Tuning Strategies
-
2.1. Tuning Space
2.2. Exit Policy
2.3. Accuracy Criteria
2.4. Tuning Process
-
3.1. Auto
3.2. Conservative Tuning
3.3. Basic
3.4. MSE
3.5. MSE_V2
3.6. HAWQ_V2
3.7. Bayesian
3.8. Exhaustive
3.9. Random
3.10. SigOpt
3.11. TPE
Introduction
Intel® Neural Compressor aims to help users quickly deploy
the low-precision inference solution on popular Deep Learning frameworks such as TensorFlow, PyTorch, ONNX, and MXNet. With built-in strategies, it automatically optimizes low-precision recipes for deep learning models to achieve optimal product objectives, such as inference performance and memory usage, with expected accuracy criteria. Currently, several tuning strategies, including auto, O0, O1, Basic, MSE, MSE_V2, HAWQ_V2, Bayesian, Exhaustive, Random, SigOpt, TPE, etc are supported. By default, the quant_level="auto" is used for tuning.
Strategy Design
Before tuning, the tuning space was constructed according to the framework capability and user configuration. Then the selected strategy generates the next quantization configuration according to its traverse process and the previous tuning record. The tuning process stops when meeting the exit policy. The function of strategies is shown
below:
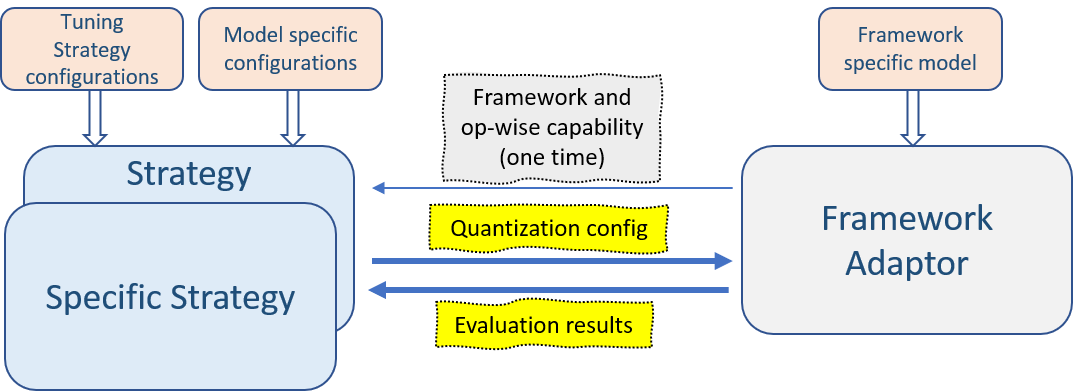
Tuning Space
Intel® Neural Compressor supports multiple quantization modes such as Post Training Static Quantization (PTQ static), Post Training Dynamic Quantization (PTQ dynamic), Quantization Aware Training, etc. One operator (OP) with a specific quantization mode has multiple ways to quantize, for example it may have multiple quantization scheme(symmetric/asymmetric), calibration algorithm(Min-Max/KL Divergence), etc. We use the framework capability to represent the methods that we have already supported. The tuning space includes all tuning items and their options. For example, the tuning items and options of the Conv2D (PyTorch) supported by Intel® Neural Compressor are as follows:
To incorporate the human experience and reduce the tuning time, user can reduce the tuning space by specifying the op_name_dict and op_type_dict in PostTrainingQuantConfig (QuantizationAwareTrainingConfig). Before tuning, the strategy will merge these configurations with framework capability to create the final tuning space.
Note: Any options in the
op_name_dictandop_type_dictthat are not included in theframework capabilitywill be ignored by the strategy.
Exit Policy
User can control the tuning process by setting the exit policy by specifying the timeout, and max_trials fields in the TuningCriterion.
from neural_compressor.config import TuningCriterion
tuning_criterion = TuningCriterion(
timeout=0, # optional. tuning timeout (seconds). When set to 0, early stopping is enabled.
max_trials=100, # optional. max tuning times. combined with the `timeout` field to decide when to exit tuning.
strategy="basic", # optional. name of the tuning strategy.
strategy_kwargs=None, # optional. see concrete tuning strategy for available settings.
)
Accuracy Criteria
User can set the accuracy criteria by specifying the higher_is_better, criterion, and tolerable_loss fields in the AccuracyCriterion.
from neural_compressor.config import AccuracyCriterion
accuracy_criterion = AccuracyCriterion(
higher_is_better=True, # optional.
criterion="relative", # optional. Available values are 'relative' and 'absolute'.
tolerable_loss=0.01, # optional.
