:04,513 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-12 21:45:04,513 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-12 21:45:04,513 - __main__ - INFO - numactl -C 22-43 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712214504_instance_0_cores_22-43.log
IV. Use your designated number of cores
ipexrun --ninstances 1 --ncores-per-instance 10 --log-dir ./logs resnet50.py
CPU usage is shown as below. 1 main worker thread was launched, then it launched threads on other 9 physical cores.

If you check your log directory, you will find directory structure as below.
.
├── resnet50.py
└── logs
├── run_20210712220928_instances.log
└── run_20210712220928_instance_0_cores_0-9.log
The run_20210712220928_instances.log contains information and command that were used for this execution launch.
$ cat logs/run_20210712220928_instances.log
2021-07-12 22:09:28,355 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-12 22:09:28,355 - __main__ - INFO - OMP_NUM_THREADS=10
2021-07-12 22:09:28,355 - __main__ - INFO - Using Intel OpenMP
2021-07-12 22:09:28,355 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-12 22:09:28,356 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-12 22:09:28,356 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-12 22:09:28,356 - __main__ - INFO - numactl -C 0-9 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712220928_instance_0_cores_0-9.log
You can also specify the cores to be utilized using --cores-list argument. For example, if core id 11-20 are desired instead of the first 10 cores, the launch command would be as below.
ipexrun --ncores-per-instance 10 --cores-list "11-20" --log-dir ./logs resnet50.py
Please notice that when specifying --cores-list, a correspondant --ncores-per-instance argument is required for instance number deduction.
In this case the log directory should be like
.
├── resnet50.py
└── logs
├── run_20210712221615_instances.log
└── run_20210712221615_instance_0_cores_11-20.log
The run_20210712221615_instances.log contains information and command that were used for this execution launch.
$ cat logs/run_20210712221615_instances.log
2021-07-12 22:16:15,591 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-12 22:16:15,591 - __main__ - INFO - OMP_NUM_THREADS=10
2021-07-12 22:16:15,591 - __main__ - INFO - Using Intel OpenMP
2021-07-12 22:16:15,591 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-12 22:16:15,591 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-12 22:16:15,591 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-12 22:16:15,591 - __main__ - INFO - numactl -C 11-20 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221615_instance_0_cores_11-20.log
Multiple instances for inference
V. Throughput mode
ipexrun --throughput-mode --log-dir ./logs resnet50.py
CPU usage is shown as below. 2 main worker threads were launched on 2 numa nodes respectively, then they launched threads on other physical cores.

If you check your log directory, you will find directory structure as below.
.
├── resnet50.py
└── logs
├── run_20210712221150_instances.log
├── run_20210712221150_instance_0_cores_0-21.log
└── run_20210712221150_instance_1_cores_22-43.log
The run_20210712221150_instances.log contains information and command that were used for this execution launch.
$ cat logs/run_20210712221150_instances.log
2021-07-12 22:11:50,233 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-12 22:11:50,233 - __main__ - INFO - OMP_NUM_THREADS=22
2021-07-12 22:11:50,233 - __main__ - INFO - Using Intel OpenMP
2021-07-12 22:11:50,233 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-12 22:11:50,233 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-12 22:11:50,233 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-12 22:11:50,233 - __main__ - INFO - numactl -C 0-21 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221150_instance_0_cores_0-21.log
2021-07-12 22:11:50,236 - __main__ - INFO - numactl -C 22-43 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221150_instance_1_cores_22-43.log
VI. Latency mode
ipexrun --latency-mode --log-dir ./logs resnet50.py
CPU usage is shown as below. 4 cores are used for each instance.

If you check your log directory, you will find directory structure as below.
.
├── resnet50.py
└── logs
├── run_20210712221415_instances.log
├── run_20210712221415_instance_0_cores_0-3.log
├── run_20210712221415_instance_1_cores_4-7.log
├── run_20210712221415_instance_2_cores_8-11.log
├── run_20210712221415_instance_3_cores_12-15.log
├── run_20210712221415_instance_4_cores_16-19.log
├── run_20210712221415_instance_5_cores_20-23.log
├── run_20210712221415_instance_6_cores_24-27.log
├── run_20210712221415_instance_7_cores_28-31.log
├── run_20210712221415_instance_8_cores_32-35.log
├── run_20210712221415_instance_9_cores_36-39.log
└── run_20210712221415_instance_10_cores_40-43.log
The run_20210712221415_instances.log contains information and command that were used for this execution launch.
