Intel® Trust Domain Extension Linux Guest Kernel Security Specification¶
Contributors:
Andi Kleen, Elena Reshetova
Purpose and Scope¶
This document describes the security architecture of the Linux guest kernel running inside the TDX guest.
The main security goal of Intel® Trust Domain Extension (Intel® TDX) technology is to remove the need for a TDX guest to trust the host and virtual machine manager (VMM). It is important to note that this security objective is not unique to the TDX architecture, but it is common across all confidential cloud computing solutions (CCC) (such as TDX, AMD SEV, etc) and therefore many aspects described below will be applicable to other CCC technologies.
Threat model¶
The Trusted Computing Base (TCB) for the Linux TDX SW stack shown in Figure 1 includes the Intel platform, the TDX module, and the SW stack running inside the TDX guest.
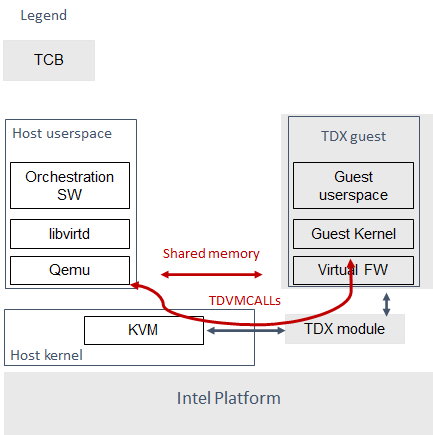
Figure 1. Linux TDX 1.0 SW stack¶
The major security objectives of the TDX guest kernel security architecture are to help to prevent privilege escalation as well as kernel data confidentiality/integrity violations by the untrusted VMM. The denial-of-service (DoS) attacks towards the TDX guest kernel is out of scope here since the TDX guest resources are fully under the control of the VMM and are able to perform DoS towards the TDX guest by default.
The TDX module and the Intel platform help ensure the protection of the TDX guest memory and registers. However, they cannot protect the TDX guest from host/VMM attacks that leverage existing communication interfaces between the host/VMM and the guest:
TDVMCALL hypercalls (through the TDX-module)
Shared memory for IO
The primary goal of the security architecture described below is to help to protect the TDX Linux guest kernel from attacks from the hypervisor through these communication interfaces. Additionally, there should not be any new additional attack vectors introduced towards the TDX Linux guest kernel (ring 0) from the TDX guest userspace (ring 3). The TDX guest userspace is omitted from the scope of this threat model. The threat model does not address any threats made possible by the TDX guest userspace directly using the above-mentioned interfaces exposed to an untrusted host/VMM. For example, if the TDX guest userspace enables debug or test tools that perform MMIO or pci config space reading on their own but do not carefully validate the input that comes from untrusted host/VMM, many additional attacks are possible. This threat model also assumes the KVM/Qemu to be the hypervisor running the protected TDX guest. As a result, other hypervisors and their hardening are also out of the scope of this document. Another potential attack vector that is not covered by this threat model is abusing the Linux kernel printout and debug routines that can now take parameters directly from the untrusted host/VMM.
The overall threat mitigation matrix is shown in Table below.
Threat name |
Threat description |
Mitigation mechanisms |
Links to detailed description |
|---|---|---|---|
(NRDD) Non-robust device drivers |
Malicious input (MSR, CPUID, PCI config space, PortIO, MMIO, SharedMemory/DMA, KVM Hypercalls) is consumed from the host/VMM by a non-harden device driver that results in a host/VMM -> guest kernel privilege escalation |
|
|
(NRDDI/L) Non-robust device driver’s __init function or legacy non-robust driver |
The device filter does not prevent driver initialization function from executing. For 5.15 kernel there are 198 unique __init functions with 5198 unique code locations that can consume a malicious input (MSR,CPUID, PCI config space, PortIO, MMIO, KVM hypercalls) from host/VMM that can result in a host/VMM -> guest kernel privilege escalation. |
|
|
(NRCKC) Non-robust core kernel code |
Malicious input (MSR,CPUID, PCI config space, PortIO, MMIO, SharedMemory/DMA, KVM Hypercalls) is consumed from the host/VMM by a core Linux code that results in a host/VMM -> guest kernel privilege escalation |
|
|
(HCSG) Host/VMM controlled Spectre v1 gadget |
Host/VMM uses a spectre v1 gadget conditioned on the host/VMM controlled input (MSR,CPUID, PCI config space, PortIO, MMIO, SharedMemory/DMA, KVM Hypercalls) and uses that to break confidentiality of the guest VM |
|
|
(NRAA) Non-robust AML interpreter or ACPI code |
Malicious input is consumed from the host/VMM via an ACPI table (provided by the host/VMM via TDVF virtual FW) that results in a host/VMM -> guest kernel privilege escalation |
|
|
(HCR) Host/VMM controlled randomness |
Host/VMM can observe or affect the state of Linux RNG guest kernel (due to interrupts being the main default source of entropy) and break cryptographic security of all guest mechanisms consuming RNG output |
Enforce addition of entropy using RDRAND/RDSEED and avoid fallbacks to insecure jiffies |
|
(HCT) Host/VMM controlled time |
Host/VMM can modify/affect the time visible inside TDX guest and break security of all guest mechanisms depending on a secure time (rollback prevention, etc.) |
Disable all mechanisms for the host/VMM to affect guest time. Only rely on TSC timer, which is guaranteed by TDX module |
|
|
Host/VMM can inject an interrupt into the guest with malicious inputs |
Injecting interrupts (via posted-interrupt mechanism) is not allowed for exception vectors 0-30. NMI injection is possible with the assistance of TDX module |
|
(LIPC/P) Lost IPIs/reliable panic |
Host/VMM can drop IPIs between vcpus on the guest and as a result attempt to cause some unexpected behavior in guest |
Code audit on consequences of lost IPIs (no findings so far). Panic seems to be safe. |
N/A |
TDX Linux guest kernel overall hardening methodology¶
Document Intel® Trust Domain Extension Guest Linux Kernel Hardening Strategy describes the hardening methodology that is used to perform systematic audits and fuzzing of the communication interfaces exposed to the malicious hypervisor. This document covers the kernel subsystems that are relevant to the described threat model and provides details on their hardening principles. The overall security principle is that in case of any corruption event, the safest default option is to raise the kernel panic.