)
Tuning Process
Intel® Neural Compressor allows users to choose different tuning processes by specifying the quantization level (quant_level). Currently, the recognized quant_levels are 0, 1, and "auto". For quant_level is 1, the tuning process can be finer-grained controlled by setting the strategy field.
0: “Conservative” tuning.0starts with anfp32model and tries to quantize OPs into lower precision by op-type-wise.0can be useful to give users insights about the accuracy degradation after quantizing some OPs.1: “Aggressive” tuning.1starts with the default quantization configuration and selects different quantization parameters.1can be used to achieve the performance."auto"(default) Auto tuning."auto"combines the advantages ofquant_level=0andquant_level=1. Currently, it tries default quantization configuration,0, andbasicstrategy sequentially.
Tuning Algorithms
Auto
Design
The auto tuning (quant_level="auto") is the default tuning process. Classical settings are shown below:
Usage
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level="auto", # optional, the quantization level.
tuning_criterion=TuningCriterion(
timeout=0, # optional. tuning timeout (seconds). When set to 0, early stopping is enabled.
max_trials=100, # optional. max tuning times. combined with the `timeout` field to decide when to exit tuning.
),
)
Conservative Tuning
Design
The conservative tuning (quant_level=0) starts with an fp32 model and tries to convert key OPs like conv, matmul, or linear into lower precision op-type-wise.
Usage
To use conservative tuning, the quant_level field should be set to 0 in PostTrainingQuantConfig.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=0, # the quantization level.
tuning_criterion=TuningCriterion(
timeout=0, # optional. tuning timeout (seconds). When set to 0, early stopping is enabled.
max_trials=100, # optional. max tuning times. combined with the `timeout` field to decide when to exit tuning.
),
)
Basic
Design
The Basic strategy is designed for quantizing most models. There are several stages executed by Basic strategy sequentially, and the tuning process ends once the condition meets the exit policy. The diagram below illustrates each stage, accompanied by additional details provided for each annotated step.
%%{init: {"flowchart": {"htmlLabels": false}} }%%
flowchart TD
classDef itemStyle fill:#CCE5FF,stroke:#99CCFF;
start([Start])
s1("1. Default quantization")
s2("2. Apply all recipes [Opt]")
s3("3. OP-type-wise tuning")
s4("4. Try recipe one by one [Opt]")
s5("5.1 Block-wise fallback*")
s6("5.2 Instance-wise fallback")
s7("5.3 Accumulated fallback")
start:::itemStyle --> s1:::itemStyle
s1 --> s2:::itemStyle
s2 --> s3:::itemStyle
s3 --> s4:::itemStyle
s4 --> s5:::itemStyle
subgraph title["Fallback #nbsp; "]
s5 --> s6:::itemStyle
s6 --> s7:::itemStyle
end
classDef subgraphStyle fill:#FFFFFF,stroke:#99CCFF;
class title subgraphStyle
Optstands for optional which mean this stage can be skipped.
*INC will detect the block pattern for transformer-like model by default.
For smooth quantization, users can tune the smooth quantization alpha by providing a list of scalars for the
alphaitem. For details usage, please refer to the smooth quantization example.
For weight-only quantization, users can tune the weight-only algorithms from the available pre-defined configurations. The tuning process will take place at the start stage of the tuning procedure, preceding the smooth quantization alpha tuning. For details usage, please refer to the weight-only quantization example. Please note that this behavior is specific to the
ONNX Runtimebackend.
1. Default quantization
At this stage, it attempts to quantize OPs with the default quantization configuration which is consistent with the framework’s behavior.
2. Apply all recipes
At this stage, it tries to apply all recipes. This stage will be skipped if user assigned the usage of all recipes.
3. OP-Type-Wise Tuning
At this stage, it tries to quantize OPs as many as possible and traverse all OP type wise tuning configs. Note that, the OP is initialized with different quantization modes according to the quantization approach.
a. post_training_static_quant: Quantize all OPs support PTQ static.
b. post_training_dynamic_quant: Quantize all OPs support PTQ dynamic.
c. post_training_auto_quant: Quantize all OPs support PTQ static or PTQ dynamic. For OPs supporting both PTQ static and PTQ dynamic, PTQ static will be tried first, and PTQ dynamic will be tried when none of the OP type wise tuning configs meet the accuracy loss criteria.
4. Try recipe One by One
At this stage, it sequentially tries recipe based on the tuning config with the best result in the previous stage. This stage will be skipped the recipes(s) specified by user.
If the above trials not meet the accuracy requirements, it start to performs fallback, which mean converting quantized OP(s) into high-precision(FP32, BF16 …).