$ cat logs/run_20210712221415_instances.log
2021-07-12 22:14:15,140 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-12 22:14:15,140 - __main__ - INFO - OMP_NUM_THREADS=4
2021-07-12 22:14:15,140 - __main__ - INFO - Using Intel OpenMP
2021-07-12 22:14:15,140 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-12 22:14:15,140 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-12 22:14:15,140 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-12 22:14:15,140 - __main__ - INFO - numactl -C 0-3 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_0_cores_0-3.log
2021-07-12 22:14:15,143 - __main__ - INFO - numactl -C 4-7 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_1_cores_4-7.log
2021-07-12 22:14:15,146 - __main__ - INFO - numactl -C 8-11 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_2_cores_8-11.log
2021-07-12 22:14:15,149 - __main__ - INFO - numactl -C 12-15 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_3_cores_12-15.log
2021-07-12 22:14:15,151 - __main__ - INFO - numactl -C 16-19 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_4_cores_16-19.log
2021-07-12 22:14:15,154 - __main__ - WARNING - Numa Aware: cores:['20', '21', '22', '23'] on different NUMA nodes
2021-07-12 22:14:15,154 - __main__ - INFO - numactl -C 20-23 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_5_cores_20-23.log
2021-07-12 22:14:15,157 - __main__ - INFO - numactl -C 24-27 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_6_cores_24-27.log
2021-07-12 22:14:15,159 - __main__ - INFO - numactl -C 28-31 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_7_cores_28-31.log
2021-07-12 22:14:15,162 - __main__ - INFO - numactl -C 32-35 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_8_cores_32-35.log
2021-07-12 22:14:15,164 - __main__ - INFO - numactl -C 36-39 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_9_cores_36-39.log
2021-07-12 22:14:15,167 - __main__ - INFO - numactl -C 40-43 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221415_instance_10_cores_40-43.log
VII. Your designated number of instances
ipexrun --ninstances 4 --log-dir ./logs resnet50.py
CPU usage is shown as below. 4 main worker thread were launched, then they launched threads on all other physical cores.

If you check your log directory, you will find directory structure as below.
.
├── resnet50.py
└── logs
├── run_20210712221305_instances.log
├── run_20210712221305_instance_0_cores_0-10.log
├── run_20210712221305_instance_1_cores_11-21.log
├── run_20210712221305_instance_2_cores_22-32.log
└── run_20210712221305_instance_3_cores_33-43.log
The run_20210712221305_instances.log contains information and command that were used for this execution launch.
$ cat logs/run_20210712221305_instances.log
2021-07-12 22:13:05,470 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-12 22:13:05,470 - __main__ - INFO - OMP_NUM_THREADS=11
2021-07-12 22:13:05,470 - __main__ - INFO - Using Intel OpenMP
2021-07-12 22:13:05,470 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-12 22:13:05,470 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-12 22:13:05,470 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-12 22:13:05,471 - __main__ - INFO - numactl -C 0-10 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221305_instance_0_cores_0-10.log
2021-07-12 22:13:05,473 - __main__ - INFO - numactl -C 11-21 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221305_instance_1_cores_11-21.log
2021-07-12 22:13:05,476 - __main__ - INFO - numactl -C 22-32 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221305_instance_2_cores_22-32.log
2021-07-12 22:13:05,479 - __main__ - INFO - numactl -C 33-43 -m 1 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210712221305_instance_3_cores_33-43.log
VIII. Your designated number of instances and instance index
Launcher by default runs all ninstances for multi-instance inference/training as shown above. You can specify instance_idx to independently run that instance only among ninstances
ipexrun --ninstances 4 --instance-idx 0 --log-dir ./logs resnet50.py
you can confirm usage in log file:
2022-01-06 13:01:51,175 - __main__ - INFO - OMP_NUM_THREADS=14
2022-01-06 13:01:51,176 - __main__ - INFO - Using Intel OpenMP
2022-01-06 13:01:51,177 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2022-01-06 13:01:51,177 - __main__ - INFO - KMP_BLOCKTIME=1
2022-01-06 13:01:51,177 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2022-01-06 13:01:51,177 - __main__ - INFO - numactl -C 0-10 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20220106130151_instance_0_cores_0-13.log
ipexrun --ninstances 4 --instance-idx 1 --log-dir ./logs resnet50.py
you can confirm usage in log file:
2022-01-06 13:01:51,175 - __main__ - INFO - OMP_NUM_THREADS=14
2022-01-06 13:01:51,176 - __main__ - INFO - Using Intel OpenMP
2022-01-06 13:01:51,177 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2022-01-06 13:01:51,177 - __main__ - INFO - KMP_BLOCKTIME=1
2022-01-06 13:01:51,177 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2022-01-06 13:01:51,177 - __main__ - INFO - numactl -C 11-21 -m 0 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20220106130151_instance_0_cores_0-13.log
Usage of Jemalloc/TCMalloc/Default memory allocator
Memory allocator influences performance sometime. If users do not designate desired memory allocator, the launch script searches them in the order of TCMalloc > Jemalloc > PyTorch default memory allocator, and takes the first matched one.