Device filter mechanism¶
As stated above, the primary goal of the security architecture described in this document is to help protecting the TDX Linux guest kernel from hypervisor attacks through TDVMCALL or shared memory communication interfaces. The detailed description of when these interfaces are used in TDX guest kernel can be found below in the section TDVMCALL-hypercall-based communication interfaces, but our analysis of the kernel code has shown that the biggest users of such interfaces are device drivers (more than 95%). Every time a driver performs a port IO or MMIO read, access a pci config space or reads values from MSRs or CPUIDs, there is a possibility for a malicious hypervisor to inject a malformed value.
Fortunately, only a small subset of device drivers are required for the TDX guest operation (for Linux TDX SW reference stack it is a subset of virtio drivers described in VirtIO and shared memory), so most of the attack surface can be disabled by creating a small list of allowed device drivers. This is the main goal of the guest runtime device filter. It allows to define an allow or deny list for device drivers and prevents non-authorized device driver’s probe functions from running (note: driver’s init functions are able to execute). It also automatically sets to ‘shared’ the MSI mailboxes and MMIO mappings of the authorized device drivers, if the latter ones are created using pci_iomap_* or devm_ioremap* interfaces. For MMIO mappings created using plain ioremap_* style interface, a driver code needs to be modified to either use the above mentioned pci_iomap_*/devm_ioremap* interfaces or a new ioremap_driver_hardened interface that manually sets the mapping to ‘shared’ also.
Additionally when device filter is enabled (see section Kernel command line on how it can be disabled for debug purpose from the command line), there are other security mechanisms that are enabled for the TDX guest Linux kernel, namely Port IO filter is active (see section IO ports for details), ACPI table allow list is enforced (see section BIOS-supplied ACPI tables and mappings for details) and pci config space access from non-authorized device drivers is limited (see section PCI config space for details). If disabling of the device filter or associated mechanisms is desired for debug purpose, please consult section Kernel command line on how to change configuration of these mechanisms using command line, i.e. modify allow/deny list of the device filter, modify the list of allowed ACPI tables, etc.
Device passthrough¶
In some deployment models it might be desirable to enable a device passthrough for a TDX guest. In the current TDX 1.0 model, it is only possible via the usage of a shared memory, i.e. it is not possible to let the devices to access the TDX guest private memory. As a result, when a new passthrough device is being enabled for a TDX guest, the corresponding device driver in the TDX guest must be authorised to run by the device filter mechanism and its MMIO pages must be mapped as shared for the communication to happen. This can be done using the following kernel command attribute: authorize_allow_devs=pci:<ven_id:dev_id>. However, based on the type of the interface that device driver uses to create the MMIO mappings, it might not be possible to automatically share these pages with the host:
If device driver uses devm_ioremap*() or pci_iomap*()-style interfaces, the sharing works fine
If device driver uses a legacy ioremap*()-style interfaces, the sharing won’t work and the corresponding device driver must be changed to either use the above interfaces or alternatively a dedicated ioremap_driver_hardening() interface that explicitly indicates that an MMIO mapping must be shared with the host
Similar to a non-passthrough case, any device driver enabled in the TDX guest using the above mechanism must be hardened to withstand the attacks from hypervisor through TDVMCALL or shared memory communication interfaces. Moreover, since the device passthrough for TDX 1.0 is using shared memory, any data placed in this memory can be manipulated by the host/hypervisor and must be protected where possible using application-level security mechanisms, such as encryption and authentication.
TDVMCALL-hypercall-based communication interfaces¶
TDVMCALLs are used to communicate between the TDX guest and the host/VMM. The host/VMM can try to attack the TDX guest kernel by supplying a maliciously crafted input as a response to a TDVMCALL. While TDVMCALLs are proxied via the TDX module, only a small portion of them (mainly some CPUIDs and MSRs) are controlled and enforced by the TDX module. Most of the TDVMCALLs are passed through and their values are controlled by the host/VMM. Instead of inserting the TDVMCALL directly in many code paths within the guest kernel, a #VE handler is used as a primary centralized TDVMCALL invocation place. However, for some cases TDVMCALL can be also invoked directly to boost the performance for a certain hot code path. The #VE handler is invoked by the TDX module for the actions it cannot handle. The #VE handler either decodes the executed instruction (using the standard Linux x86 instruction decoder) and converts it into a TDVMCALL or rejects it (panic). The implementation of the #VE handler is simple and does not require an in-depth security audit or fuzzing since it is not the actual consumer of the host/VMM supplied untrusted data. However, it does implement a simple allow list for the port IO filtering (see IO ports ).