5.1 Block-wise fallback*
For the transformer-like model, it will use the detected transformer block by default, and conduct the block-wise fallback. In each trial, all OPs within a block are reverted to high-precision.
5.2 Instance-wise fallback
At this stage, it performs high-precision OP (FP32, BF16 …) fallbacks one by one based on the tuning config with the best result in the previous stage, and records the impact of each OP.
5.3 Accumulated fallback
At the final stage, it first sorted the OPs list according to the impact score in stage V, and tries to incrementally fallback multiple OPs to high precision according to the sorted OP list.
Usage
Basic is the default strategy for quant_level=1, it can be used by default with nothing changed in the strategy field of TuningCriterion after set the quant_level=1 in PostTrainingQuantConfig. Classical settings are shown below:
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(strategy="basic"), # optional. name of tuning strategy.
)
MSE
Design
MSE and Basic strategies share similar ideas. The primary difference
between the two strategies is the way sorted op lists generated in stage II. The MSE strategy needs to get the tensors for each OP of raw FP32
models and the quantized model based on the best model-wise tuning
configuration. It then calculates the MSE (Mean Squared Error) for each
OP, sorts those OPs according to the MSE value, and performs
the op-wise fallback in this order.
Usage
The usage of MSE is similar to Basic. To use MSE strategy, the strategy field of the TuningCriterion should be specified with mse.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(strategy="mse"),
)
MSE_V2
Design
MSE_v2 is a strategy with a two stages fallback and revert fallback. In the fallback stage, it uses multi-batch data to score the op impact and then fallback the op with the highest score util found the quantized model meets accuracy criteria. In the revert fallback stage, it also scores the impact of fallback OPs in the previous stage and selects the op with the lowest score to revert the fallback until the quantized model not meets accuracy criteria.
Usage
To use the MSE_V2 tuning strategy, the strategy field in the TuningCriterion should be specified with mse_v2. Also, the confidence_batches can be specified optionally inside the strategy_kwargs for the number of batches to score the op impact. Increasing confidence_batches will generally improve the accuracy of the scoring with more time spent in tuning process.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(
strategy="mse_v2",
strategy_kwargs={"confidence_batches": 2}, # optional. the number of batches to score the op impact.
),
)
HAWQ_V2
Design
HAWQ_V2 implements the Hessian Aware trace-Weighted Quantization of Neural Networks. We made a small change to it by using the hessian trace to score the op impact and then fallback the OPs according to the scoring result.
Usage
To use the HAWQ_V2 tuning strategy, the strategy field in the TuningCriterion should be specified with hawq_v2, and the loss function for calculating the hessian trace of model should be provided. The loss function should be set in the field of hawq_v2_loss in the strategy_kwargs.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
def model_loss(output, target, criterion):
return criterion(output, target)
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(
strategy="hawq_v2",
strategy_kwargs={"hawq_v2_loss": model_loss}, # required. the loss function for calculating the hessian trace.
),
)
Bayesian
Design
Bayesian optimization is a sequential design strategy for the global
optimization of black-box functions. This strategy comes from the Bayesian
optimization package and
changed it to a discrete version that complied with the strategy standard of
Intel® Neural Compressor. It uses Gaussian processes to define
the prior/posterior distribution over the black-box function with the tuning
history and then finds the tuning configuration that maximizes the expected
improvement. For now, Bayesian just focus on op-wise quantization configs tuning
without the fallback phase. In order to obtain a quantized model with good accuracy
and better performance in a short time. We don’t add datatype as a tuning
parameter into Bayesian.
Usage
For the Bayesian strategy, it is recommended to set timeout or max_trials to a non-zero
value as shown in below example, because the param space for bayesian can be very small and the accuracy goal might not be reached, which can make the tuning end never. Additionally, if the log level is set to debug by LOGLEVEL=DEBUG in the environment variable, the message [DEBUG] Tuning config was evaluated, skip! will print endlessly. If the timeout is changed from 0 to an integer, Bayesian ends after the timeout is reached.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(
timeout=0, # optional. tuning timeout (seconds). When set to 0, early stopping is enabled.
max_trials=100, # optional. max tuning times. combined with the `timeout` field to decide when to exit tuning.
strategy="bayesian",
),
)
Exhaustive
Design
The Exhaustive strategy is used to sequentially traverse all possible tuning
configurations in a tuning space. From the perspective of the impact on
performance, we currently only traverse all possible quantization tuning
configs. Same reason as Bayesian, fallback datatypes are not included for now.