Jemalloc
Note: You can set your favorite value to MALLOC_CONF before running the launch script if you do not want to use its default setting.
ipexrun --memory-allocator jemalloc --log-dir ./logs resnet50.py
you can confirm usage in log file:
2021-07-13 15:30:48,235 - __main__ - INFO - Use JeMallocl memory allocator
2021-07-13 15:30:48,235 - __main__ - INFO - MALLOC_CONF=oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:9000000000,muzzy_decay_ms:9000000000
2021-07-13 15:30:48,235 - __main__ - INFO - OMP_NUM_THREADS=44
2021-07-13 15:30:48,235 - __main__ - INFO - Using Intel OpenMP
2021-07-13 15:30:48,235 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-13 15:30:48,235 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-13 15:30:48,235 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so:<VIRTUAL_ENV>/lib/libjemalloc.so
2021-07-13 15:30:48,236 - __main__ - WARNING - Numa Aware: cores:['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43'] on different NUMA nodes
2021-07-13 15:30:48,236 - __main__ - INFO - numactl -C 0-43 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210713153048_instance_0_cores_0-43.log
TCMalloc
ipexrun --memory-allocator tcmalloc --log-dir ./logs resnet50.py
you can confirm usage in log file:
2021-07-13 15:33:33,654 - __main__ - INFO - Use TCMalloc memory allocator
2021-07-13 15:33:33,654 - __main__ - INFO - OMP_NUM_THREADS=44
2021-07-13 15:33:33,654 - __main__ - INFO - Using Intel OpenMP
2021-07-13 15:33:33,654 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-13 15:33:33,654 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-13 15:33:33,654 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so:<VIRTUAL_ENV>/lib/libtcmalloc.so
2021-07-13 15:33:33,654 - __main__ - WARNING - Numa Aware: cores:['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43'] on different NUMA nodes
2021-07-13 15:33:33,655 - __main__ - INFO - numactl -C 0-43 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210713153333_instance_0_cores_0-43.log
Default memory allocator
ipexrun --memory-allocator default --log-dir ./logs resnet50.py
you can confirm usage in log file:
2021-07-13 15:36:59,784 - __main__ - INFO - OMP_NUM_THREADS=44
2021-07-13 15:36:59,784 - __main__ - INFO - Using Intel OpenMP
2021-07-13 15:36:59,784 - __main__ - INFO - KMP_AFFINITY=granularity=fine,compact,1,0
2021-07-13 15:36:59,784 - __main__ - INFO - KMP_BLOCKTIME=1
2021-07-13 15:36:59,784 - __main__ - INFO - LD_PRELOAD=<VIRTUAL_ENV>/lib/libiomp5.so
2021-07-13 15:36:59,784 - __main__ - WARNING - Numa Aware: cores:['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43'] on different NUMA nodes
2021-07-13 15:36:59,784 - __main__ - INFO - numactl -C 0-43 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210713153659_instance_0_cores_0-43.log
Usage of OpenMP library
Intel OpenMP Library
Generally, Intel OpenMP library brings better performance. Thus, in the launch script, Intel OpenMP library is used by default, if it is available. Intel OpenMP library takes environment variables like KMP_AFFINITY and KMP_BLOCKTIME to control its behavior. You can set your favorite values to them before running the launch script if you do not want to use the default settings.
GNU OpenMP Library
It is, however, not always that Intel OpenMP library brings better performance comparing to GNU OpenMP library. In this case, you can use knob --omp-runtime default to switch active OpenMP library to the GNU one. GNU OpenMP specific environment variables, OMP_SCHEDULE and OMP_PROC_BIND, for setting CPU affinity are set automatically.
ipexrun --omp-runtime default --log-dir ./logs resnet50.py
you can confirm usage in log file:
2021-07-13 15:25:00,760 - __main__ - WARNING - Both TCMalloc and JeMalloc are not found in $CONDA_PREFIX/lib or $VIRTUAL_ENV/lib or /.local/lib/ or /usr/local/lib/ or /usr/local/lib64/ or /usr/lib or /usr/lib64 or /home/<user>/.local/lib/ so the LD_PRELOAD environment variable will not be set. This may drop the performance
2021-07-13 15:25:00,761 - __main__ - INFO - OMP_SCHEDULE=STATIC
2021-07-13 15:25:00,761 - __main__ - INFO - OMP_PROC_BIND=CLOSE
2021-07-13 15:25:00,761 - __main__ - INFO - OMP_NUM_THREADS=44
2021-07-13 15:25:00,761 - __main__ - WARNING - Numa Aware: cores:['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43'] on different NUMA nodes
2021-07-13 15:25:00,761 - __main__ - INFO - numactl -C 0-43 <VIRTUAL_ENV>/bin/python resnet50.py 2>&1 | tee ./logs/run_20210713152500_instance_0_cores_0-43.log