MMIO¶
MMIO is controlled by the untrusted host and handled through #VE for most cases, or a special fast path through pci iomap for performance-critical cases. The instructions in the kernel are trusted. The #VE handler will decode a subset of instructions using the Linux instruction decoder. We only care about users that read from MMIO.
Kernel MMIO¶
By default, all MMIO regions reside in the TDX guest private memory are not accessible to the host/VMM. To explicitly share a MMIO region, the device must be authorized through the device filter framework, enabling MMIO operations. The handling of the MMIO input from the untrusted host/VMM must be hardened (see Intel® Trust Domain Extension Guest Linux Kernel Hardening Strategy for more information).
The static code analysis tool should generate a list of all MMIO users based on use of the standard io.h macros. All portable code should use these macros. The only known exception to this is the legacy MMIO APIC direct accesses, which is disabled (see Interrupt handling and APIC ).
Open: there might be other non-portable (x86-specific) code that does not use the io.h macros, but directly accesses IO mappings. Sparse should be able to find those using the __iomem annotations.
User MMIO¶
In the current Linux implementation user MMIO is not supported and results in SIGSEGV. Therefore, it cannot be used to attack the kernel (other than DoS).
Interrupt handling and APIC¶
TDX guest must use virtualized x2APIC mode. Legacy xAPIC (using MMIO) is disabled via special checks in the guest’s kernel APIC code, as well as enforced by the TDX module.
The x2APIC MSRs are either proxied through the TDVMCALL hypercall (and handled by the untrusted hypervisor) or handled as access to a VAPIC page. The later ones are considered trusted, but the first group requires hardening similar as untrusted MSR access described in MSRs proxied through TDVMCALL and controlled by host. For the detailed description on specific x2APIC MSR behavior please see section 10.9 in Intel TDX module architecture specification.
Untrusted VMM can inject both non-NMI interrupts (via posted-interrupt mechanism) or NMI interrupts. However, TDX module does not allow VMM injecting interrupt vectors in range 0-30 via posted-interrupt mechanism, which drastically reduces the exposed attack surface towards the untrusted VMM. The rest of above interrupts are considered controlled by the host and therefore the guest kernel code that handles them must be audited and fuzzed as any other code that receives malicious host input.
IPIs are initiated by triggering TDVMCALL on the x2APIC ICR MSRs. The host controls the delivery of the IPI, so IPIs might get lost. We need to make sure all missing IPIs result in panics or stop the operation (in case the timeout is controlled by the host). This should be already handled by the normal timeout in smp_call_function*().
PCI config space¶
The host controls the PCI config space, so in general, any PCI config space reads are untrusted. Apart from hardening the generic PCI code, there is a special pci config space filter that prevents random initcalls from accessing the PCI config space of unauthorized devices not allowed by the device filter. The config space filter is implemented by setting unauthorized devices to the “errored” state, which prevents any config space accesses.
Inside Linux, the PCI config space is used by several entities:
PCI subsystem for probing drivers¶
The PCI subsystem enumerates all PCI devices through PCI config space. The host owns the config space, which is untrusted. We only support probing through CF8 and disable MCFG config space via the ACPI table allow list. This implies that only the first 256 bytes are supported for now. The core PCI subsystem code has been hardened via code audit and fuzzing described in Intel® Trust Domain Extension Guest Linux Kernel Hardening Strategy.
Allocating resources¶
The kernel can allocate resources such as MMIO for pci bridges or drivers based on the information coming from the untrusted pci config space supplied by the host/VMM. Therefore, this allocation process needs to be verified to withstand the potential malicious input. As a result, the code in the core pci subsystem, as well as enabled virtio drivers have been audited and fuzzed using the techniques described in Intel® Trust Domain Extension Guest Linux Kernel Hardening Strategy. Specifically, we paid attention to make sure that the allocated resource regions do not overlap with each other or with the rest of the TD guest memory.
Drivers¶
All allow-listed drivers need to be audited and fuzzed for all pci config space interactions they have with the host. Initially this is only a very small list of virtio devices (see VirtIO and shared memory).
User programs accessing PCI config space¶
User programs can access PCI devices directly through sysfs or /dev/mem. This could be an attack vector if the user program has an exploitable hole in parsing PCI config space or MMIO. If the user programs are using the Linux-supplied PCI enumeration (/sys/bus/pci), the PCI device allow list will protect user programs to some degree. But it won’t protect programs that try to directly access devices that are on the allow list (like virtio devices).
It’s also possible, for userspace programs to access the PCI config space directly through CF8 port IO using operm/iopl() or direct read() on /dev/port. The former case will be filtered in the TDX guest kernel #VE handler, because the handler does not forward port IO requests to an untrusted VMM if the request came from a userspace. The latter case (direct read on /dev/port) however is not going to be limited by the #VE handler and a userspace program that performs this operation should be prepared to handle untrusted input from a VMM securely. PCI config space access through MMIO for userspace programs is not possible inside TDX guest since PCIe MCFG config space is disabled for TDX guest and normal PCI config space is not mapped to MMIO address space.