Usage
Exhaustive usage is similar to basic, with exhaustive specified to strategy field in the TuningCriterion.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(
strategy="exhaustive",
),
)
Random
Design
Random strategy is used to randomly choose tuning configurations from the
tuning space. As with the Exhaustive strategy, it also only considers quantization
tuning configs to generate a better-performance quantized model.
Usage
Random usage is similar to basic, with random specified to strategy field in the TuningCriterion.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(
strategy="random",
),
)
SigOpt
Design
SigOpt strategy is to use SigOpt Optimization Loop method to accelerate and visualize the traversal of the tuning configurations from the tuning space. The metrics add accuracy as a constraint and optimize for latency to improve performance. SigOpt Projects can show the result of each tuning experiment.
Usage
Compared to Basic, sigopt_api_token and sigopt_project_id are necessary for SigOpt.
For details, how to use sigopt strategy in neural_compressor is available.
Note that the sigopt_api_token, sigopt_project_id, and sigopt_experiment_name should be set inside the strategy_kwargs.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(
strategy="sigopt",
strategy_kwargs={
"sigopt_api_token": "YOUR-ACCOUNT-API-TOKEN",
"sigopt_project_id": "PROJECT-ID",
"sigopt_experiment_name": "nc-tune",
},
),
)
TPE
Design
TPE uses sequential model-based optimization methods (SMBOs). Sequential refers to running trials one after another and selecting a better
hyperparameter to evaluate based on previous trials. A hyperparameter is
a parameter whose value is set before the learning process begins; it
controls the learning process. SMBO apples Bayesian reasoning in that it
updates a surrogate model that represents an objective function
(objective functions are more expensive to compute). Specifically, it finds
hyperparameters that perform best on the surrogate and then applies them to
the objective function. The process is repeated and the surrogate is updated
with incorporated new results until the timeout or max trials is reached.
A surrogate model and selection criteria can be built in a variety of ways.
TPE builds a surrogate model by applying Bayesian reasoning. The TPE
algorithm consists of the following steps:
Define a domain of hyperparameter search space.
Create an objective function that takes in hyperparameters and outputs a score (e.g., loss, RMSE, cross-entropy) that we want to minimize.
Collect a few observations (score) using a randomly selected set of hyperparameters.
Sort the collected observations by score and divide them into two groups based on some quantile. The first group (x1) contains observations that give the best scores and the second one (x2) contains all other observations.
Model the two densities l(x1) and g(x2) using Parzen Estimators (also known as kernel density estimators), which are a simple average of kernels centered on existing data points.
Draw sample hyperparameters from l(x1). Evaluate them in terms of l(x1)/g(x2), and return the set that yields the minimum value under l(x1)/g(x1) that corresponds to the greatest expected improvement. Evaluate these hyperparameters on the objective function.
Update the observation list in step 3.
Repeat steps 4-7 with a fixed number of trials.
Note: TPE requires many iterations in order to reach an optimal solution. It is recommended to run at least 200 iterations, because every iteration requires evaluation of a generated model, which means accuracy measurements on a dataset and latency measurements using a benchmark. This process may take from 24 hours to a few days to complete, depending on the model.
Usage
TPE usage is similar to basic with tpe specified to strategy field in the TuningCriterion.
from neural_compressor.config import PostTrainingQuantConfig, TuningCriterion
conf = PostTrainingQuantConfig(
quant_level=1,
tuning_criterion=TuningCriterion(strategy="tpe"),
)
The next_tune_cfg function is used to yield the next tune configuration according to some algorithm or strategy. TuneStrategy base class will traverse all the tuning space till a quantization configuration meets the pre-defined accuracy criterion.
The traverse function can be overridden optionally if the traverse process required by the new strategy is different from the one TuneStrategy base class implemented.
An example of customizing a new tuning strategy can be reached at TPE Strategy.
Distributed Tuning
Design
Intel® Neural Compressor provides distributed tuning to speed up the tuning process by leveraging the multi-node cluster. It seamlessly parallelizes the tuning process across multi nodes by using the MPI. In distributed tuning, the fp32 model is replicated on every node, and each original model replica is fed with a different quantization configuration. The master handler coordinates the tuning process and synchronizes the tuning result of each stage to every slave handler. The distributed tuning allows the tuning process to scale up significantly to the number of nodes, which translates into faster results and more efficient utilization of computing resources.
The diagram below provides an overview of the distributed tuning process.
