Distillation
-
1.1 Distillation
-
2.1 Pytorch Script
2.3 Create an Instance of Metric
2.4 Create an Instance of Criterion(Optional)
Introduction
Distillation
Distillation is a widely-used approach to perform network compression, which transfers knowledge from a large model to a smaller one without significant loss of validity. As smaller models are less expensive to evaluate, they can be deployed on less powerful hardware (such as a mobile device). Graph shown below is the workflow of the distillation, the teacher model will take the same input that feed into the student model to produce the output that contains knowledge of the teacher model to instruct the student model.
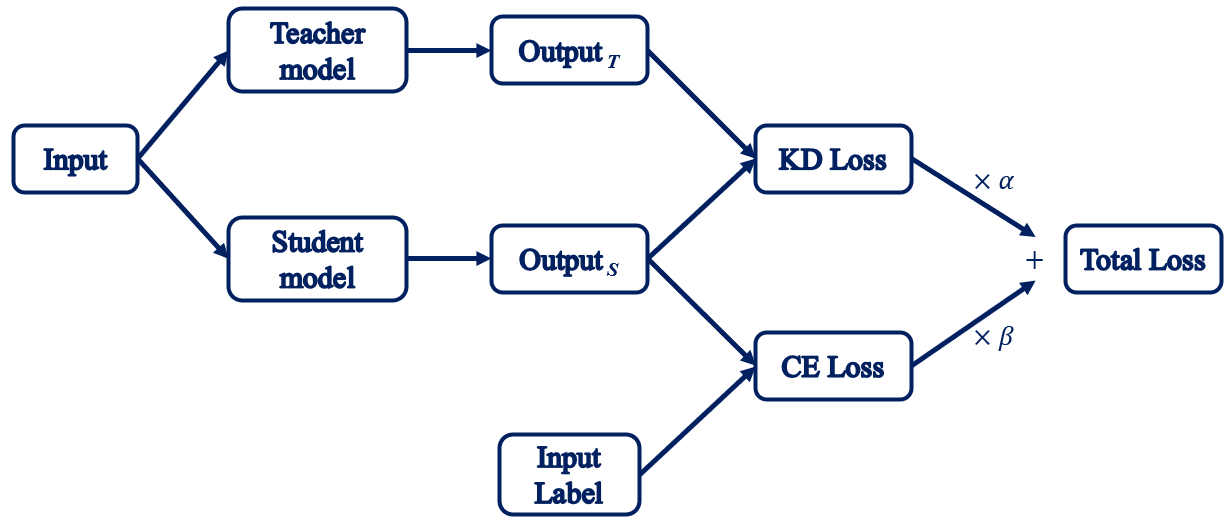
Knowledge Distillation
Knowledge distillation is proposed in Distilling the Knowledge in a Neural Network. It leverages the logits (the input of softmax in the classification tasks) of teacher and student model to minimize the the difference between their predicted class distributions, this can be done by minimizing the below loss function.
$$L_{KD} = D(z_t, z_s)$$
Where $D$ is a distance measurement, e.g. Euclidean distance and Kullback–Leibler divergence, $z_t$ and $z_s$ are the logits of teacher and student model, or predicted distributions from softmax of the logits in case the distance is measured in terms of distribution.
Intermediate Layer Knowledge Distillation
There are more information contained in the teacher model beside its logits, for example, the output features of the teacher model’s intermediate layers often been used to guide the student model, as in Patient Knowledge Distillation for BERT Model Compression and MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices. The general loss function for this approach can be summarized as follow.
$$L_{KD} = \sum\limits_i D(T_t^{n_i}(F_t^{n_i}), T_s^{m_i}(F_s^{m_i}))$$
Where $D$ is a distance measurement as before, $F_t^{n_i}$ the output feature of the $n_i$’s layer of the teacher model, $F_s^{m_i}$ the output feature of the $m_i$’s layer of the student model. Since the dimensions of $F_t^{n_i}$ and $F_s^{m_i}$ are usually different, the transformations $T_t^{n_i}$ and $T_s^{m_i}$ are needed to match dimensions of the two features. Specifically, the transformation can take the forms like identity, linear transformation, 1X1 convolution etc.
usage
Pytorch Script:
from intel_extension_for_transformers.transformers.trainer import NLPTrainer
from neural_compressor.config import DistillationConfig
# Replace transformers.Trainer with NLPTrainer
# trainer = transformers.Trainer(......)
trainer = NLPTrainer(......)
metric = metrics.Metric(name="eval_accuracy")
trainer.metrics = metric
d_conf = DistillationConfig(teacher_model=teacher_model, criterion=criterion)
model = trainer.distill(distillation_config=d_conf)
Please refer to example for the details.
Create an Instance of Metric
The Metric defines which metric will be used to measure the performance of tuned models.
example:
metric = metrics.Metric(name="eval_accuracy")
Please refer to metrics document for the details.
Create an Instance of Criterion(Optional)
The criterion used in training phase.
KnowledgeDistillationLossConfig arguments: |Argument |Type |Description |Default value | |:———-|:———-|:———————————————–|:—————-| |temperature|Float |parameter for KnowledgeDistillationLoss |1.0 | |loss_types|List of string|Type of loss |[’CE’, ‘CE’] | |loss_weight_ratio|List of float|weight ratio of loss |[0.5, 0.5] |
IntermediateLayersKnowledgeDistillationLossConfig arguments: |Argument |Type |Description |Default value | |:———-|:———-|:———————————————–|:—————-| |loss_types|List of string|Type of loss |[’CE’, ‘CE’] | |loss_weight_ratio|List of float|weight ratio of loss |[0.5, 0.5] | |layer_mappings|List|parameter for IntermediateLayersLoss |[] | |add_origin_loss|bool|parameter for IntermediateLayersLoss |False |
example:
criterion = KnowledgeDistillationLossConfig()
Create an Instance of DistillationConfig
The DistillationConfig contains all the information related to the model distillation behavior. If you created Metric and Criterion instance, then you can create an instance of DistillationConfig. Metric and pruner_config is optional.
arguments: |Argument |Type |Description |Default value | |:———-|:———-|:———————————————–|:—————-| |teacher_model |torch.nn.Module | teacher model object |None | |criterion|Criterion |criterion of training |KnowledgeLoss object|
example:
d_conf = DistillationConfig(teacher_model=teacher_model, criterion=criterion)
Distill with Trainer
Distill with Trainer NLPTrainer inherits from transformers.Trainer, so you can create a trainer as in examples of Transformers. Then you can distill model with trainer.distill function.
model = trainer.distill(distillation_config=d_conf)