MSRs¶
Nearly all MSRs used by the kernel for x86 are listed in arch/x86/include/asm/msr-index.h, but might have aliases and ranges. Some additional MSRs are in arch/x86/include/asm/perf_event.h, arch/x86/kernel/cpu/resctrl/internal.h, and arch/x86/kernel/cpu/intel.c
MSRs controlled by TDX module¶
There are two types of MSRs that are controlled by the TDX module:
Passthrough MSRs (direct read/write from the CPU, for example side channel related MSRs, such as ARCH_CAPABILITIES)
Disallowed MSRs that result in #GP upon attempt to read/write such an MSR (for example, all IA32_VMX_* KVM MSRs).
All these MSRs are controlled by the platform, are trusted, and do not require any hardening. See section 18.1 in Intel TDX module architecture specification for the exact list.
MSRs proxied through TDVMCALL and controlled by host¶
Access to these MSRs typically results in a #VE event inserted by the TDX module back to the TDX guest, and the TDX guest kernel #VE handler invoking the TDVMCALL hypercall to the untrusted VMM to obtain/set these MSR values. In some cases for performance reasons the TDVMCALL hypercall is invoked directly from TDX guest kernel to avoid an additional context switch to the TDX module. All these MSRs are considered untrusted and their handling in the TDX guest kernel must be hardened, i.e., audited and fuzzed using the methodology described in Intel® Trust Domain Extension Guest Linux Kernel Hardening Strategy.
Based on our fuzzing and auditing activities, the risk for the memory safety issues based on MSR values is considered to be low, since most of the MSRs are handled via masking individual MSR bits, i.e., saving and restoring MSR bit values. However, some MSRs control rather complex functionality, such as IA32_MC*, IA32_MTRR_*, IA32_TME_*. We have disabled most of such features to minimize the exposed attack surface via clearing the following feature bits during TDX guest early initialization: X86_FEATURE_MCE, X86_FEATURE_MTRR, X86_FEATURE_TME. For the full up-to-date list, please check tdx_early_init() function. Should these feature need to be enabled, a detailed code audit and fuzzing approach must be used to ensure the respective code is hardened.
IO ports¶
IO ports are controlled by the host and could be an attack vector.
All IO port accesses go through #VE or direct TDVMCALLs. We’ll use a small allow list of trusted ports. This helps to prevent the host from trying to inject old ISA drivers that use port probing and might have vulnerabilities processing port data. While normally these cannot be auto loaded, they might be statically compiled into kernels and would do standard port probing.
The most prominent user is the serial port driver. Using the serial port (e.g. for early console) requires disabling security. In the secure mode we only have the virtio console.
The table below shows the allow list ports in the current TDX guest kernel:
Port range |
Intended user |
Comments |
|---|---|---|
0x70 … 0x71 |
MC146818 RTC |
|
0xcf8 … 0xcff |
PCI config space |
Ideally this range should be further limited since likely not being needed in full |
0x600 … 0x62f |
ACPI ports |
0600-0603 : ACPI PM1a_EVT_BLK 0604-0605 : ACPI PM1a_CNT_BLK 0608-060b : ACPI PM_TMR 0620-062f : ACPI GPE0_BLK |
0x3f8, 0x3f9,0x3fa, 0x3fd |
COM1 serial |
Only in debugmode |
IO port accesses for the TDX guest userspace (ring 3) are not supported and results in SIGSEGV.
KVM CPUID features and Hypercalls¶
For various performance enhancements KVM provides a number of PV features towards its guests that are enumerated via KVM CPUIDs. Some of these features define respected KVM hypercalls, and some are using other means for communication: MSRs, memory structures, etc. Each of such features is under full control of the host and should be considered untrusted. KVM hypercalls are proxied through TDVMCALL in TDX case. For the full list of KVM features and hypercalls please consult KVM CPUIDs and KVM hypercalls description .
Based on our security analysis (see Security implications from KVM PV features for more information), only the KVM_FEATURE_CLOCKSOURCE(2) CPUIDs should be explicitly disabled in the guest kernel, since it would allow the guest to rely on host-controlled kvmclock for providing the timing information. The disabling can be done via “no-kvmclock” guest kernel cmdline option. The rest of features do not require explicit disabling, because they either considered not to have any security implications towards the TDX guest (apart from DoS) or already indirectly disabled (KVM_FEATURE_ASYNC_PF, KVM_FEATURE_PV_EOI, KVM_FEATURE_STEAL_TIME) because the required memory structures are not shared between the host and the guest.
CPUID¶
Reading untrusted CPUIDs could be used to let the guest kernel execute non-hardened code paths. The TDX module ensures that most CPUID values are trusted (see section 18.2 in Intel TDX module architecture specification), but some are configurable via the TD_PARAMS structure or can be provided by the untrusted host/VMM via the logic implemented in the #VE handler.
Since the TD_PARAMS structure is measured into TDX measurement registers and can be attested later, the CPUID bits that are configured using this structure can be considered trusted.
The table below lists the CPUID leaves that result in a #VE inserted by the TDX module.