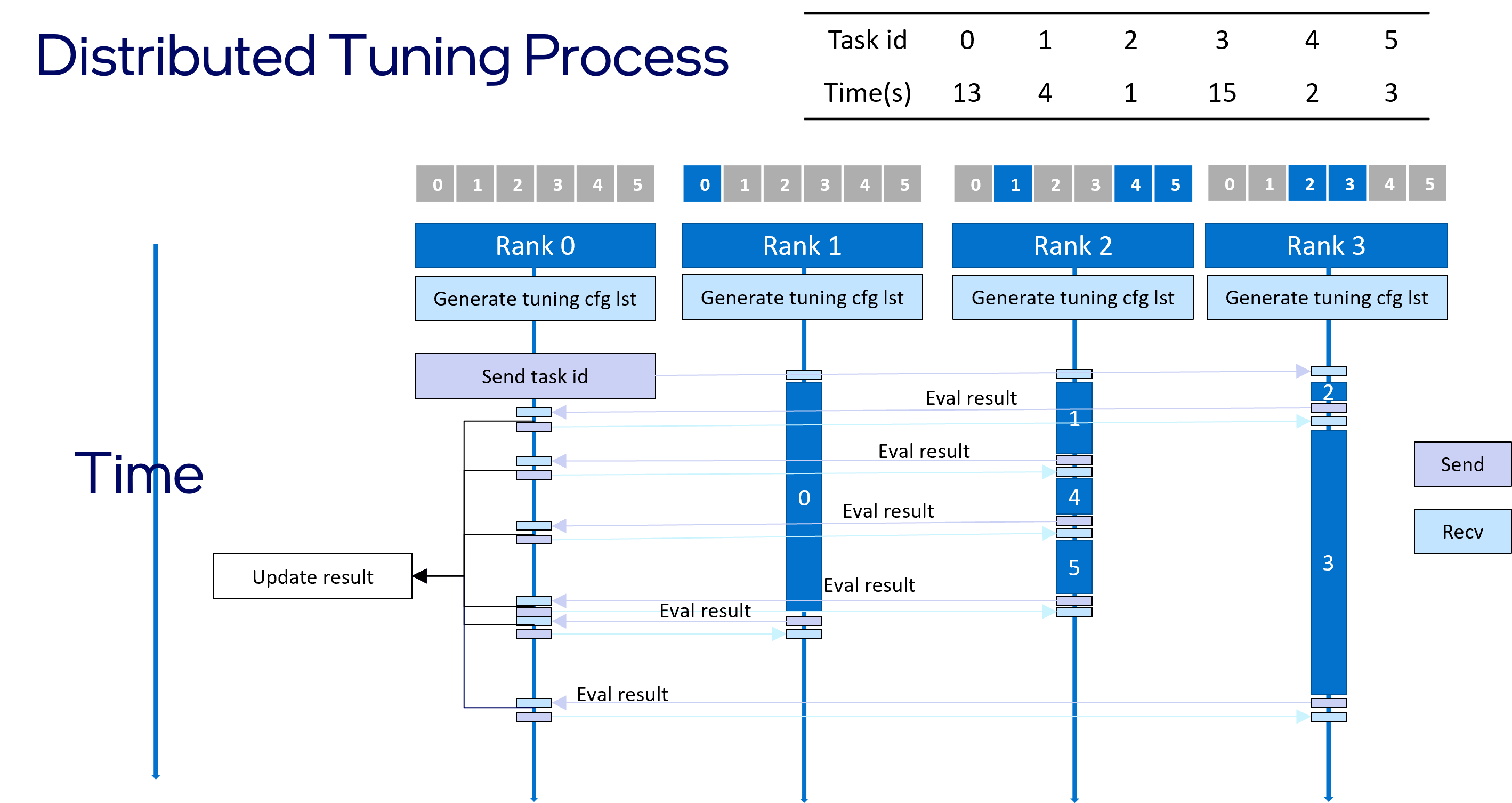
Usage
To use Distributed Tuning, the number of processes should be specified to be greater than 1.
mpirun -np <number_of_processes> <RUN_CMD>
An example of distributed tuning can be reached at ptq_static_mrpc.
Customize a New Tuning Strategy
Intel® Neural Compressor supports new strategy extension by implementing a sub-class of the TuneStrategy class in neural_compressor.strategy package and registering it by the strategy_registry decorator.
For example, user can implement an Abc strategy like below:
@strategy_registry
class AbcTuneStrategy(TuneStrategy):
def __init__(self, model, conf, q_dataloader, q_func=None, eval_dataloader=None, eval_func=None, dicts=None): ...
def next_tune_cfg(self):
# generate the next tuning config
...
def traverse(self):
for tune_cfg in self.next_tune_cfg():
# do quantization
...