Cpuid Leaf |
Purpose |
Comment |
|---|---|---|
0x2 |
Cache & TLB info |
Obsolete leaf, code will prefer CPUID 0x4 which is trusted |
0x5 |
Monitor/Mwait |
|
0x6 |
Thermal & Power Mgmt |
|
0x9 |
Direct cache access info |
|
0xb |
Extended topology enumeration |
|
0xc |
Reserved |
Not used in Linux |
0xf |
Platform QoS monitoring |
Explicitly disabled in TDX guest via clearing X86_FEATURE_CQM_LLC feature bit |
0x10 |
Platform QoS Enforcement |
Explicitly disabled in TDX guest via clearing X86_FEATURE_MBA feature bit |
0x16 |
Processor frequency |
The only user of this cpuid in the TDX guest is cpu_khz_from_cpuid, but the TDX guest code has been changed to first use cpuid leaf 0x15 which is guaranteed by the TDX module |
0x17 |
SoC Identification |
|
0x18 |
TLB Deterministic Parameters |
|
0x1a |
Hybrid Information |
|
0x1b |
MK TME |
Explicitly disabled in TDX guest via clearing X86_FEATURE_TME feature bit |
0x1f |
V2 Extended Topology Enumeration |
|
0x80000002-4 |
Processor Brand String |
|
0x80000005 |
Reserved |
|
0x80000006 |
Cache parameters |
|
0x80000007 |
AMD Advanced Power Management |
|
0x40000000- 0x400000FF |
Reserved for SW use |
Most of the above CPUID leaves result in different feature bits and therefore are harmless. The ones that have larger fields have been audited and fuzzed in the same way as other untrusted inputs from the hypervisor. In addition, it is also possible to sanitize multi-bit CPUIDs against the bounds expected for a given platform.
However, to strengthen security even further, the #VE handler in TDX guest kernel has been recently modified to only allow leaves in the range 0x40000000 - 0x400000FF to be requested from the untrusted host/VMM. If SW inside TDX guest tries to read any other leaf from the above table, the value of 0 is returned.
Going forward TDX module introduced a new TDX guest feature, called REDUCE_VE (for details consult latest Intel TDX module architecture specification). If this feature is enabled by the TDX guest, all CPUID leaves from the above table except the reserved ones (0x80000005, 0x40000000- 0x400000FF) won’t result in a #VE insertion and will contain the values predefined or calculated by TDX module and therefore can be considered trusted. This helps reduce the issues resulting from #VE Linux kernel handler returning the value of “0” on these leaves.
Perfmon¶
For CPUID, see `KVM CPUID`_ above.
For MSR, see MSRs .
The uncore drivers are explicitly disabled with a hypervisor check, since they generally don’t work in virtualization of any kind. This includes the architectural Chassis perfmon discovery, which works using MMIO.
IOMMU¶
IOMMU is disabled for the TDX guest due to the DMAR ACPI table not being included in the list of allowed ACPI tables for the TDX guest. Similar for the AMD IOMMU. The other IOMMU drivers should not be active on x86.
Randomness inside TDX guest¶
Linux RNG¶
The Linux RNG uses timing from interrupts as the default entropy source; this can be a problem for the TDX guest because timing of the interrupts is controlled by the untrusted host/VMM. However, on x86 platforms there is another entropy source that is outside of host/VMM control: RDRAND/RDSEED instructions. The commit x86/coco: Require seeding RNG with RDRAND on CoCo systems ensures that a TDX guest cannot boot unless 256 bits of RDRAND output is mixed into the entropy pool early during the boot process.
TSC and other timers¶
TDX has a limited secure time with the TSC timer. The TSC inside a TD is guaranteed to be synchronized and monotonous, but not necessarily matching real time. A guest can turn it into truly secure wall time by using a remote authenticated time server. This is the recommended way of obtaining the secure time inside a TDX guest. In the absence of a remote authenticated server, TDX guest gets the time from Linux RTC. However, Linux RTC has not yet been hardened and its usage presents a potential security threat.
By default, for the KVM hypervisor, kvmclock would have priority, which is not secure anymore because it uses untrusted input from the host. To avoid this the kvmclock must be disabled by using ‘no-kvmclock’ cmdline option (command line is measured and can be attested). Additionally, the TSC watchdog is also disabled (by forcing the X86_FEATURE_TSC_RELIABLE bit) to avoid the possible fallback to jiffy time, which could be influenced by the host by changing the frequency of the timer interrupts.
The TSC deadline timer inside the TDX guest is not secure and fully under the control of host/VMM. The TSC deadline feature enumeration (CPUID(1).ECX[24]) inside the TDX guest reports the platform native value, but the TDX guest kernel reads or writes to MSR_IA32_TSC_DEADLINE will result in a #VE inserted to the guest and in a subsequent TDVMCALL to VMM. On such a call the VMM starts an LAPIC timer to emulate tsc deadline timer and inject a posted interrupt to the TDX guest when the timer expires.
Declaring insecurity to user space¶
Many of the security measures described in this document can be disabled with command line arguments, especially any kind of filtering. While such a configuration change is detected by attestation, there are use cases that don’t use full attestation and may continue running even if it fails.
For this purpose, a taint flag TAINT_CONF_NO_LOCKDOWN is set when any command line overrides for lockdowns are used. The user agent could check that by using /proc/sys/kernel/taint. Additionally, there are warnings printed to indicate whenever the device filter has been disabled, overridden over command line, etc.
The key server helps to ensure through attestation that the guest runs in secure mode. It does that by attesting the kernel command line, as well as the kernel binary. The kernel configuration should include module signing, which can be enforced by the command line as well as the binary.
BIOS-supplied ACPI tables and mappings¶
ACPI table mappings and similar table mappings use the ioremap_cache interface, which is never set to ‘shared’ with the untrusted host/VMM. However, in order to be able to share operating regions declared in ACPI tables a new interface ioremap_cache_shared is introduced. This interface sets the pages to shared and is currently only used by the acpi system memory address space handler (acpi_ex_system_memory_space_handler). Note that this means that any operating region declared in the allow list of TDX guest kernel ACPI tables is going to be set to ‘shared’ automatically. This further motivates keeping the allowed ACPI table list in TDX guest to a minimum required amount, and auditing the content of the allowed tables. Ideally it would be more secure to only share operating regions of drivers authorized by the device filter. However, since ACPI core doesn’t have a mapping between operating region addresses and the drivers that requested it, this change has been proven to be too intrusive.
ACPI tables are (mostly) controlled by the host and only passed through the TDVF (see TDX guest virtual firmware for more information). They are measured into TDX attestation registers, and therefore can be remotely attested and therefore can be considered trusted. However, we cannot expect that an attesting entity fully understands what causes the Linux kernel to open security holes based on some particular AML. Then a malicious hypervisor might be able to attack the guest based on attack surfaces exposed by the non-malicious and attested ACPI tables. The main concern here is the tables and methods that configure some functionality in the kernel, such as initializing drivers.
As a first step to minimize the above attack surface, the TDX guest kernel defines an allow list for the ACPI tables. Currently the list includes the following tables: XSDT, FACP, DSDT, FACS, APIC, and SVKL. However, it still includes large tables like DSDT that contain a lot of functionality. Ideally one would need to define a minimal set of methods that such table needs to support and then perform a code audit and fuzzing of these methods. All features that are not required (for example CPPC throttling) should be disabled to minimize the attack surface. This hardening activity has not been performed for the TDX guest and remains a future task. Alternatively, for a more generic hardening in-depth approach, the whole ACPI interpreter can be fuzzed and hardened, but this is a considerable effort and also is left for the future. For example, one possible future hardening is to add some range checking in ACPI to not write from AML to memory outside MMIO.
TDX guest private memory page management¶
All TDX guest private memory pages are allocated by the host and must be explicitly “accepted” into the guest using the TDG.MEM.PAGE.ACCEPT command. The TDX guest kernel needs to make sure that an already accepted page is not accepted again, because doing so would change the content of the guest private page to a zero page with possible security implications (zeroing out keys, secrets, etc.). Additionally, per current design of the TDX module, certain events (like TDX guest memory access to a non-accepted page) can result in a #VE event inserted by the TDX guest module. Please see section 16.3.3 in Intel TDX module architecture specification for more details. The guest kernel must always check the cause of a #VE event and panic if it sees a #VE event that is caused by access to a TDX guest private page. If this check is not implemented, it opens a TDX guest to many attacks against the content of the TDX guest private memory. For the Linux guest kernel specifically, it is also very important that such #VE notifications do not happen during certain TDX guest critical code paths. The section Safety against #VE in kernel code provides more details, as well as describes how Linux guest kernel avoids #VE events altogether.
TDVF conversion¶
Most of the initial memory for the TDX guest is converted by the TDVF and the TDX guest kernel can use all this memory through the normal UEFI memory map. However, due to performance implications, it is not possible to pre-accept all memory required for a guest to run, so the lazy memory accept logic described the next section is used.
Lazy conversion¶
To address the significant performance implications of pre-accepting all the pages, the pages will be accepted in runtime as required. Once VMM adds a private memory page to a TDX guest, its secure EPT entry resides in the PENDING state before the TDX guest explicitly accepts this page (secure EPT entry moves to PRESENT state) using the TDG.MEM.PAGE.ACCEPT instruction.
According to the Intel TDX module architecture specification, if the TDX guest attempts to accept the page that is already in the PRESENT state (essentially do a double accept by chance), then the TDX module has a way to detect this and supply a warning, so accepting an already accepted page is OK.
However, it is possible that that malicious host/VMM can execute the sequence of TDH.MEM.RANGE.BLOCK; TDH.MEM.TRACK; and TDH.MEM.PAGE.REMOVE calls on any present private page. Then it can quickly add it back with TDH.MEM.PAGE.AUG, and it goes into pending state. If the guest does not verify that it has previously accepted this page and accepts it again, it would end up using a zero page instead of data it previously had there. So, re-accept can happen if there is no TDX guest internal tracking of which pages have been previously accepted. For this purpose, the TDX guest kernel keeps track of already accepted pages in a 2MB granularity bitmap allocated in decompressor. In turn the page allocator accepts 2MB chunks as needed.
Safety against #VE in kernel code¶
The TDX guest Linux kernel needs to make sure it does not get #VE in certain critical sections. One example of such a section is a system call gap: on SYSCALL/SYSRET. There is a small instruction window where the kernel runs with the user stack pointer. If a #VE event (for example due to a malicious hypervisor removing a memory page as explained in the above section) happens in that window, it would allow a malicious userspace (ring 3) process in the guest to take over the guest kernel. As a result, it must be ensured that it is not possible to get a #VE event on the pages containing kernel code or data.
Such #VE events are currently possible in two cases:
TD guest accesses a private GPA for which the Secure EPT entry is in PENDING state and ATTRIBUTES.SEPT_VE_DISABLE TD guest attribute is not set.
TDX module can raise a #VE as a notification mechanism when it detects excessive Secure EPT violations raised by the same TD instruction (zero-step attack is detected by TDX module). This is only done if bit 0 of TDCS.NOTIFY_ENABLES field is set.
To ensure the above situations do not occur, the TD Linux guest kernel performs the following during kernel initialization:
Checks that ATTRIBUTES.SEPT_VE_DISABLE is set and panic otherwise.
Forcefully clear the TDCS.NOTIFY_ENABLES bit 0 regardless of its state.
Although the later check disables TDX module notifications for excessive numbers of Secure EPT violations, the basic defenses against zero-stepping provided by the TDX module are still in effect. For more details please see section 16.3 in Intel TDX module architecture specification
Reliable panic¶
In various situations when the TDX guest kernel detects a potential security problem, it needs to reliably stop. Standard panic performs many complex actions:
IPIs to other CPUs to stop them. This is not secure because the IPI is controlled by the host, which could choose not to execute them.
There can be notifiers to other drivers and subsystems which can do complex actions, including something that would cause the panic to wait for a host action.
As a result, it is not possible to guarantee that any other VCPU is reliably stopped with the standard panic and therefore a reliable panic is required. There is a potential path to make the panic more atomic (prevent reentry), but not fully atomic (due to TDX module limitations). This remains to be a direction for future work.
Kernel and initrd loading¶
In a simple reference configuration the TDVF loads the kernel, the initrd, and a startup script from an unencrypted UEFI VFAT volume in the guest storage area through virtio. The startup script contains the kernel command line. The kernel is booted through the Linux UEFI stub. Before booting the TDVF runs hashes over the kernel image/initrd/startup script and attest those to a key server through the TDX measurement registers.
Kernel command line¶
The kernel command line will allow to run an insecure kernel by disabling various security features or injecting unsafe code. However, we assume that the kernel command line is trusted, which is ensured by measuring its contents by the TDVF into TDX attestation registers.
The following command options are currently supported by TD guest kernel:
1. tdx_disable_filter. This option completely turns off the TDX device filter: guest kernel will allow loading of arbitrary device drivers in this mode. Additionally, a lot of explicitly disabled functionally (like pci quirks, enhanced pci capabilities, pci bridge support and others), will no longer be disabled and the respected unhardened linux guest code becomes reachable for the interaction with an untrusted host/VMM. For more detailed information on what functionality is guarded by the TDX device filter, see conditional checks cc_platform_has(CC_ATTR_GUEST_DEVICE_FILTER) in the kernel source code. Note that the port IO filter is also disabled in this mode. As a result, passing tdx_disable_filter option via TD guest command line enables a lot of unhardened code in the attack surface between an untrusted host/VMM and TDX Linux guest kernel. The remote attester must always verify that this option has not been used to start a TDX guest kernel via the TDX attestation quote.
2. authorize_allow_devs=. This option allows to specify a list of allowed devices in addition to the explicit list specified by TDX filter. However, this option is only intended for the debug purpose and should not be used in production since there is a high risk to enable devices this way that haven’t been hardened to withstand a potentially malicious host input. Instead, when a new device needs to be added to the TDX filter default allow list, the steps from Enabling additional kernel drivers must be followed.
3. tdx_allow_acpi=. This option allows passing additional allowed acpi tables to the default list specified in the TDX filter. Similarly, as the above option, it should be only used for the debug purpose. If an additional acpi table needs to be used in TDX guest, it should be included in the default TDX filter list after a security audit and risk assessment.
Additionally, to minimize the attack surface the following cmdline options are strongly recommended for TDX guests:
cmdline option |
Purpose |
|---|---|
mce=off |
Disables unneeded MCE/MCA subsystem, which hasn’t been hardened |
oops=panic |
Enables panic on oops, generic security mechanism to harden kernel |
pci=noearly |
Disables unneeded early pci subsystem, which hasn’t been hardened |
pci=nommconf |
Disables memory mapped pci config space, which hasn’t been used so far in TDX guests |
no-kvmclock |
Disables kvm-clock as untrusted time source |
random.trust_cpu=y |
Trusts architecture-provided DRNG (RDRAND/RDSEED on intel platforms) to provide enough entropy during early boot |
random.trust_bootloader=n |
Disables crediting entropy obtained from the bootloader via add_bootloader_randomness. |
Storage protection¶
The confidentiality and authenticity of the TD guest disk volume’s needs to be protected from the host/VMM that handles it. The exact protection method is decided by the TD tenant, but we provide a default reference setup. We use dmcrypt with LUKS with dm integrity to provide encryption and authentication for the storage volumes. To retrieve the decryption key during the TD boot process, the TD guest initrd contains an agent that performs the TD attestation to a remote key server. The attestation quote is going to contain the measurements from the TDVF, the boot loader, kernel, its command line, and initrd itself. The actual communication protocol between the remote key server and the initrd attestation agent will be customer (cloud) specific. The reference initrd attestation agent provided by Intel implements the Intel reference protocol. After the attestation succeeds, the initrd attestation agent obtains the key and it is used by the initrd to mount the TD guest file system.
Users could use other encryption schemes for storage, such as not using LUKS but some other encrypted storage format. Alternatively, they could also not use local storage and rely on a volume mounted from the network after attesting themselves to the network server. However, support for such remote storage is out of the scope for this document for now.
Note: Commonly used read/write Linux storage protection methods (including dmcrypt and dm integrity) do not provide rollback protection. If rollback attacks are a concern, the networking-based storage outside of attacker control is the recommended option. The absence of rollback protection also has implications on guest private memory rollback attacks if memory swapping to the filesystem is enabled in the guest kernel. Due to this limitation, we recomend disabling guest memory swap.
Transient Execution attacks and their mitigation¶
Software running inside a TDX Guest, including TDX Guest Linux kernel and enabled kernel drivers, needs to be aware which potential transient execution attacks are applicable and employ the appropriate mitigations when needed. More information on this can be found in Trusted Domain Security Guidance for Developers.
Bounds Check Bypass (Spectre V1)¶
Bounds Check Bypass is a class of transient execution attack (also known as Spectre V1), which typically requires an attacker who can control an offset used during a speculative read or write. For the classical attack surface between the userspace and the OS kernel (ring 3 <-> ring 0), an adversary has several ways to provide the necessary controlled inputs to the OS kernel, i.e., via system call parameters, routines to copy data between the userspace and the OS kernel, and others.
While a TDX guest VM is no different from a legacy guest VM in terms of protecting this userspace <-> OS kernel boundary, an adversary who controls the (untrusted) host/VMM can provide inputs to a TDX guest kernel via a wider range of interfaces. Examples of such interfaces include shared memory as well as the TDVMCALL-hypercall-based communication interfaces described above. A Linux kernel running inside a TDX guest should take additional measures to mitigate any potential Spectre v1 gadgets involving such interfaces.
To facilitate the task of identifying potential Spectre v1 gadgets in the new attack surface between an untrusted host/VMM <-> TDX guest Linux kernel, the Smatch static analyzer can be used. It has an existing check_spectre.c pattern that has been recently enhanced to find potential Spectre v1 gadgets on the data that can be influenced by an untrusted host/VMM using TDVMCALL-hypercall-based communication interfaces interfaces, such as MSR, CPUID, PortIO, MMIO and PCI config space read functions, as well as virtio-based shared memory read functions.
In order to configure the pattern to perform the Spectre v1 gadget analysis on the host data, the following environmental variable must be set prior to running the smatch analysis:
export ANALYZE_HOST_DATA=""
To revert to the original behavior of the pattern, i.e., identification of Spectre v1 gadgets from userspace-induced inputs, the same variable needs to be unset:
unset ANALYZE_HOST_DATA
For more information on how to setup smatch and use it to perform analysis of the linux kernel please refer to Smatch documentation .
The output of the smatch check_spectre.c pattern is a list of potential Spectre v1 gadgets applicable to the analyzed Linux kernel source code. When the pattern is run for the whole kernel source tree (using test_kernel.sh script and with ANALYZE_HOST_DATA variable set as above), it will produce warnings in smatch_warns.txt file that contains a list of potential Spectre v1 gadgets in the following format:
arch/x86/kernel/tsc_msr.c:191 cpu_khz_from_msr() warn: potential
spectre issue 'freq_desc->muldiv' [r]
arch/x86/kernel/tsc_msr.c:206 cpu_khz_from_msr() warn: potential
spectre issue 'freq_desc->freqs' [r]
arch/x86/kernel/tsc_msr.c:207 cpu_khz_from_msr() warn: possible
spectre second half. 'freq'
arch/x86/kernel/tsc_msr.c:210 cpu_khz_from_msr() warn: possible
spectre second half. 'freq'
Each reported item needs to be manually analyzed to determine if it is a potential Spectre v1 gadget or a false positive. To minimize the number of entries for manual analysis, the list in smatch_warns.txt should be filtered against a list of drivers that are allowed for the TDX guest kernel, since most of the potential reported Spectre v1 gadgets are going to be related to various x86 Linux kernel drivers. The process_smatch_output.py script can be used for doing the automatic filtering of the results, but its list of allowed drivers needs to be adjusted to reflect the TDX guest kernel under analysis. For the items that are determined to be potential Spectre v1 gadgets during the manual analysis phase, the recommended mitigations listed in Analyzing Potential Bounds Check Bypass Vulnerabilities should be followed.
Summary¶
The TDX guest kernel security architecture described in this document is a first step towards building a secure Linux guest kernel for confidential cloud computing (CCC). The security hardening techniques described in this document are not specific to the Intel TDX technology, but are applicable for any CCC technology that aims to help to remove the host/VMM from TCB. While some of the hardening approaches outlined above are still a work in progress or left for the future, it provides a solid foundation for continuing this work by both the industry and the Linux community.